il_calderone
收藏Hugging Face2024-11-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/swap-uniba/il_calderone
下载链接
链接失效反馈官方服务:
资源简介:
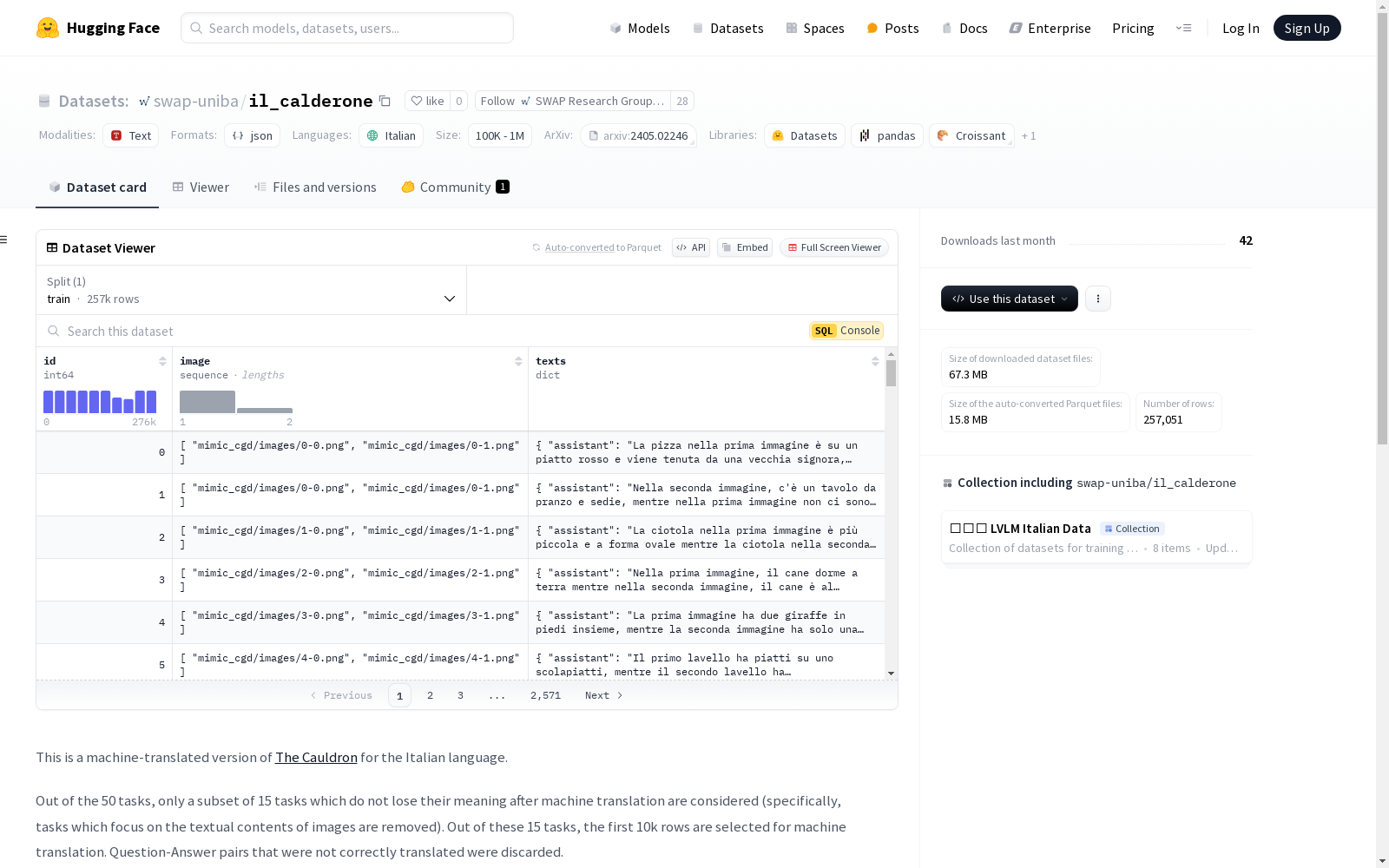
该数据集是[The Cauldron](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron)的机器翻译版本,专门为意大利语设计。原始数据集包含50个任务,但只有15个任务在机器翻译后仍保持其意义,因此被保留。在这15个任务中,选择了前10,000行进行机器翻译,未正确翻译的问答对被丢弃。图像路径的格式化策略如下:{task-name}/images/{row_number}_{image_number},其中{task-name}是原始数据集中的任务名称,{row_number}是原始数据集中的行号,{image_number}是图像的索引(在有多个图像作为输入的任务中)。
This dataset is a machine-translated version of [The Cauldron](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron), specifically designed for the Italian language. The original dataset contains 50 tasks, but only 15 tasks retained their meaning after machine translation and were thus preserved. For these 15 tasks, the first 10,000 rows were selected for machine translation, and incorrectly translated question-answer pairs were discarded. The formatting strategy for image paths is as follows: {task-name}/images/{row_number}_{image_number}, where {task-name} refers to the task name in the original dataset, {row_number} is the row number in the original dataset, and {image_number} is the index of the image (used in tasks with multiple input images).
提供机构:
SWAP Research Group@UNIBA
创建时间:
2024-11-27
搜集汇总
数据集介绍
构建方式
il_calderone数据集是基于意大利语机器翻译的版本,源自The Cauldron数据集。在构建过程中,从原始数据集的50个任务中筛选出15个在机器翻译后仍能保持语义完整的任务,剔除了依赖于图像文本内容的任务。随后,从这15个任务中选取前10,000行数据进行翻译,并过滤掉翻译不准确的问答对。图像路径的命名遵循特定格式,确保任务名称、行号及图像编号的清晰标识。
使用方法
il_calderone数据集适用于意大利语的多模态任务研究,特别是涉及文本与图像结合的场景。研究者可以通过图像路径的命名规则快速定位相关图像数据,并结合翻译后的文本进行多模态分析。在使用过程中,建议对翻译质量进行二次验证,以确保数据的准确性。该数据集为意大利语的自然语言处理及多模态模型训练提供了重要的资源支持。
背景与挑战
背景概述
il_calderone数据集是意大利语版本的'The Cauldron'数据集,由HuggingFace团队于2024年发布。该数据集旨在为意大利语的多模态学习提供支持,特别是在视觉与语言结合的任务中。数据集的核心研究问题在于如何有效地将多模态任务应用于意大利语环境,以提升语言模型在意大利语语境下的表现。主要研究人员包括Elio Musacchio、Lucia Siciliani、Pierpaolo Basile和Giovanni Semeraro,他们的研究发表在NL4AI 2024会议上。该数据集的发布对意大利语的自然语言处理和计算机视觉领域具有重要的推动作用,为相关研究提供了宝贵的数据资源。
当前挑战
il_calderone数据集在构建过程中面临了多方面的挑战。首先,机器翻译的质量直接影响了数据集的可用性,部分任务在翻译后失去了原有的语义,因此只能选择15个任务进行翻译。其次,图像路径的格式化策略需要与原始数据集保持一致,以确保数据的完整性和一致性。此外,翻译过程中出现的错误问答对需要被剔除,这对数据清洗提出了较高的要求。在应用层面,如何将多模态任务有效地应用于意大利语环境,尤其是在视觉与语言结合的任务中,仍然是一个亟待解决的问题。这些挑战不仅影响了数据集的构建过程,也对后续的研究和应用提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域,il_calderone数据集为意大利语的多模态任务提供了宝贵的资源。该数据集通过机器翻译技术,将原始英语任务转化为意大利语,保留了文本内容的核心意义。研究者可以利用该数据集进行跨语言的多模态学习,尤其是在图像与文本结合的问答任务中,探索语言模型在意大利语环境下的表现。
解决学术问题
il_calderone数据集解决了多模态学习中的语言障碍问题,特别是在意大利语环境下,缺乏高质量的多模态数据集限制了相关研究的发展。通过提供机器翻译后的意大利语任务,该数据集填补了这一空白,为研究者提供了跨语言多模态学习的实验平台,推动了意大利语自然语言处理与计算机视觉的交叉研究。
实际应用
在实际应用中,il_calderone数据集为意大利语的多模态智能系统开发提供了重要支持。例如,在智能客服、教育辅助工具以及跨语言信息检索系统中,该数据集可以帮助训练更精准的意大利语多模态模型,提升系统在理解图像与文本关联任务中的表现,从而改善用户体验。
数据集最近研究
最新研究方向
在自然语言处理与计算机视觉交叉领域,il_calderone数据集作为意大利语机器翻译版本,为多模态语言模型的研究提供了重要支持。该数据集聚焦于文本与图像的结合,通过筛选保留15个任务中的10,000行数据,确保了翻译质量与任务意义的完整性。近年来,随着多模态模型的快速发展,il_calderone数据集在意大利语环境下的应用成为研究热点,特别是在LLaVA-NDiNO等模型的开发中,展现了其在增强语言模型多模态能力方面的潜力。该数据集的引入不仅推动了意大利语多模态研究的深入,也为跨语言多模态模型的构建提供了新的实验基础。
以上内容由遇见数据集搜集并总结生成


