有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
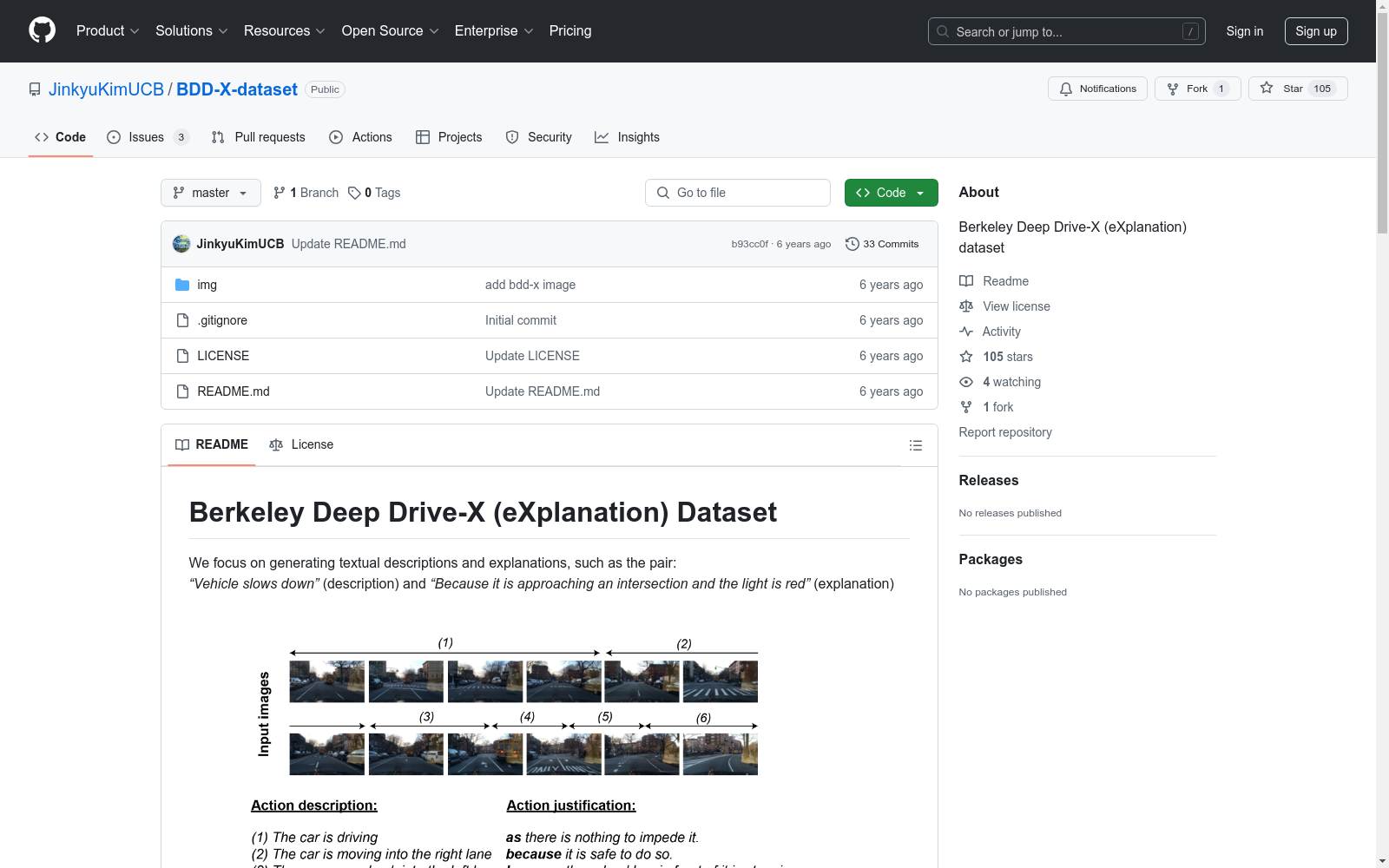
我们专注于生成文本描述和解释,例如以下配对:
下载我们的 BDD-X dataset,包含以下内容:
我们的数据集包含超过77小时的驾驶视频,共6,970个视频。视频在多种驾驶条件下拍摄,例如白天/夜晚、高速公路/城市/乡村、夏季/冬季等。每个视频平均时长40秒,包含约3-4个动作,如加速、减速、右转等,所有动作都带有描述和解释。数据集包含超过26,000个活动,超过840万帧。我们提供了训练集、验证集和测试集,分别包含5,597、717和656个视频。
我们的解释数据集建立在Berkeley Deep Drive数据集之上,该数据集通过人类驾驶车辆的仪表盘摄像头收集。该数据集包含约40秒长的仪表盘摄像头视频,由安装在车辆挡风玻璃后方的单个前视摄像头捕捉。视频主要在城市驾驶中拍摄,涵盖各种天气条件,包括白天和夜间。数据集还包括在其他道路类型上的驾驶,如住宅道路(有或无车道标记),并包含所有典型的驾驶员活动,如保持在车道内、转弯、变道等。除了视频数据外,数据集还提供了一系列时间戳传感器测量值,如车辆的速度、航向和GPS位置。
我们的标注过程如下:我们提供一个驾驶视频,并要求人类标注者想象自己是一名驾驶教练。我们特别选择熟悉美国驾驶规则的标注者。标注者需要描述驾驶员正在做什么(尤其是在行为改变时)以及为什么,从驾驶教练的角度出发。每个描述的动作都必须伴随开始和结束时间戳。标注者可以在视频中暂停、快进和后退,以寻找有趣且合理的活动。
如果您发现此数据集有用,请引用此论文(并参考数据集为Berkeley DeepDrive eXplanation或BDD-X数据集):
@article{kim2018textual, title={Textual Explanations for Self-Driving Vehicles}, author={Kim, Jinkyu and Rohrbach, Anna and Darrell, Trevor and Canny, John and Akata, Zeynep}, journal={Proceedings of the European Conference on Computer Vision (ECCV)}, year={2018} }
中国1km分辨率逐月降水量数据集(1901-2023)
该数据集为中国逐月降水量数据,空间分辨率为0.0083333°(约1km),时间为1901.1-2023.12。数据格式为NETCDF,即.nc格式。该数据集是根据CRU发布的全球0.5°气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国降尺度生成的。并且,使用496个独立气象观测点数据进行验证,验证结果可信。本数据集包含的地理空间范围是全国主要陆地(包含港澳台地区),不含南海岛礁等区域。为了便于存储,数据均为int16型存于nc文件中,降水单位为0.1mm。 nc数据可使用ArcMAP软件打开制图; 并可用Matlab软件进行提取处理,Matlab发布了读入与存储nc文件的函数,读取函数为ncread,切换到nc文件存储文件夹,语句表达为:ncread (‘XXX.nc’,‘var’, [i j t],[leni lenj lent]),其中XXX.nc为文件名,为字符串需要’’;var是从XXX.nc中读取的变量名,为字符串需要’’;i、j、t分别为读取数据的起始行、列、时间,leni、lenj、lent i分别为在行、列、时间维度上读取的长度。这样,研究区内任何地区、任何时间段均可用此函数读取。Matlab的help里面有很多关于nc数据的命令,可查看。数据坐标系统建议使用WGS84。
国家青藏高原科学数据中心 收录
网易云音乐数据集
该数据集包含了网易云音乐平台上的歌手信息、歌曲信息和歌单信息,数据通过爬虫技术获取并整理成CSV格式,用于音乐数据挖掘和推荐系统构建。
github 收录
poi
本项目收集国内POI兴趣点,当前版本数据来自于openstreetmap。
github 收录
CIFAR-10
CIFAR-10 数据集由 10 个类别的 60000 个 32x32 彩色图像组成,每个类别包含 6000 个图像。有 50000 个训练图像和 10000 个测试图像。 数据集分为五个训练批次和一个测试批次,每个批次有 10000 张图像。测试批次恰好包含来自每个类别的 1000 个随机选择的图像。训练批次包含随机顺序的剩余图像,但一些训练批次可能包含来自一个类的图像多于另一个。在它们之间,训练批次恰好包含来自每个类别的 5000 张图像。
OpenDataLab 收录
Breast Ultrasound Images (BUSI)
小型(约500×500像素)超声图像,适用于良性和恶性病变的分类和分割任务。
github 收录