debate-tracking-v3
收藏Hugging Face2026-01-20 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/debaterhub/debate-tracking-v3
下载链接
链接失效反馈官方服务:
资源简介:
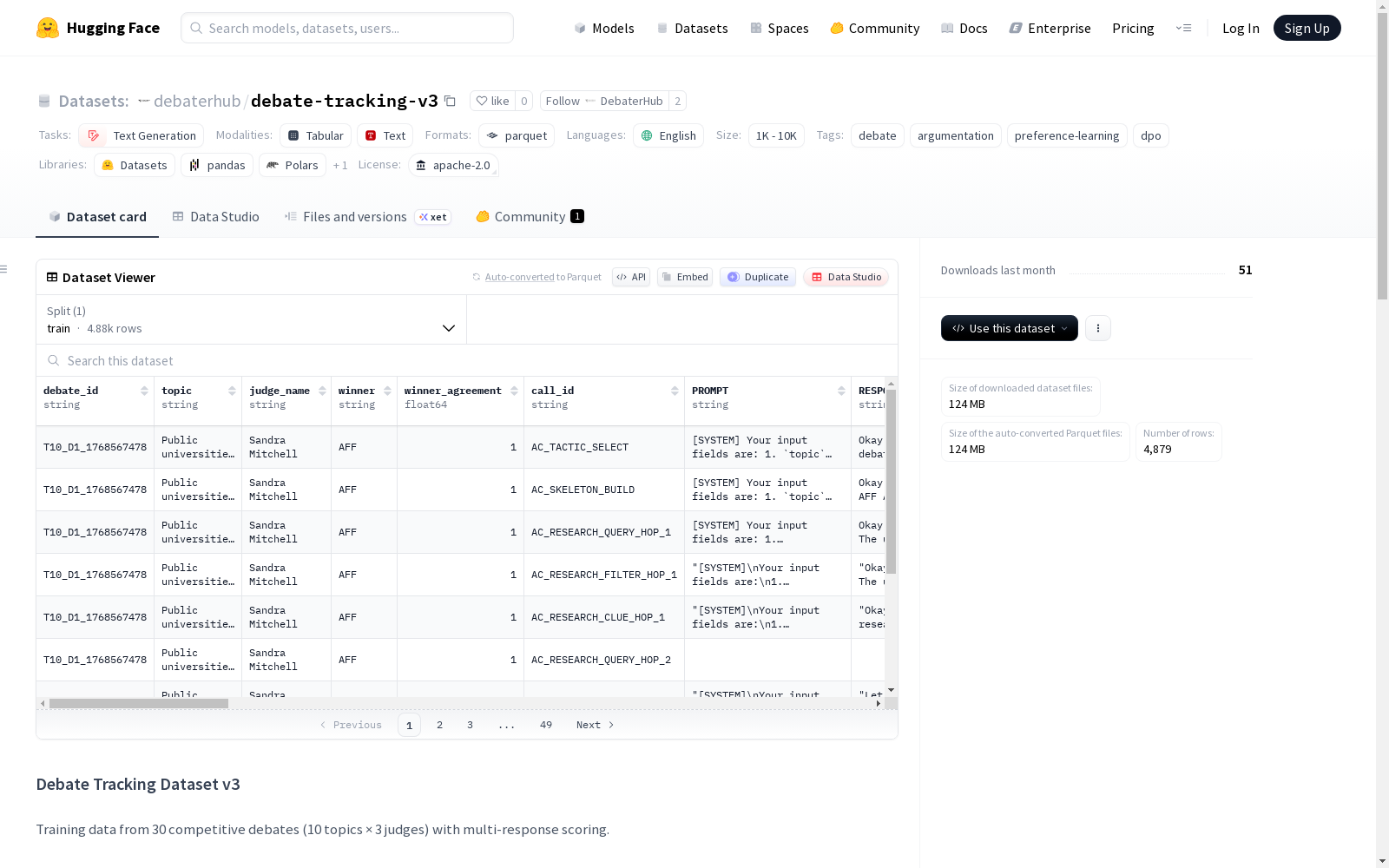
该数据集是一个关于辩论追踪的数据集,包含30场竞争性辩论的训练数据,涉及10个不同的辩论主题和3种不同的评委角色。每个数据行代表一次LLM调用,包含多个由Claude Sonnet评分的响应变体。数据集详细记录了辩论的各个方面,包括辩论ID、主题、评委名称、胜者、胜者同意率、调用ID、完整提示、4个响应变体及其评分和反馈等。数据集还提供了辩论主题的详细信息,如普遍基本收入是否会减少美国的贫困、美国是否应该废除选举人团等。
This is a debate tracking dataset comprising training data from 30 competitive debates covering 10 distinct debate topics and 3 distinct judge roles. Each data row corresponds to an LLM call, containing multiple response variants scored by Claude Sonnet. The dataset comprehensively documents all aspects of the debates, including debate ID, topic, judge name, winner, winner approval rate, call ID, full prompt, four response variants alongside their respective scores and feedback, and other relevant details. Additionally, the dataset provides detailed information on the debate topics, such as "Would Universal Basic Income reduce poverty in the United States?" and "Should the United States abolish the Electoral College?", among others.
创建时间:
2026-01-16
原始信息汇总
Debate Tracking Dataset v3 数据集概述
数据集基本信息
- 名称: Debate Tracking Dataset v3
- 托管地址: https://huggingface.co/datasets/debaterhub/debate-tracking-v3
- 许可证: Apache 2.0
- 任务类别: 文本生成
- 语言: 英语
- 标签: 辩论、论证、偏好学习、DPO
- 规模分类: 1K<n<10K
数据集描述
该数据集包含来自30场竞争性辩论的训练数据,每行代表辩论生成过程中的一次LLM调用,并由Claude Sonnet对多个响应变体进行评分。
数据统计
- 辩论场次: 30
- 主题数量: 10个不同的IPDA辩论决议
- 法官类型: 3种不同的法官角色(外行、家长、教练)
- 训练示例: 1,816次调用
- 获胜方分布: 正方33%,反方67%
- 训练集大小: 48,779个示例
数据特征(列)
debate_id: 唯一辩论标识符topic: 辩论决议judge_name: 法官角色名称winner: 辩论获胜方(正方/反方)winner_agreement: 法官同意率call_id: 调用类型PROMPT: 调用的完整提示RESPONSE_{1-4}_CONTENT: 4个响应变体RESPONSE_{1-4}_SCORE: Sonnet评分(0.0-1.0)RESPONSE_{1-4}_FEEDBACK: 详细的评分反馈chosen_index: 用于DPO的最佳响应索引rejected_index: 用于DPO的最差响应索引max_score: 最高分min_score: 最低分iteration: 迭代次数call_type: 调用类型
辩论主题列表
- 全民基本收入将减少美国的贫困
- 美国应该废除选举人团制度
- 人工智能创造的工作岗位将多于其摧毁的
- 社交媒体平台应对用户内容承担法律责任
- 美国应采用单一支付者医疗保健系统
- 太空探索资金应优先于海洋探索
- 大学应取消传承录取
- 最低工资应提高到每小时20美元
- 自动驾驶汽车将使道路更安全
- 公立大学应对所有学生免学费
使用方式
python from datasets import load_dataset dataset = load_dataset("debaterhub/debate-tracking-v3")
搜集汇总
数据集介绍
构建方式
在辩论追踪研究领域,debate-tracking-v3数据集通过精心设计的实验框架构建而成。该数据集采集了三十场具有竞争性的辩论对话,涵盖十个多样化的国际公共辩论协会议题,并引入三种不同背景的裁判角色进行多维度评估。每一行数据代表一次大型语言模型的调用记录,生成了四个不同的回应变体,随后由Claude Sonnet模型依据预设的评分标准对每个回应进行量化打分,并附有详细的反馈文本。这种构建方式确保了数据在对话生成与偏好学习任务中的代表性和可靠性。
使用方法
对于旨在提升语言模型辩论与推理能力的研究者而言,该数据集的使用方法清晰而直接。用户可通过Hugging Face的`datasets`库便捷加载数据,继而利用其中包含的提示、多轮回应、分数及偏好索引等字段。典型应用场景包括训练模型进行论据生成与策略选择,或利用成对的偏好数据执行直接偏好优化以对齐模型输出与人类评判标准。数据集的标准化格式确保了其能无缝集成到现有的自然语言处理训练流程中,为相关实验提供了坚实的基础。
背景与挑战
背景概述
在自然语言处理与论辩计算领域,高质量的对话与辩论数据集对于推动偏好学习与强化学习技术的发展至关重要。Debate Tracking Dataset v3 由DebaterHub团队构建,发布于2024年,旨在通过记录结构化辩论过程,为直接偏好优化等算法提供多响应评分数据。该数据集聚焦于十个具有社会争议性的IPDA辩论议题,涵盖三种不同背景的裁判视角,核心研究问题在于如何基于多轮对话与评分机制,训练语言模型生成更具说服力与逻辑性的论辩内容。其对论辩生成、对话系统以及对齐研究领域产生了显著影响,为模型在复杂语义空间中的偏好学习提供了实证基础。
当前挑战
该数据集致力于解决论辩生成与评估领域的核心挑战,即如何量化论辩质量并引导模型生成逻辑严谨、具有说服力的响应。具体而言,挑战体现在裁判评分的客观性与一致性难以保证,不同裁判背景可能导致偏好偏差;同时,辩论议题的多样性与复杂性要求模型具备深层语义理解与推理能力。在构建过程中,数据采集面临多轮对话跟踪与标注的复杂性,需确保响应变体在可控范围内保持语义连贯;此外,利用Claude Sonnet进行自动化评分虽提升效率,但如何校准评分机制以反映人类裁判的真实偏好,仍是一个亟待解决的技术难题。
常用场景
经典使用场景
在辩论分析与人工智能交互领域,debate-tracking-v3数据集为研究者提供了丰富的多响应评分辩论记录。该数据集最经典的使用场景在于直接偏好优化(DPO)的训练过程,通过对比不同响应变体的评分与反馈,模型能够学习如何生成更具说服力且符合评委偏好的辩论内容。这一场景不仅涵盖了辩论策略的自动生成,还涉及对复杂论点的评估与优化,为自然语言处理中的偏好学习提供了实证基础。
解决学术问题
该数据集有效解决了辩论生成与评估中的若干核心学术问题,包括如何量化辩论内容的质量、如何建模评委的偏好差异,以及如何通过多响应对比提升生成模型的论辩能力。其意义在于将主观的辩论评判转化为可计算的评分指标,为自动化辩论系统的开发奠定了数据基础,推动了论辩计算领域从规则驱动向数据驱动的范式转变,促进了人工智能在复杂推理任务中的深入应用。
实际应用
在实际应用层面,debate-tracking-v3数据集可被用于构建智能辩论助手、教育技术工具以及舆情分析系统。例如,在学术写作或公共演讲训练中,系统能够基于历史辩论数据生成针对性的论点建议,并提供评分反馈以帮助用户改进论证逻辑。此外,该数据集支持的模型优化也有助于开发更公平、透明的自动化决策支持工具,应用于政策辩论或商业谈判等现实场景。
数据集最近研究
最新研究方向
在论辩与论证挖掘领域,debate-tracking-v3数据集正推动基于偏好学习的语言模型对齐研究。该数据集通过多响应评分机制,为直接偏好优化(DPO)提供了高质量的对比样本,使得模型能够从人类或模拟裁判的反馈中学习论辩策略的优劣。前沿工作聚焦于利用此类数据训练更具说服力与逻辑一致性的对话系统,以应对复杂社会议题的自动化辩论需求,同时探索多裁判视角下的鲁棒性评估,为可解释人工智能的发展注入新动力。
以上内容由遇见数据集搜集并总结生成


