memebench
收藏Hugging Face2026-05-12 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/anonymous-neurips-2026/memebench
下载链接
链接失效反馈官方服务:
资源简介:
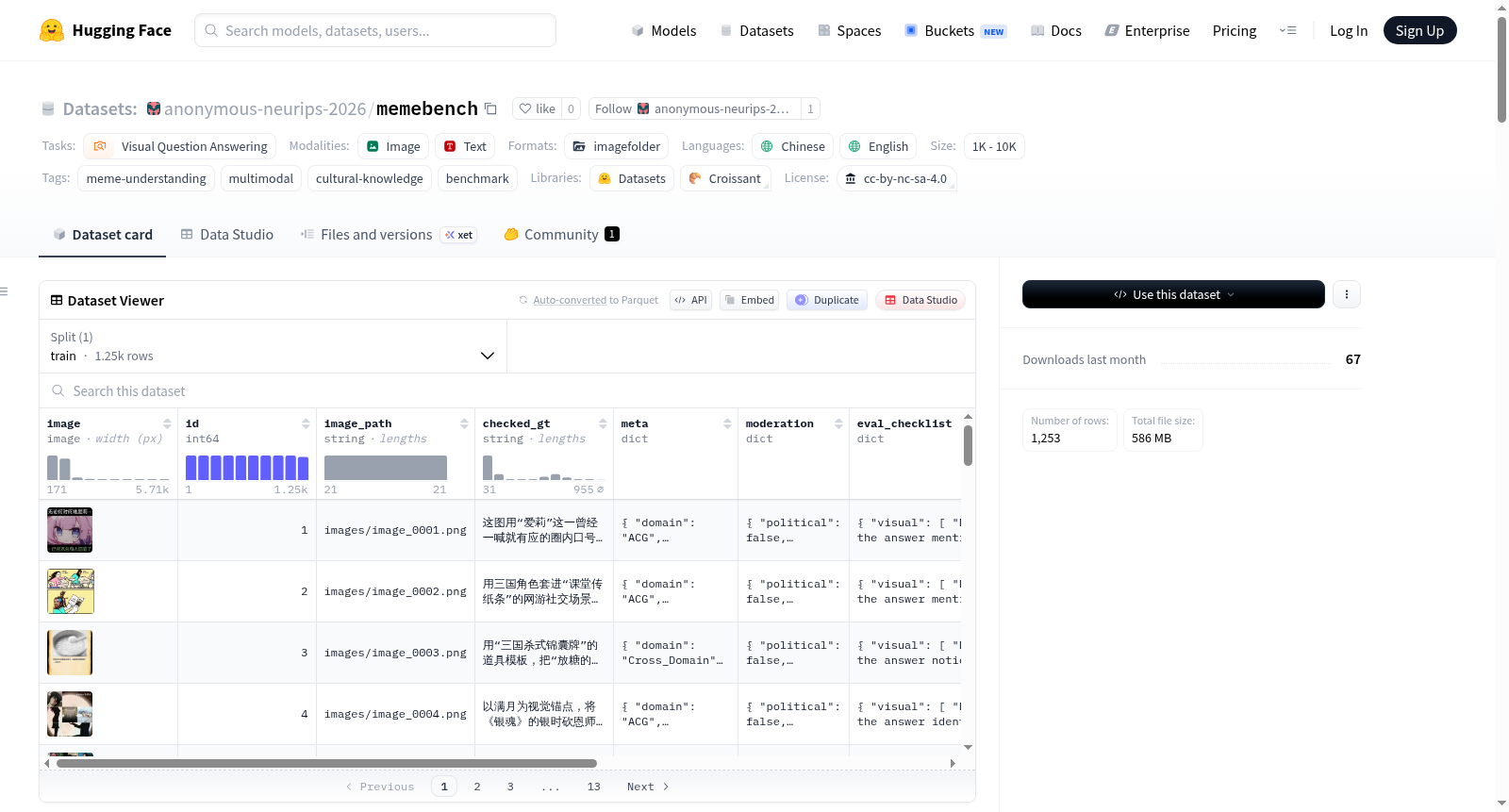
MemeBench 是一个用于开放式梗图(Meme)理解的双语诊断基准数据集,旨在系统评估大规模视觉语言模型(LVLM)的文化-语义理解能力。该数据集包含 1,253 个经过专家精细标注的梗图样本,覆盖了动漫/漫画/游戏(ACG)、电影/电视、历史、政治、日常生活、体育和跨领域等 7 个主要文化领域,并同时包含中文和英文内容。数据采用独特的 VIKR 四层结构化标注模式,从四个递进维度对模型理解能力进行诊断:视觉层(Visual,描述所见内容)、身份层(Identity,识别图中实体)、知识层(Knowledge,关联文化背景事实)和推理层(Reasoning,解析幽默机制)。每个样本的标注信息丰富,包括经过人工核实的标准解释(checked_gt)、元数据(如所属领域、语言、梗图类型和结构)、内容安全审核标记,以及四个维度的详细评估检查项和具体内容(如视觉描述与OCR文本、实体身份与来源、文化背景知识、幽默触发点与核心逻辑)。数据集统计显示,在领域分布上,ACG内容占比最高(50.1%),其次是跨领域内容(21.2%);在语言分布上,中文梗图占 61.3%,英文梗图占 38.7%。数据集的创建过程结合了大规模语言模型辅助标注与多领域专家人工验证,并遵循零知识视觉描述、实体双链接等设计原则,确保了标注的一致性和诊断的有效性。该数据集主要用于模型能力的诊断性评估(而非训练),其评估协议采用基于检查表的LLM即法官方法,核心指标为“完全通过率”,要求模型在VIKR四个维度上均正确回答所有检查问题。数据集存在一定的领域、语言和文化偏见,使用时需注意其局限性。
MemeBench is a bilingual diagnostic benchmark dataset for open-ended meme understanding, designed to systematically evaluate the cultural-semantic comprehension capabilities of large vision-language models (LVLMs). This dataset contains 1,253 meme samples meticulously annotated by domain experts, covering 7 major cultural domains including anime/comic/game (ACG), film/television, history, politics, daily life, sports, and cross-domain content, and includes both Chinese and English materials. The dataset employs a unique four-tier structured annotation framework named VIKR, which diagnoses model comprehension capabilities across four progressive dimensions: Visual Layer (describing the visible content), Identity Layer (identifying entities in the image), Knowledge Layer (associating cultural background facts), and Reasoning Layer (analyzing the humor mechanism). Each sample features rich annotation information, including manually verified standard explanations (checked_gt), metadata (such as affiliated domain, language, meme type and structure), content safety audit tags, as well as detailed evaluation check items and specific content across the four dimensions (e.g., visual description and OCR text, entity identity and source, cultural background knowledge, humor trigger points and core logic). Dataset statistics indicate that in terms of domain distribution, ACG content accounts for the largest share (50.1%), followed by cross-domain content (21.2%); in terms of language distribution, Chinese memes make up 61.3% while English memes account for 38.7%. The dataset was constructed through a process combining large language model-assisted annotation and multi-domain expert manual verification, adhering to design principles such as zero-knowledge visual description and entity dual-linking, which ensures annotation consistency and diagnostic validity. This dataset is primarily intended for diagnostic evaluation of model capabilities (rather than model training). Its evaluation protocol adopts the checklist-based LLM-as-judge methodology, with the core metric being "full pass rate", which requires the model to correctly respond to all check questions across all four VIKR dimensions. The dataset exhibits certain domain, language and cultural biases, and users should be mindful of its limitations during usage.
创建时间:
2026-05-01
搜集汇总
数据集介绍
构建方式
MemeBench的构建过程精心设计,以保障数据的诊断性与文化覆盖的广度。研究者从中英文互联网社区(包括论坛、社交媒体及图像平台)广泛采集模因,涵盖ACG、影视、历史等7个文化领域。随后,采用多阶段标注流水线:首先借助大语言模型生成结构化的VIKR初始标注,再由领域专家逐条审核与修正,并辅以自动化质量审计以确保实体双链、维度分离等模式约束,最终通过内容审核过滤政治与仇恨言论。这一严谨流程产出1253条经专家验证的高质量模因样本。
特点
该数据集的核心特色在于其VIKR诊断框架,将模因理解分解为视觉线索、身份链接、知识单元与推理机制四个可分离的层次,支持对大型视觉语言模型开展细粒度的文化语义评估。数据集覆盖中英双语,并以ACG内容为主(占50.1%),同时涵盖跨领域、日常生活等子集,逻辑类型分布呈现多样性,如身份冲突(43.8%)与反讽(29.0%)等。此外,其零知识视觉设计确保视觉层描述不含文化识别,保障了各维度的评价独立性。
使用方法
使用MemeBench时,研究者需以LLM作为评判代理,依据VIKR各维度的核验清单对模型回答进行记分。每个维度包含1至4个二元问题,仅当所有维度均通过(即V=1、I=1、K=1、R=1)时,该模因才被视为被完全理解,其核心指标为Complete Pass。数据集被设计为仅用于评估,而非训练,用户可直接加载存储于images目录下的模因图像与memebench_v1.json中的标注文件,并参照元数据中的领域、语言等字段进行切片分析。
背景与挑战
背景概述
MemeBench是一个于2026年在NeurIPS评估与数据集轨道上发布的双语诊断基准,由匿名研究团队构建,旨在评估大型视觉语言模型(LVLMs)对文化语义的理解能力。该数据集聚焦于网络迷因(meme)这一融合图像、文本与文化背景的多模态载体,针对现有模型在处理幽默、双关、身份碰撞等复杂文化现象时表现出的认知脆弱性,提出了1,253个经专家注释的迷因样本,涵盖中文和英文七类文化领域,并设计了VIKR(视觉线索、身份链接、知识单元、推理机制)四层诊断框架。MemeBench为多模态理解研究提供了一个结构化的文化语义评估工具,对内容审核、无障碍交互及跨文化交流等领域具有重要影响力。
当前挑战
MemeBench所解决的领域核心挑战在于,现有LVLMs在理解依赖深层文化背景知识的迷因时,往往仅能捕捉表层视觉信息,而无法解析其中蕴含的身份认知、文化典故与幽默逻辑。具体而言,模型面临以下难点:首先,迷因中的文化知识片段(如ACG角色、历史典故)需要模型具备外部知识整合能力;其次,幽默机制(如身份碰撞、反讽、谐音双关)依赖多模态信息的高阶推理与上下文关联;最后,文化背景的多样性(如中英文差异)要求模型克服地域性偏见。在数据集构建过程中,研究团队需解决迷因来源的广泛性与标注一致性之间的平衡,包括通过多阶段LLM辅助与人类专家校验确保VIKR各层注释分离,同时应对ACG领域占比过高(50.1%)带来的分布偏差,以及政治、体育等低样本域的代表性不足问题,以保证评估的公正性与鲁棒性。
常用场景
经典使用场景
在跨文化语义理解与多模态智能的交汇领域,MemeBench被设计为一项诊断性基准测试,专用于评估大型视觉语言模型对梗图背后文化意涵的诠释能力。其经典使用场景在于,通过精心构建的VIKR四层诊断架构——视觉线索、身份链接、知识单元与推理机制——系统性地检验模型从具象视觉感知到抽象文化推理的全链路认知表现。研究者借助这一工具,能够深入剖析模型在处理包含复杂文化指涉、幽默逻辑及多模态信息的梗图时,究竟在哪个环节存在理解断层,从而为多模态模型的文化敏感性评估提供标尺。
实际应用
在实际应用层面,MemeBench的评估框架可被直接部署于多模态内容审核系统,提升其对讽刺性、影射性及亚文化梗图的识别精度,从而辅助社交媒体平台进行更精准的有害信息过滤。此外,该基准还能服务于跨文化人工智能助手的设计优化,帮助模型在跨国传播场景中准确解读本土化笑点与文化符号,避免因文化误读引发的沟通失效。对于无障碍技术而言,梗图自动描述与解释功能可借助MemeBench的诊断标准进行训练与调优,为视觉障碍用户提供更深层的文化性图片解说。
衍生相关工作
围绕MemeBench,已涌现出一系列富有启发性的衍生研究。基于其VIKR架构,研究者开发了面向特定领域的轻量级诊断工具,如针对ACG亚文化的细粒度模因理解评估。部分工作进一步探索了知识图谱与多模态模型在文化推理上的融合,将VIKR中的知识单元外部化为可检索的结构化知识库,以增强模型的零样本文化泛化能力。此外,幽默逻辑类型(如身份碰撞、反讽、规则违反等)的统计分布为计算幽默学提供了实证基础,催生了针对不同幽默机制的多模态分类与生成研究,拓展了数据集在教育评测与文化计算等领域的应用边界。
以上内容由遇见数据集搜集并总结生成


