aliaagheis/android-control
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/aliaagheis/android-control
下载链接
链接失效反馈官方服务:
资源简介:
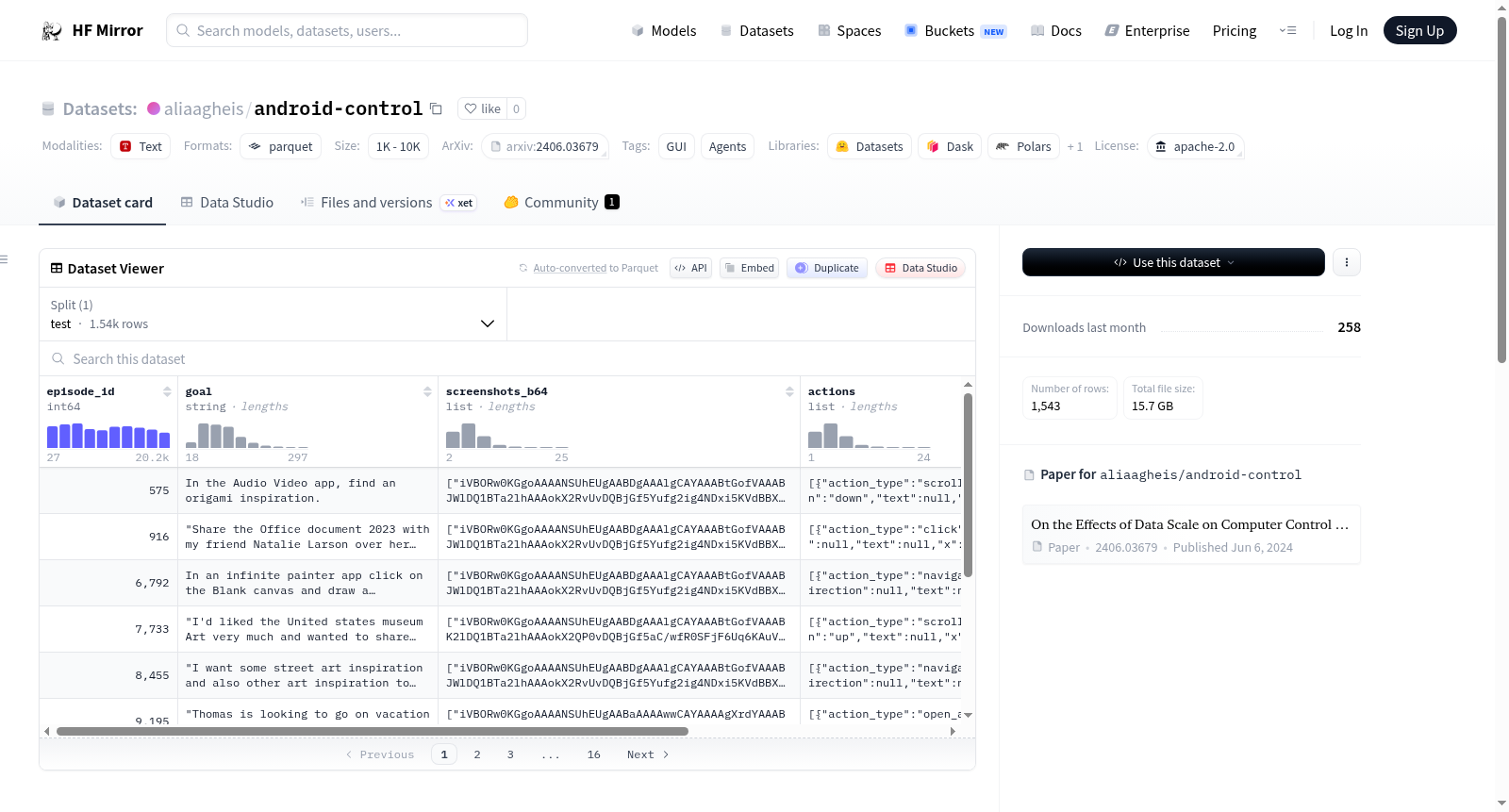
Android Control Test Set是一个用于GUI和Agents研究的数据集,主要用于评估目的。数据集包含小的parquet文件用于样本下载和探索,以及一个大的zip文件便于在Kaggle或Colab等平台上进行整体评估。README中提到,大多数模型不会在测试集上进行训练。数据集来源于smolagents/android-control,并通过过滤ids来确保只包含真实的测试集。
The Android Control Test Set is a dataset for GUI and Agents research, primarily intended for evaluation purposes. The dataset includes small parquet files for downloading samples and exploration, as well as a large zip file for convenient evaluation on platforms like Kaggle or Colab. The README notes that most models are assumed not to train on the test set. The dataset is sourced from smolagents/android-control, with filtered ids to ensure it contains only the real test set.
提供机构:
aliaagheis
搜集汇总
数据集介绍
构建方式
Android Control数据集源自Google Research发布的Android控制任务,其构建基于对原始数据源中分割信息的精准提取。数据集的创建者通过访问Google Cloud Storage中的`splits.json`文件,利用`smolagents`工具遍历并筛选出仅属于测试集的`episode_id`,从而确保了数据划分的纯洁性与评估的公正性。该过程避免了与上游数据集中训练集或验证集样本的混淆,为后续模型性能的客观度量奠定了坚实的数据基础。
特点
该数据集的核心特色在于其专为评估而非训练设计的定位。它包含了完整的GUI交互任务样本,以小巧的Parquet文件便于局部探索,同时提供了一个巨大的压缩包文件,便于用户在Kaggle或Colab等云端环境中完整加载。数据集中每个样本均包含可视界面与动作序列,是测试计算机控制代理程序在多步骤任务中规划与执行能力的理想基准。
使用方法
开发者可通过HuggingFace平台直接加载或下载该数据集。对于局部探索,建议使用小Parquet文件快速查看数据结构;若要运行完整评估,推荐下载整个ZIP压缩文件。在代码中,可利用`datasets`库或`smolagents`工具读取样本,将GUI状态与动作标签对用于代理程序的推理与决策测试。需注意,该数据集未经训练集污染,适合作为研究论文中的标准测试基准。
背景与挑战
背景概述
在移动智能体研究领域,图形用户界面(GUI)交互是实现自动化任务执行的核心技术路径。Android Control Test Set由William Bishop等研究人员于2024年创建,源自Google Research与多机构合作的前沿成果,旨在评估计算机控制智能体在真实Android环境中的操作能力。该数据集聚焦于跨应用导航、表单填写等复杂GUI任务,通过精细划分的测试集为智能体泛化性能提供标准化基准。其发布显著推动了GUI智能体领域的可复现研究,相关论文《On the Effects of Data Scale on Computer Control Agents》系统探讨了数据规模对智能体效能的影响,使得该数据集成为评估GUI智能体鲁棒性的关键工具。
当前挑战
该数据集面临的核心挑战包括:第一,解决GUI智能体领域长期存在的环境泛化难题——现有模型往往过度拟合训练集中的界面布局,难以适应真实设备中千变万化的屏幕分辨率和控件排列;第二,训练数据与测试集的数据泄露风险,上传者特别强调测试集应仅用于评估,但部分模型可能意外接触到测试样本的元信息,导致性能虚高;第三,构建过程中需对齐Google Research主存储库中的隔离划分方案,确保episode_id与官方分割文件完全匹配,避免因数据源不一致引入评测偏差。
常用场景
经典使用场景
Android Control Test Set 作为智能体(Agent)在移动图形用户界面(GUI)领域中的标杆性评估数据集,专为衡量计算机控制代理在真实安卓设备上的操作能力而设计。其经典使用场景聚焦于指令跟随与界面交互任务:模型需基于自然语言描述的操作目标(如“打开设置并调整亮度”),在给定屏幕截图和UI树结构的环境下,自主规划并执行点击、滑动、输入等原子动作。该测试集依任务难度与操作步骤数划分样本,遵循“训练集/验证集/测试集”分离原则,确保评估的公平性与泛化性。通过在此数据集上进行零样本或少样本评估,研究者可系统量化智能体在多模态感知(视觉+文本+结构化信息)联合推理时的鲁棒性,是当前移动端GUI自动化研究中不可或缺的度量基准。
解决学术问题
该数据集精准回应了学术界在计算机控制代理领域长期面临的两大核心挑战:数据稀疏性与跨任务泛化能力评估。早期研究受限于私有仿真环境或有限领域指令,难以在统一标准下复现与对比模型性能。Android Control Test Set 通过提供覆盖系统设置、多步应用操作、异常恢复等多样化任务的标准化测试样本,使学者得以脱离特定数据收集偏见,系统研究“模型规模化对GUI操作能力的影响”(Li et al., 2024)。其发布实质推动了从“意图理解”到“步骤执行”的端到端能力量化,并催生了关于动作空间表示、错误恢复机制与长程任务分解等关键学术议题的深入探讨,为构建具有自主规划能力的通用移动代理奠定了实证基础。
衍生相关工作
自发布以来,Android Control Test Set 已催生出一系列代表性研究工作。在模型架构层面,研究者基于其测试划分提出了多模态指令跟随框架(如像素级决策Transformer与分层动作编译器),通过融合视觉特征与UI树结构优化动作定位精度。在训练策略上,Li等人(2024)利用不同规模的数据子集系统论证了“数据规模递增所带来的few-shot能力涌现现象”,为后续大规模RLHF(人类反馈强化学习)训练提供理论依据。评估协议方面,社区开发了统一的自动化分类器以判定动作序列与中间状态的正确性,衍生出诸如“步骤一致性得分”等新指标。此外,该测试集被集成进多个开源智能体基准库(如smolagents),使得跨论文的直接性能对比成为可能,显著加速了GUI自主代理领域的实证研究循环。
以上内容由遇见数据集搜集并总结生成


