it4lia/EMBER_cleaned
收藏Hugging Face2026-04-02 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/it4lia/EMBER_cleaned
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
license: mit
pretty_name: EMBER Cleaned
task_categories:
- tabular-classification
tags:
- cybersecurity
- malware
- static-analysis
- pe-files
- malware-detection
- benchmark
- tabular
- ai-ready
- clustering
size_categories:
- 1M<n<10M
---
# EMBER Cleaned
EMBER Cleaned is a cleaned and AI-ready version of the original **EMBER (Endgame Malware Benchmark for Research)** dataset, a widely used benchmark for static malware detection on Windows Portable Executable (PE) files.
The original EMBER dataset was introduced by Endgame / Elastic as an open benchmark for machine-learning-based malware detection using only **static PE-derived features**, without executing binaries. This cleaned release preserves that purpose while making the dataset easier to load, more reproducible, and more directly usable for downstream experimentation.
Compared with the original source asset, this release standardizes metadata, removes duplicate samples, drops constant features, and exports unlabeled samples into a dedicated split for semi-supervised workflows. Each sample is represented as a fixed-length numerical vector derived from PE structure and content, including header information, section statistics, imports, and histogram-based features.
## Original dataset
This dataset is a cleaned derivative of the original EMBER benchmark:
- **Original name:** EMBER (Endgame Malware Benchmark for Research)
- **Original provider:** Endgame / Elastic
- **Original paper:** Anderson, H. S., & Roth, P. (2018). *EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models*
- **Original DOI:** https://doi.org/10.48550/arXiv.1804.04637
- **Original project/repository:** https://github.com/elastic/ember
Please cite the original EMBER paper when using this cleaned release in research.
## Files
| File | Description |
|---|---|
| `ember_clean.npz` | Index file with row/feature counts and file references |
| `ember_clean_X.npy` | Feature matrix (`float32`), raw memmap, shape `(799838, 2099)` |
| `ember_clean_y.npy` | Label vector (`int32`), `0 = benign`, `1 = malware` |
| `ember_clean_metadata.parquet` | Per-sample metadata: SHA-256, timestamps, malware-related fields when available, quality flags |
| `ember_unlabeled.npz` | Index file for unlabeled split |
| `ember_unlabeled_X.npy` | Unlabeled feature matrix with the same 2,099 features |
| `ember_unlabeled_y.npy` | Label marker array (`int32`) for the unlabeled split; expected to contain only `-1` values |
| `ember_clean_metadata_unlabeled.parquet` | Metadata for unlabeled samples |
| `manifest.json` | Versioned manifest with checksums and artifact references |
| `ember_cleaned_dataset.ipynb` | Exploration and usage notebook |
## What’s in the dataset?
This cleaned release contains the **labeled portion** of EMBER plus a **separate unlabeled split**.
### Labeled split
- **799,838 labeled samples**
- approximately balanced between benign and malicious files
- **2,099 numerical features**
- feature dtype: `float32`
- label dtype: `int32`
- labels:
- `0` = benign
- `1` = malware
### Unlabeled split
- **199,966 unlabeled samples**
- exported separately for semi-supervised workflows
- same 2,099-dimensional feature space
- not intended to be interpreted as benign or malicious ground truth
### Feature representation
Samples are not raw executables. Each file is represented as a **fixed-length static feature vector** extracted from the original PE file. These features describe structural and statistical properties of the binary, such as:
- PE headers
- imported APIs / libraries
- sections
- byte-histogram-related information
- entropy-related characteristics
## Cleaning summary
This release is the output of a quality-control and standardization pipeline applied to the original EMBER artifacts.
Main processing steps:
1. **Duplicate removal** using feature fingerprints
2. **Constant-feature filtering**, reducing the feature space from 2,381 to **2,099**
3. **Metadata standardization**
4. **Missing-value normalization and quality flagging**
5. **Label separation**, exporting `label = -1` samples into a dedicated unlabeled split
6. **Manifest generation** for reproducibility and integrity checks
Summary of the main changes:
- **196 duplicate samples removed**
- **282 constant features dropped**
- **199,966 unlabeled samples exported separately**
- final labeled dataset shape: **799,838 × 2,099**
## File structure
```text
EMBER_cleaned/
├── ember_clean.npz
├── ember_clean_X.npy
├── ember_clean_y.npy
├── ember_clean_metadata.parquet
├── ember_unlabeled.npz
├── ember_unlabeled_X.npy
├── ember_unlabeled_y.npy
├── ember_clean_metadata_unlabeled.parquet
└── manifest.json
```
The .npz index stores _rows and _features for reliable loading.
The feature matrices are raw memmap-backed arrays and should be loaded with explicit dtype and shape.
## Requirements
To run the quickstart examples, install the minimum required dependencies:
```bash
pip install numpy pandas pyarrow
```
For notebook-based exploration and basic visualization, you may also install:
```bash
pip install jupyter matplotlib seaborn scikit-learn
```
## Quickstart
This example loads the labeled EMBER Cleaned split and checks that features, labels, and metadata are consistent and ready for supervised use.
```python
import numpy as np
import pandas as pd
idx = np.load("ember_clean.npz", allow_pickle=True)
n_rows = int(idx["_rows"])
n_features = int(idx["_features"])
X = np.fromfile("ember_clean_X.npy", dtype=np.float32).reshape(n_rows, n_features)
y = np.load("ember_clean_y.npy")
meta = pd.read_parquet("ember_clean_metadata.parquet")
print(f"Dataset: {X.shape[0]} samples, {X.shape[1]} features | " f"labels: {y.shape[0]} | " f"metadata columns: {meta.shape[1]}")
assert X.shape[0] == len(y) == len(meta)
assert set(np.unique(y)) == {0, 1}
print("Unique labels:", np.unique(y))
print("Labeled Metadata Columns:", meta.columns.tolist())
print("All checks passed.")
```
The following example loads the unlabeled EMBER Cleaned split and checks that features and metadata are aligned for semi-supervised or exploratory use.
```python
import numpy as np
import pandas as pd
idx_u = np.load("ember_unlabeled.npz", allow_pickle=True)
n_rows_u = int(idx_u["_rows"])
n_features_u = int(idx_u["_features"])
X_u = np.fromfile("ember_unlabeled_X.npy", dtype=np.float32)
assert X_u.size == n_rows_u * n_features_u, (
f"Unexpected X_u size: got {X_u.size}, expected {n_rows_u * n_features_u}"
)
X_u = X_u.reshape(n_rows_u, n_features_u)
meta_u = pd.read_parquet("ember_clean_metadata_unlabeled.parquet")
print(f"Dataset: {X_u.shape[0]} samples, {X_u.shape[1]} features | " f" unlabeled split: {n_rows_u} samples | " f"metadata columns: {meta_u.shape[1]}")
assert X_u.shape == (n_rows_u, n_features_u)
assert len(meta_u) == n_rows_u
if "label_int" in meta_u.columns:
print("Unlabeled metadata labels:", np.unique(meta_u["label_int"]))
assert set(np.unique(meta_u["label_int"])) == {-1}
print("Unlabeled metadata columns:", meta_u.columns.tolist())
print("Unlabeled split loaded successfully.")
```
## Notebook
The repository also includes an exploration notebook in `.ipynb` format, designed to provide additional context on the cleaned dataset, its structure, and its main analytical use cases.
The notebook can be used to:
- inspect the labeled and unlabeled splits
- explore metadata fields and label distributions
- validate dataset consistency
- review example analyses and downstream use cases
To open it locally, run:
```bash
jupyter notebook ember_cleaned_dataset.ipynb
```
or, if you use JupyterLab:
```bash
jupyter lab ember_cleaned_dataset.ipynb
```
Make sure to open the notebook from the dataset root directory so that relative file paths resolve correctly.
## Typical use cases
EMBER Cleaned supports:
- binary malware detection
- benchmarking of tabular ML pipelines
- feature importance analysis
- semi-supervised learning using the separate unlabeled split
- exploratory data analysis
- representation learning and clustering
The accompanying notebook includes dataset loading, exploratory analysis, and example use cases focused on discriminative features and model evaluation.
## Notes and limitations
This is a static-analysis dataset only.
The cleaned release contains derived features, not raw PE binaries.
The unlabeled split should not be treated as ground truth.
Results on EMBER should not be over-generalized to modern malware without additional validation.
The dataset is intended for defensive research, benchmarking, and education.
## License
This cleaned release is derived from EMBER. The original EMBER data files are associated with the MIT License. Please verify that your downstream redistribution and reuse remain aligned with the original EMBER terms.
## References
If you use this dataset, please cite the original EMBER paper:
@article{anderson2018ember,
title={EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models},
author={Anderson, Hyrum S. and Roth, Phil},
journal={arXiv preprint arXiv:1804.04637},
year={2018}
}
## APA:
Anderson, H. S., & Roth, P. (2018). EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models. arXiv. https://doi.org/10.48550/arXiv.1804.04637
## Contacts
Shared by: ACN
language:
- en
license: mit
pretty_name: EMBER Cleaned
task_categories:
- tabular-classification
tags:
- cybersecurity
- malware
- static-analysis
- pe-files
- malware-detection
- benchmark
- tabular
- ai-ready
- clustering
size_categories:
- 1M<n<10M
---
# EMBER Cleaned数据集
EMBER Cleaned 是原始**EMBER(Endgame Malware Benchmark for Research,研究用恶意软件基准数据集)**数据集的净化版且适配AI的版本,该数据集是针对Windows可移植可执行(Portable Executable,PE)文件开展静态恶意软件检测的广泛使用的基准数据集。
原始EMBER数据集由Endgame/Elastic推出,是一款仅使用**静态PE衍生特征**且无需执行二进制文件的、基于机器学习的恶意软件检测开源基准。本次净化版保留了该核心目标,同时优化了数据集的加载便捷性、可复现性,使其更可直接用于下游实验研究。
相较于原始源数据集,本次净化版实现了元数据标准化,移除了重复样本,剔除了恒定特征,并将未标记样本导出至专属划分集以支持半监督工作流。每个样本均表示为源自PE文件结构与内容的定长数值向量,涵盖头部信息、节区统计量、导入表信息以及基于直方图的特征。
## 原始数据集
本数据集是原始EMBER基准的净化衍生版本:
- **原始名称**:EMBER(Endgame Malware Benchmark for Research,研究用恶意软件基准数据集)
- **原始提供方**:Endgame/Elastic
- **原始文献**:Anderson, H. S. 与 Roth, P. (2018). *EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models*
- **原始DOI**:https://doi.org/10.48550/arXiv.1804.04637
- **原始项目/仓库**:https://github.com/elastic/ember
若在研究中使用本净化版数据集,请引用原始EMBER文献。
## 文件说明
| 文件名称 | 描述 |
|---|---|
| `ember_clean.npz` | 存储行/特征数量与文件引用的索引文件 |
| `ember_clean_X.npy` | 特征矩阵(`float32`类型),原生内存映射(memmap)格式,形状为`(799838, 2099)` |
| `ember_clean_y.npy` | 标签向量(`int32`类型),`0`表示良性软件,`1`表示恶意软件 |
| `ember_clean_metadata.parquet` | 单样本元数据:包含SHA-256哈希、时间戳、可用的恶意软件相关字段与质量标记 |
| `ember_unlabeled.npz` | 未标记划分集的索引文件 |
| `ember_unlabeled_X.npy` | 未标记特征矩阵,包含与标记集一致的2099个特征 |
| `ember_unlabeled_y.npy` | 未标记划分集的标签标记数组(`int32`类型),预期仅包含`-1`值 |
| `ember_clean_metadata_unlabeled.parquet` | 未标记样本的元数据 |
| `manifest.json` | 包含校验和与制品引用的版本化清单文件 |
| `ember_cleaned_dataset.ipynb` | 数据集探索与使用指南笔记本 |
## 数据集内容
本净化版数据集包含EMBER的**标记部分**与**独立的未标记划分集**。
### 标记划分集
- **799,838个标记样本**
- 良性与恶意样本数量近似均衡
- **2099个数值型特征**
- 特征数据类型:`float32`
- 标签数据类型:`int32`
- 标签定义:
- `0` = 良性软件
- `1` = 恶意软件
### 未标记划分集
- **199,966个未标记样本**
- 单独导出以支持半监督工作流
- 特征空间维度与标记集一致,为2099维
- 不可将其视为良性/恶意的真实标签
### 特征表示形式
本数据集并非原始可执行文件,每个文件均表示为从原始PE文件中提取的**定长静态特征向量**。此类特征描述了二进制文件的结构与统计特性,例如:
- PE头部信息
- 导入的应用程序编程接口(API,Application Programming Interface)与库
- PE节区
- 字节直方图相关信息
- 熵相关特征
## 净化流程说明
本净化版是对原始EMBER数据集制品执行质量控制与标准化流程后的产物。
主要处理步骤:
1. **重复样本移除**:基于特征指纹识别并移除重复样本
2. **恒定特征过滤**:将特征空间从2381维缩减至**2099维**
3. **元数据标准化**:统一元数据格式与字段
4. **缺失值归一化与质量标记**:处理缺失值并添加质量标记
5. **标签分离**:将`label = -1`的样本导出至专属未标记划分集
6. **生成校验清单**:用于保障可复现性与完整性校验
主要变更汇总:
- **移除196个重复样本**
- **剔除282个恒定特征**
- **单独导出199,966个未标记样本**
- 最终标记数据集形状:**799,838 × 2,099**
## 文件目录结构
text
EMBER_cleaned/
├── ember_clean.npz
├── ember_clean_X.npy
├── ember_clean_y.npy
├── ember_clean_metadata.parquet
├── ember_unlabeled.npz
├── ember_unlabeled_X.npy
├── ember_unlabeled_y.npy
├── ember_clean_metadata_unlabeled.parquet
└── manifest.json
其中.npz索引文件存储了`_rows`与`_features`信息,以确保可靠加载。特征矩阵为原生内存映射(memmap)数组,加载时需显式指定数据类型与形状。
## 依赖要求
若需运行快速入门示例,请安装最低依赖:
bash
pip install numpy pandas pyarrow
若需基于Jupyter笔记本开展探索与基础可视化,还可安装:
bash
pip install jupyter matplotlib seaborn scikit-learn
## 快速入门
本示例将加载标记版EMBER Cleaned数据集,并验证特征、标签与元数据的一致性,确保其可用于监督学习任务。
python
import numpy as np
import pandas as pd
idx = np.load("ember_clean.npz", allow_pickle=True)
n_rows = int(idx["_rows"])
n_features = int(idx["_features"])
X = np.fromfile("ember_clean_X.npy", dtype=np.float32).reshape(n_rows, n_features)
y = np.load("ember_clean_y.npy")
meta = pd.read_parquet("ember_clean_metadata.parquet")
print(f"Dataset: {X.shape[0]} samples, {X.shape[1]} features | " f"labels: {y.shape[0]} | " f"metadata columns: {meta.shape[1]}")
assert X.shape[0] == len(y) == len(meta)
assert set(np.unique(y)) == {0, 1}
print("Unique labels:", np.unique(y))
print("Labeled Metadata Columns:", meta.columns.tolist())
print("All checks passed.")
以下示例将加载未标记版EMBER Cleaned数据集,并验证特征与元数据的对齐性,以支持半监督或探索性任务。
python
import numpy as np
import pandas as pd
idx_u = np.load("ember_unlabeled.npz", allow_pickle=True)
n_rows_u = int(idx_u["_rows"])
n_features_u = int(idx_u["_features"])
X_u = np.fromfile("ember_unlabeled_X.npy", dtype=np.float32)
assert X_u.size == n_rows_u * n_features_u, (
f"Unexpected X_u size: got {X_u.size}, expected {n_rows_u * n_features_u}"
)
X_u = X_u.reshape(n_rows_u, n_features_u)
meta_u = pd.read_parquet("ember_clean_metadata_unlabeled.parquet")
print(f"Dataset: {X_u.shape[0]} samples, {X_u.shape[1]} features | " f" unlabeled split: {n_rows_u} samples | " f"metadata columns: {meta_u.shape[1]}")
assert X_u.shape == (n_rows_u, n_features_u)
assert len(meta_u) == n_rows_u
if "label_int" in meta_u.columns:
print("Unlabeled metadata labels:", np.unique(meta_u["label_int"]))
assert set(np.unique(meta_u["label_int"])) == {-1}
print("Unlabeled metadata columns:", meta_u.columns.tolist())
print("Unlabeled split loaded successfully.")
## Jupyter笔记本
本仓库附带了`.ipynb`格式的探索笔记本,旨在提供净化版数据集的额外背景信息、结构说明与主要分析用例。该笔记本可用于:
- 查看标记与未标记划分集
- 探索元数据字段与标签分布
- 验证数据集一致性
- 查看示例分析与下游用例
若需本地打开该笔记本,请运行:
bash
jupyter notebook ember_cleaned_dataset.ipynb
或使用JupyterLab时运行:
bash
jupyter lab ember_cleaned_dataset.ipynb
请确保从数据集根目录打开笔记本,以确保相对文件路径正确解析。
## 典型应用场景
EMBER Cleaned 支持以下任务:
- 二元恶意软件检测
- 表格型机器学习流水线基准测试
- 特征重要性分析
- 基于独立未标记划分集的半监督学习
- 探索性数据分析
- 表征学习与聚类
附带的笔记本包含数据集加载、探索性分析以及针对判别特征与模型评估的示例用例。
## 注意事项与局限性
本数据集仅支持静态分析任务。
本净化版数据集包含衍生特征,而非原始PE二进制文件。
未标记划分集不可视为真实标签。
若未经过额外验证,基于EMBER的研究结果不可泛化至现代恶意软件场景。
本数据集仅用于防御性研究、基准测试与教育用途。
## 许可证
本净化版数据集源自EMBER。原始EMBER数据文件采用MIT许可证。请确保您的下游再分发与复用符合原始EMBER的许可证条款。
## 引用说明
若使用本数据集,请引用原始EMBER文献:
bibtex
@article{anderson2018ember,
title={EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models},
author={Anderson, Hyrum S. and Roth, Phil},
journal={arXiv preprint arXiv:1804.04637},
year={2018}
}
## APA格式引用:
Anderson, H. S., & Roth, P. (2018). EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models. arXiv. https://doi.org/10.48550/arXiv.1804.04637
## 联系方式
共享方:ACN
提供机构:
it4lia
搜集汇总
数据集介绍
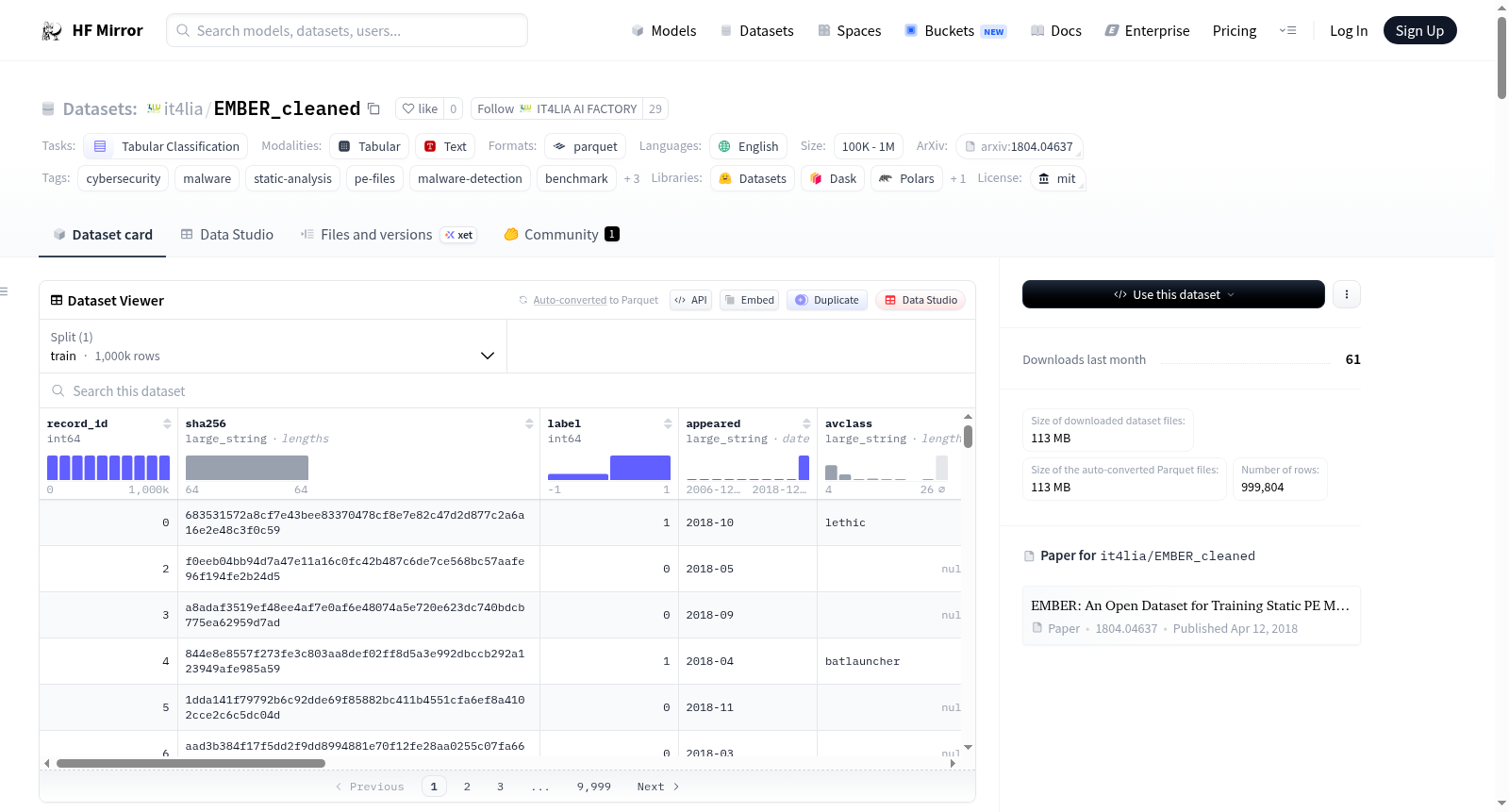
构建方式
在网络安全领域,静态恶意软件检测研究依赖于高质量的特征数据集。EMBER_cleaned数据集基于原始EMBER基准构建,通过一系列标准化与清洗流程优化了数据质量。该流程包括基于特征指纹的重复样本剔除、恒定特征过滤将特征维度从2381降至2099、元数据标准化处理、缺失值归一化与质量标记,以及将未标记样本分离为独立子集。最终形成了包含799,838个标记样本的标注数据集和199,966个未标记样本的子集,所有样本均以固定长度的数值向量表示,确保了数据的可复现性与机器学习就绪状态。
特点
该数据集作为静态恶意软件检测领域的重要资源,具备若干显著特性。样本特征源自Windows可移植可执行文件的结构与内容,涵盖头部信息、节区统计、导入函数及基于直方图的特征,形成2099维的数值向量表示。数据集提供了近乎平衡的良性文件与恶意软件标注,并专门分离出未标记样本子集以支持半监督学习工作流。此外,配套的标准化元数据文件包含SHA-256哈希、时间戳及质量标志等信息,增强了数据的可追溯性与分析深度。
使用方法
为支持恶意软件检测模型的开发与评估,该数据集提供了清晰的使用路径。用户可通过加载索引文件获取样本与特征维度信息,利用内存映射方式读取特征矩阵与标签向量,并结合Parquet格式的元数据进行综合分析。数据集适用于监督学习中的二进制分类任务,未标记子集可用于半监督学习或表示学习研究。配套的探索性笔记本进一步提供了数据分布可视化、特征重要性分析与模型评估示例,为研究者构建端到端的检测流程提供了实践指导。
背景与挑战
背景概述
在网络安全领域,恶意软件检测一直是防御体系中的核心环节。EMBER(Endgame Malware Benchmark for Research)数据集由Endgame/Elastic团队于2018年推出,旨在为基于机器学习的静态恶意软件检测提供一个开放基准。该数据集专注于Windows便携式可执行(PE)文件,通过提取静态特征向量,如头部信息、导入函数和字节直方图统计,避免了动态执行二进制文件带来的风险。其发布显著推动了恶意软件检测领域的研究,促进了机器学习模型在安全分析中的应用,成为该领域广泛引用的标准资源。
当前挑战
EMBER数据集致力于解决静态恶意软件检测中的核心挑战,即如何仅通过二进制文件的结构特征准确区分恶意与良性样本,这要求模型能够从高维特征中捕捉细微的恶意模式。在构建过程中,数据集面临多重挑战:原始数据包含重复样本和恒定特征,需通过去重和特征筛选确保数据质量;同时,处理大量未标记样本并分离为独立分割,以支持半监督学习流程,增加了数据标准化的复杂性。这些挑战要求精细的数据清洗和结构化处理,以提升数据集的可靠性和可用性。
常用场景
经典使用场景
在网络安全领域,静态恶意软件检测是防御体系的关键环节,EMBER_cleaned数据集为此提供了标准化的基准。该数据集最经典的使用场景在于训练和评估基于机器学习的恶意软件分类模型,研究人员利用其包含的约80万条标注样本和2099维静态特征向量,构建高效的二分类检测系统。这些特征源自Windows可执行文件的PE结构,如头部信息、导入函数和字节直方图,无需实际执行二进制文件即可实现快速分析,极大地推动了静态检测方法的发展与比较。
解决学术问题
EMBER_cleaned数据集有效解决了恶意软件检测研究中数据标准化与可复现性的核心难题。传统研究中,特征提取不一致和样本重复往往导致结果偏差,该数据集通过去除重复样本、过滤恒定特征并分离未标注数据,提供了清晰、一致的实验基础。其意义在于为学术界建立了一个可靠的基准平台,使得不同机器学习算法能够在公平环境下进行性能对比,从而加速新方法的验证与迭代,对提升检测模型的泛化能力与鲁棒性产生了深远影响。
衍生相关工作
基于EMBER_cleaned数据集,衍生出多项经典研究工作,推动了恶意软件检测领域的创新。例如,研究者利用其特征空间开发了基于深度神经网络的检测框架,如卷积神经网络与自编码器的结合应用,提升了特征自动提取的精度。同时,该数据集也促进了对抗性机器学习在安全领域的研究,学者通过生成对抗样本测试模型鲁棒性。此外,许多开源工具和基准测试套件将其作为核心数据源,进一步扩展了在聚类分析和表示学习等方面的探索。
以上内容由遇见数据集搜集并总结生成


