mikewang/vaw
收藏Hugging Face2023-08-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mikewang/vaw
下载链接
链接失效反馈官方服务:
资源简介:
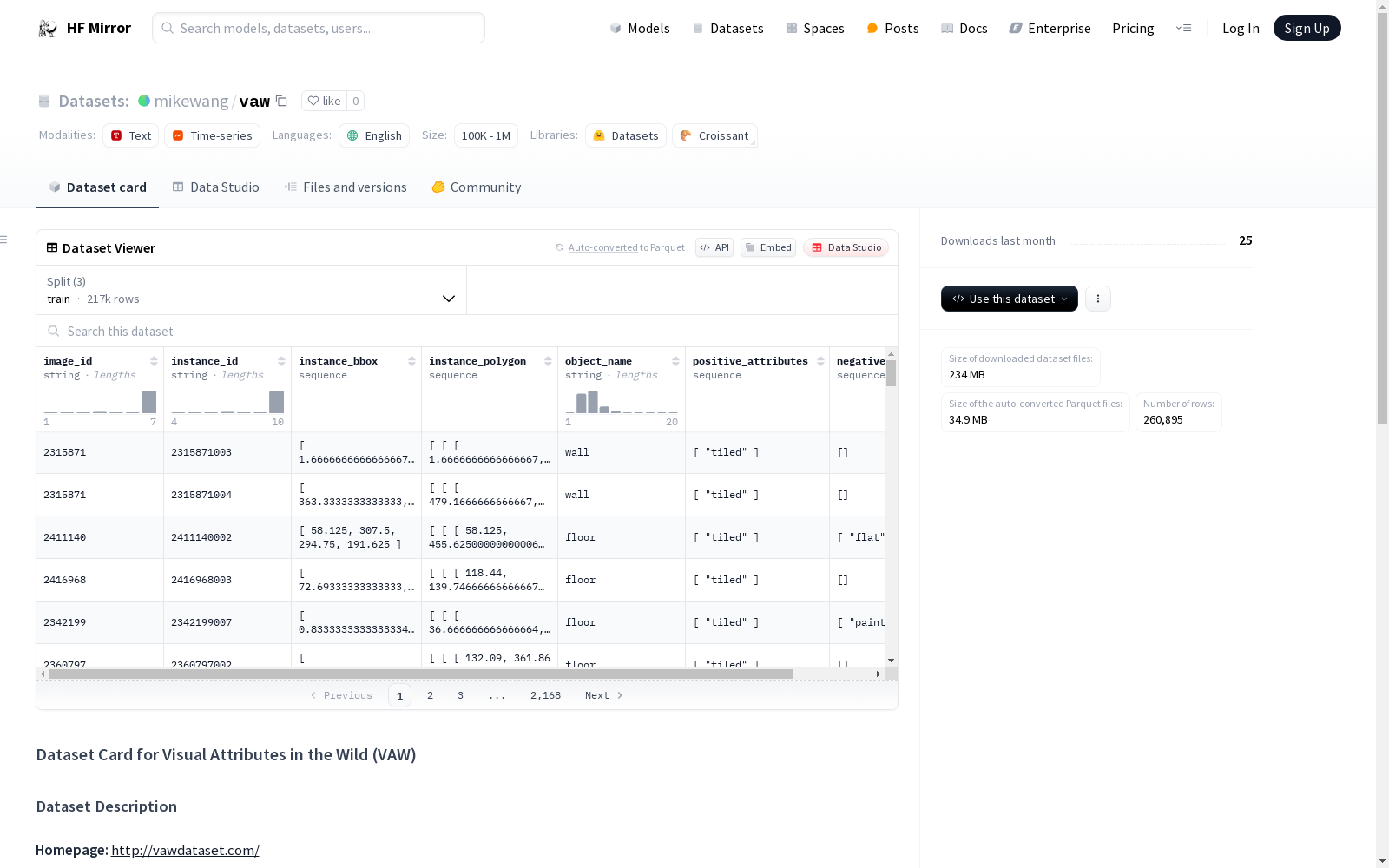
VAW(Visual Attributes in the Wild)是一个大规模视觉属性数据集,包含明确标注的正负属性。数据集包含620个独特属性(如颜色、形状、纹理、姿势等)、260,895个不同对象的实例、2260个在野外观察到的独特对象、72,274张来自Visual Genome数据集的图像,以及4种不同的评估指标用于衡量多方面的性能指标。
VAW (Visual Attributes in the Wild) is a large-scale visual attribute dataset with explicitly annotated positive and negative attributes. It includes 620 unique attributes (such as color, shape, texture, pose, etc.), 260,895 instances of distinct objects, 2,260 unique objects observed in the wild, 72,274 images sourced from the Visual Genome dataset, and 4 distinct evaluation metrics for assessing multi-faceted performance.
提供机构:
mikewang
原始信息汇总
数据集卡片 for Visual Attributes in the Wild (VAW)
数据集描述
主页: http://vawdataset.com/
仓库: https://github.com/adobe-research/vaw_dataset
- 原始数据文件将从以下地址下载: https://github.com/adobe-research/vaw_dataset/tree/main/data,其中还可以找到额外的元数据文件,如属性类型。
- 从hf数据集加载的训练集是train_part1.json和train_part2.json的连接。
- image_id字段对应于v1.4 Visual Genome数据集中的相应图像ID。
许可证: https://github.com/adobe-research/vaw_dataset/blob/main/LICENSE.md
论文引用:
@InProceedings{Pham_2021_CVPR, author = {Pham, Khoi and Kafle, Kushal and Lin, Zhe and Ding, Zhihong and Cohen, Scott and Tran, Quan and Shrivastava, Abhinav}, title = {Learning To Predict Visual Attributes in the Wild}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2021}, pages = {13018-13028} }
数据集概述
一个大规模的视觉属性数据集,具有明确标记的正负属性。
- 620个独特的属性,包括颜色、形状、纹理、姿势等
- 260,895个不同对象的实例
- 2260个在野外观察到的独特对象
- 72,274张来自Visual Genome数据集的图像
- 4种不同的评估指标,用于测量多方面的性能指标
搜集汇总
数据集介绍
构建方式
在计算机视觉研究领域,视觉属性的识别与分析是理解图像内容的重要维度。Visual Attributes in the Wild (VAW)数据集的构建采用了对Visual Genome数据集中的图像进行深入标注的方法,通过人工标注识别出620种独特的视觉属性,包括颜色、形状、纹理、姿势等。该数据集的构建过程涉及将训练数据分为两部分,并合并为训练集,同时图像ID与Visual Genome数据集中的相应图像ID相对应,确保了数据的一致性和可用性。
特点
VAW数据集以其大规模的视觉属性标注而显著,包含了260,895个不同对象实例和2260个在野外观察到的独特对象。数据集中的72,274张图像来源于Visual Genome数据集,并提供了4种不同的评估指标,以测量多方面的性能指标。其标注的明确性,即正负属性的显式标记,为视觉属性的学习与预测提供了丰富的信息基础。
使用方法
用户可以通过访问VAW数据集的官方网站或GitHub仓库获取数据集及其元数据文件。数据集的使用涉及加载训练集和测试集,其中训练集是由train_part1.json和train_part2.json合并而成的。用户需遵循LICENSE文件中的规定使用数据集,并在研究成果中引用相关论文,以尊重数据集的版权和使用条款。
背景与挑战
背景概述
在计算机视觉研究领域,对视觉属性的理解与识别是一项基础且关键的任务。Visual Attributes in the Wild (VAW)数据集,创建于2021年,由Pham等研究人员提出,并在IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)上发表相关论文。该数据集旨在通过大规模的视觉属性标注,为机器学习模型提供训练资源,以实现对图像中各种属性如颜色、形状、纹理等的识别。VAW数据集以其明确的正负属性标注,为视觉属性识别研究提供了重要资源,对相关领域产生了显著影响。
当前挑战
VAW数据集在构建过程中,面临了多项挑战。首先,数据集的标注质量直接影响到模型训练的效果,因此确保属性标注的准确性是一个重要挑战。其次,数据集规模巨大,包含72,274张图像和620个独特属性,这要求在数据管理和处理上必须高效且精确。此外,如何有效评估模型的性能也是一个挑战,VAW数据集采用了四种不同的评价指标,以全面衡量模型的性能,这在实际应用中也是一项技术难点。
常用场景
经典使用场景
在计算机视觉研究领域,Visual Attributes in the Wild (VAW) 数据集被广泛应用于视觉属性的识别与预测。该数据集通过提供大量带有明确标注的正负视觉属性图像,为研究者提供了一个丰富的实验平台,使其能够训练模型以识别图像中对象的特定属性,如颜色、形状、纹理等。
衍生相关工作
VAW 数据集的发布促进了相关领域的研究进展,衍生出了一系列经典工作。例如,基于VAW数据集的研究成果在图像描述生成、视觉问答等任务中取得了显著成效,推动了计算机视觉与自然语言处理领域的交叉融合。
数据集最近研究
最新研究方向
在计算机视觉领域,视觉属性的识别与预测是当前研究的热点。基于mikewang/vaw数据集,最新的研究方向聚焦于在野外环境中对视觉属性的学习与预测。该数据集以其大规模的视觉属性标注和明确的正负属性标签,为研究提供了丰富的资源。近期,Pham等研究者通过此数据集,探索了视觉属性的深度学习预测方法,其研究成果已在CVPR 2021上发表。该研究不仅提升了视觉属性识别的准确性,也为相关应用如图像检索、内容推荐等提供了新的视角和技术路径,具有显著的研究价值和实际应用潜力。
以上内容由遇见数据集搜集并总结生成


