spender-I-vf-0
收藏Hugging Face2026-01-28 更新2026-01-29 收录
下载链接:
https://huggingface.co/datasets/Birr001/spender-I-vf-0
下载链接
链接失效反馈官方服务:
资源简介:
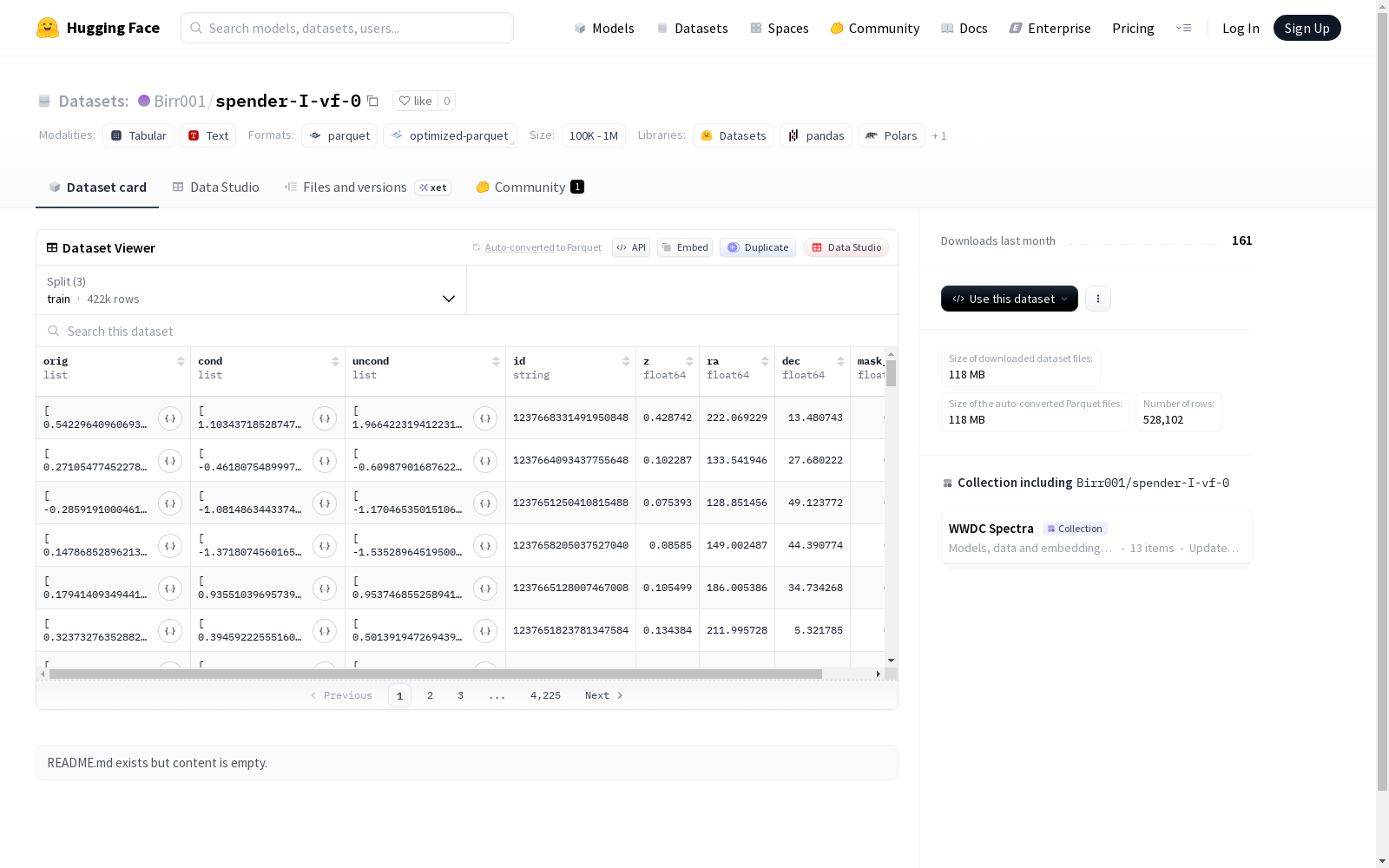
该数据集包含422,481个训练样本、52,811个测试样本和52,810个验证样本,总大小约162MB。数据特征包括:三维向量(orig/cond/uncond,均为float64列表)、唯一标识符(id,字符串类型)、以及四个浮点数值(z、ra、dec、mask_ratio)。数据集已预分割为train/test/val三部分,分别存储在data/路径下的对应文件中。未提供具体任务描述,但从特征结构推测可能涉及空间坐标或物理量建模。
This dataset contains 422,481 training samples, 52,811 test samples, and 52,810 validation samples, with an approximate total size of 162 MB. Its data features include 3-dimensional vectors (orig/cond/uncond, all stored as float64 lists), unique identifiers (id, of string type), and four floating-point values: z, ra, dec, and mask_ratio. This dataset has been pre-split into three subsets: train, test, and val, which are respectively stored in corresponding files under the data/ directory. No specific task description is provided, but based on the feature structure, it is inferred that the dataset may involve spatial coordinate or physical quantity modeling.
创建时间:
2026-01-19
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: spender-I-vf-0
- 发布者: Birr001
- 数据集地址: https://huggingface.co/datasets/Birr001/spender-I-vf-0
数据集结构与特征
数据字段
- orig: 列表类型,元素为float64
- cond: 列表类型,元素为float64
- uncond: 列表类型,元素为float64
- id: 字符串类型
- z: float64类型
- ra: float64类型
- dec: float64类型
- mask_ratio: float64类型
数据划分
- 训练集 (train)
- 样本数量: 422,481
- 数据大小: 129,647,650 字节
- 测试集 (test)
- 样本数量: 52,811
- 数据大小: 16,206,422 字节
- 验证集 (val)
- 样本数量: 52,810
- 数据大小: 16,205,963 字节
数据集存储信息
- 总数据集大小: 162,060,035 字节
- 下载大小: 117,801,344 字节
数据文件配置
- 配置名称: default
- 数据文件路径:
- 训练集:
data/train-* - 测试集:
data/test-* - 验证集:
data/val-*
- 训练集:
搜集汇总
数据集介绍
构建方式
在宇宙学与天体物理领域,高维数据的表征学习对理解星系演化至关重要。spender-I-vf-0数据集通过系统采集大量星系观测数据构建而成,其原始观测信号经预处理后,以特征向量的形式存储,涵盖了原始观测值、条件化特征及无条件特征等多维信息。数据划分遵循机器学习标准流程,分为训练集、验证集与测试集,确保了模型评估的严谨性。
特点
该数据集以其丰富的天体物理参数为显著特点,不仅包含星系的位置坐标(赤经、赤纬)与红移信息,还整合了掩蔽比例等关键指标,为研究星系形态与分布提供了多角度视角。数据以浮点数列表和字符串标识符的结构化格式呈现,便于高效存取与计算,其大规模样本量确保了统计分析的可靠性,适用于深度学习模型的训练与验证。
使用方法
针对机器学习任务,用户可直接加载数据集的标准化分割,利用原始特征与条件特征进行监督或自监督学习,例如生成模型或分类任务的训练。数据中的掩蔽比例可用于模拟不完整观测场景,增强模型鲁棒性。建议先进行数据归一化处理,再结合红移等参数开展跨领域的天体物理分析,以挖掘星系的潜在规律。
背景与挑战
背景概述
在宇宙学与天体物理领域,高维光谱数据的分析与建模一直是揭示星系形成与演化机制的核心课题。spender-I-vf-0数据集由相关研究团队于近期构建,旨在为光谱重建与生成任务提供结构化支持。该数据集整合了原始光谱、条件信号及无条件信号等多模态特征,并辅以天体坐标、掩蔽比例等元数据,为深度学习模型在光谱去噪、补全及合成方面的研究奠定了数据基础。其设计体现了对天文大数据中复杂信号处理的深入考量,有望推动自动光谱分析技术在大型巡天项目中的应用。
当前挑战
该数据集致力于应对天文光谱处理中的关键挑战,即如何在强噪声、部分缺失或低信噪比条件下,实现高保真度的光谱重建与生成。具体而言,构建过程面临诸多困难:原始观测数据常受仪器误差与天空背景干扰,需经过复杂的校准与归一化流程;而条件与无条件信号的配对标注要求精确的物理模型推导,增加了数据准备的复杂度。此外,光谱的高维特性与稀疏性使得特征表示与压缩成为难点,需平衡计算效率与信息完整性。
常用场景
经典使用场景
在宇宙学与天体物理学领域,spender-I-vf-0数据集为光谱分析研究提供了关键支持。该数据集通过包含原始光谱、条件光谱及无条件光谱等特征,为研究者构建了一个全面的光谱数据环境。其经典使用场景聚焦于训练和评估光谱重建与去噪模型,尤其在处理高红移天体或低信噪比观测数据时,能够有效模拟真实观测条件,帮助模型学习从噪声或缺失数据中恢复完整光谱结构。
衍生相关工作
围绕该数据集,已衍生出一系列经典研究工作,特别是在自监督学习与生成模型领域。例如,基于其构建的变分自编码器(VAE)和扩散模型被用于光谱合成与增强,生成高质量模拟光谱以扩充训练样本。此外,结合注意力机制的序列模型利用其条件与无条件光谱对,实现了光谱分类与红移估计的精度提升,这些工作显著推动了机器学习与天体物理的交叉学科发展。
数据集最近研究
最新研究方向
在宇宙学与天体物理领域,spender-I-vf-0数据集凭借其包含的原始光谱、条件及无条件特征,正推动着生成式模型在天文数据增强与模拟方面的前沿探索。该数据集整合了红移、坐标及掩码比例等关键参数,为研究宇宙大尺度结构形成与星系演化提供了高维度的多模态信息基础。当前热点聚焦于利用扩散模型或变分自编码器,从条件特征中生成逼真的星系光谱,以弥补观测数据的稀疏性,并支持暗能量巡天等大型项目的模拟需求。这一方向不仅提升了天文数据的合成质量,还助力于宇宙学参数的精确推断,对理解暗物质与暗能量的本质具有深远意义。
以上内容由遇见数据集搜集并总结生成


