multilingual-financial-sentiment
收藏Hugging Face2026-04-10 更新2026-04-11 收录
下载链接:
https://huggingface.co/datasets/Kenpache/multilingual-financial-sentiment
下载链接
链接失效反馈官方服务:
资源简介:
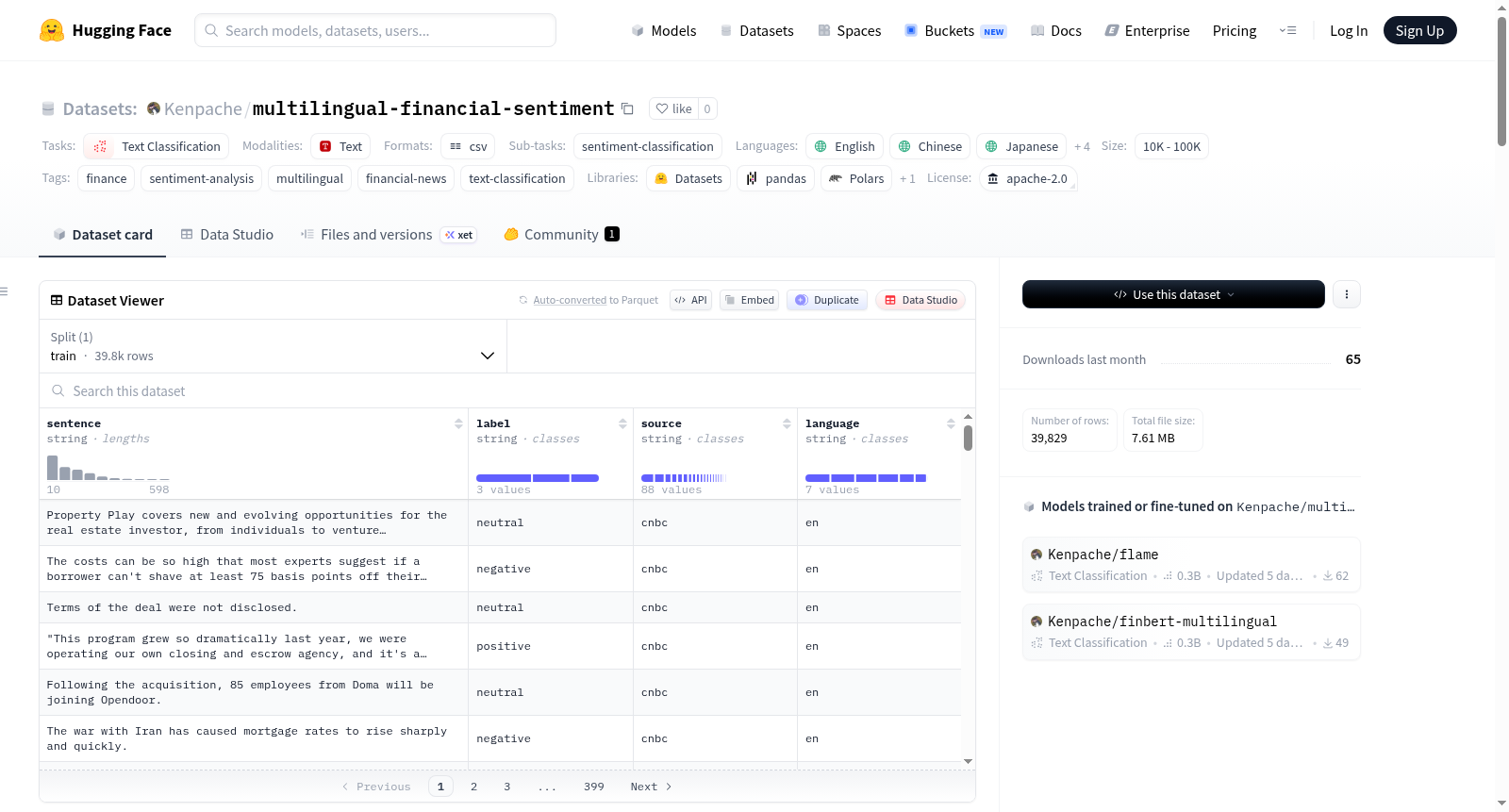
多语言金融情感数据集是一个精心整理的金融新闻句子数据集,包含39,829条标注了情感标签(负面/中性/正面)的句子,涵盖7种语言(英语、中文、日语、德语、法语、西班牙语、阿拉伯语)。数据来自全球80多家金融新闻媒体。数据集以CSV格式提供,包含四个字段:句子文本、情感标签、新闻来源和语言代码。各语言样本分布为:日语20.8%、中文19.9%、西班牙语17.9%、英语17.3%、德语12.6%、法语9.9%、阿拉伯语1.6%。整体情感标签分布为:中性45.5%、正面30.8%、负面23.7%。该数据集适用于多语言情感分析研究,特别是金融领域的文本分类任务。数据集采用Apache 2.0许可,仅限学术和非商业研究使用。
The Multilingual Financial Sentiment Dataset is a meticulously curated collection of financial news sentences, containing 39,829 labeled entries with sentiment tags (negative, neutral, positive) across 7 languages: English, Chinese, Japanese, German, French, Spanish, and Arabic. The data is sourced from over 80 global financial news media outlets. The dataset is distributed in CSV format, with four fields: sentence text, sentiment label, news source, and language code. The sample distribution per language is: Japanese 20.8%, Chinese 19.9%, Spanish 17.9%, English 17.3%, German 12.6%, French 9.9%, and Arabic 1.6%. The overall sentiment label distribution is: neutral 45.5%, positive 30.8%, and negative 23.7%. This dataset is applicable to multilingual sentiment analysis research, particularly text classification tasks in the financial domain. The dataset is licensed under Apache 2.0, and is restricted to academic and non-commercial research use only.
创建时间:
2026-04-06
搜集汇总
数据集介绍
构建方式
在金融文本分析领域,数据质量直接决定了模型性能的上限。该数据集通过系统化流程构建,从全球超过80家主流财经媒体中采集原始新闻内容,涵盖英语、中文、日语、德语、法语、西班牙语及阿拉伯语七种语言。采集的文本经过预处理,被分割为独立的句子单元,并采用人工或半自动标注策略,为每个句子赋予负面、中性或正面三类情感标签。最终整理形成的结构化数据集包含39,829条样本,以CSV格式存储,确保了数据的一致性与易用性。
特点
本数据集的核心特征在于其多语言性与领域专业性。它不仅覆盖了七种使用广泛的语言,样本量分布相对均衡,尤其以日语、中文和西班牙语样本最为丰富,而且所有数据均源自权威财经新闻机构,保证了文本的领域相关性与真实性。数据标签呈现三分类分布,其中中性情感占比最高,反映了金融新闻客观陈述的普遍性。这种多语言、高质量标注的设计,为开发跨语言金融情感分析模型提供了宝贵的训练与评估资源。
使用方法
为便利研究人员使用,该数据集已托管于Hugging Face平台。用户可通过`datasets`库直接加载,或使用`pandas`读取远程CSV文件。加载后,数据以DataFrame形式呈现,包含句子、标签、来源和语言四个字段,支持按语言或情感标签进行灵活筛选。例如,可轻松提取所有英文正面情感的样本用于模型训练。鉴于其学术研究用途的定位,使用者需严格遵守许可协议,商业应用则应另行获取原始版权方的授权。
背景与挑战
背景概述
在金融信息全球化与多语言文本分析需求日益增长的背景下,多语言金融情感数据集应运而生。该数据集由研究人员或机构Kenpache于近期创建,旨在应对跨语言金融新闻情感分析的复杂任务。其核心研究问题聚焦于如何准确识别与分类不同语言金融文本中的情感倾向,从而为跨国投资决策、市场情绪监测及风险预警提供数据支持。通过整合来自全球80余家金融新闻源的近四万条标注句子,涵盖英语、中文、日语等七种语言,该数据集显著推动了多语言自然语言处理技术在金融领域的应用,为跨文化市场分析奠定了重要基础。
当前挑战
该数据集致力于解决金融领域多语言情感分析的核心挑战,包括金融文本中专业术语与语境依赖性强所导致的情感歧义,以及不同语言文化背景下情感表达方式的差异性,这增加了模型泛化与跨语言迁移的难度。在构建过程中,面临数据采集与标注的多重困难:需从分散的全球新闻源中合规提取多语言文本,并确保标注一致性以克服主观偏差;同时,各语言样本量分布不均,如阿拉伯语数据仅占1.6%,可能影响少数语言情感分类的模型性能。此外,原始文本的版权限制与商业使用许可问题亦为数据集的广泛应用带来合规性挑战。
常用场景
经典使用场景
在金融文本分析领域,多语言金融情感数据集为跨语言情感分类模型的训练与评估提供了标准化基准。该数据集汇集了来自全球80余家新闻源的近四万条金融新闻句子,覆盖七种主要语言,其经典应用场景在于构建和优化多语言情感分析模型,以自动识别金融新闻中的积极、中性或消极情感倾向。研究者利用该数据集进行模型微调,显著提升了模型在多样化语言环境下的泛化能力和鲁棒性,为金融市场的情绪监控奠定了技术基础。
衍生相关工作
围绕该数据集,学术界衍生了一系列经典研究工作。例如,基于其构建的多语言BERT变体在金融情感分类任务中展现了优越性能;相关研究还探索了跨语言对抗训练、少样本学习等技术,以应对数据不平衡与低资源语言挑战。这些工作不仅丰富了多语言NLP的方法体系,也为后续更大规模金融语料库的构建提供了标注范式与处理流程,持续推动着金融人工智能领域的技术演进。
数据集最近研究
最新研究方向
在金融科技与自然语言处理交叉领域,多语言金融情感数据集正推动前沿研究向跨语言迁移学习与低资源语言适应方向深化。随着全球金融市场联动性增强,研究者利用该数据集探索预训练模型在阿拉伯语等样本较少语言上的微调策略,以提升情感分类的泛化能力。同时,结合领域自适应技术,该数据集支持分析不同文化背景下金融新闻的情感表达差异,为量化投资与风险预警模型提供跨市场语义理解基础。近期研究还关注多任务学习框架,整合情感分析与事件检测,以捕捉金融文本中的细微情绪波动与市场反应关联,增强算法在动态金融环境中的解释性与鲁棒性。
以上内容由遇见数据集搜集并总结生成


