TimeStress
收藏Hugging Face2025-06-23 更新2025-06-24 收录
下载链接:
https://huggingface.co/datasets/Orange/TimeStress
下载链接
链接失效反馈官方服务:
资源简介:
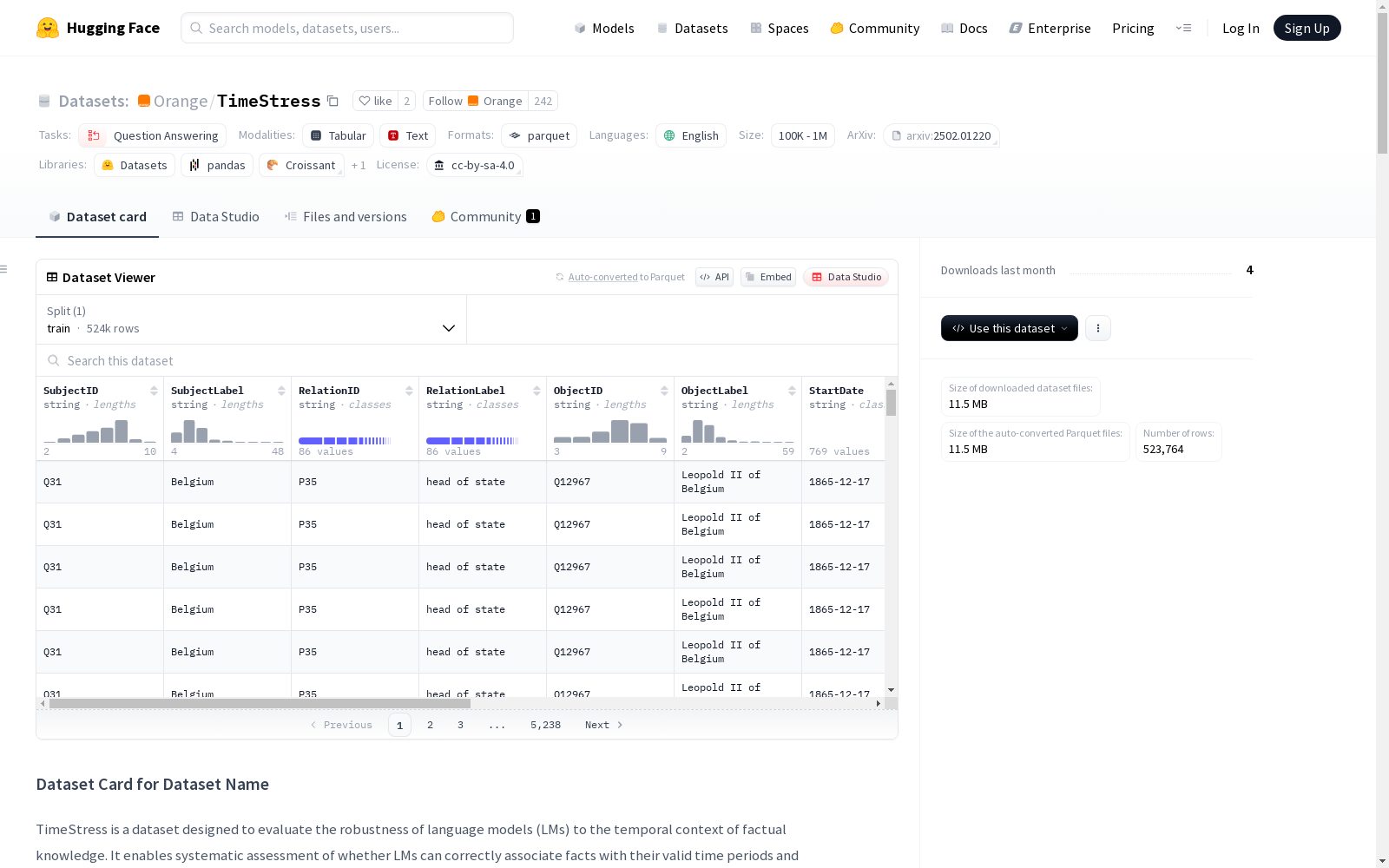
TimeStress是一个专门设计用来评估语言模型在事实知识的时间上下文方面的鲁棒性的数据集。它由超过521,000条基于2,003个带时间有效性的事实生成的自然语言陈述组成,涵盖了1,883个独特实体和86种关系。每个事实都注有时间有效性期间,并转化为问题-答案陈述,附有时间上下文。
TimeStress is a dataset specifically designed to evaluate the robustness of language models regarding the temporal context of factual knowledge. It comprises over 521,000 natural language statements generated from 2,003 temporally valid facts, covering 1,883 unique entities and 86 types of relationships. Each fact is annotated with its temporal validity period, and converted into question-answer statements accompanied by temporal context.
提供机构:
Orange
创建时间:
2025-06-20
搜集汇总
数据集介绍
构建方式
TimeStress数据集的构建过程体现了对语言模型时序推理能力的系统性考察。研究团队从预处理后的Wikidata中筛选出具有明确有效期(起止日期)且有效期超过三年的非字面量事实,通过维基百科页面浏览量计算流行度指数,最终精选出2003条最受欢迎的事实条目。采用GPT-4o模型对每个事实生成四种自然语言问句变体,并严格遵循过去时态、简洁表达等规范。在时序标注方面,团队针对每个事实按年、年月、年月日三种粒度采样,根据时间上下文与事实有效期的重叠关系标注为正确、错误或过渡状态。
使用方法
研究者可通过加载parquet格式数据文件,利用SubjectID、RelationID等字段构建知识图谱关联。重点应关注Statement字段中的自然语言陈述与Time字段的时间标记,结合Status字段验证模型时序推理能力。数据集特别适用于分析语言模型在不同时间粒度下对事实有效期的判断精度,以及Alpha参数反映的时间偏移敏感度。使用前需注意所有事实的有效期均截止于2021年前,且评估结论受限于特定的问答陈述格式。
背景与挑战
背景概述
TimeStress数据集由Orange Research团队于2025年推出,旨在系统评估语言模型对事实知识时间维度的处理能力。该数据集基于Wikidata知识库构建,包含超过52万条自然语言陈述,涵盖1883个独特实体和86种关系,每条事实均标注有效时间段并转化为问答形式。研究团队通过控制时间上下文的相对位置(正确、错误、过渡)和粒度(年、年月、年月日),为语言模型的时序推理能力提供了标准化测试基准。这一创新性设计填补了语言模型在时间敏感性评估方面的空白,为知识表示、时序推理等NLP核心领域的研究提供了重要工具。
当前挑战
该数据集面临双重挑战:在领域问题层面,语言模型对时间敏感事实的识别存在显著困难,尤其当时间上下文与事实有效期存在部分重叠或粒度差异时,模型表现波动较大;在构建过程中,需平衡事实的流行度与时间跨度,确保样本既具有代表性又不失挑战性。此外,自然语言陈述的生成需要严格遵循时间逻辑一致性,这对自动生成系统的语义控制能力提出了极高要求。数据集仅包含2021年前的历史事实,也限制了其对新兴时间敏感任务的适用性。
常用场景
经典使用场景
在自然语言处理领域,TimeStress数据集被广泛应用于评估语言模型对时间敏感事实的理解能力。通过系统性地构建不同时间粒度的上下文情境,该数据集能够精确测试模型在区分正确与错误时间背景方面的表现,为时间推理研究提供了标准化基准。
解决学术问题
TimeStress有效解决了语言模型时间敏感性评估的量化难题。其精心设计的时序标注框架,使得研究者能够深入分析模型在知识时效性、时间粒度变化等方面的认知局限,推动了时间感知语言模型的理论发展。该数据集填补了传统知识评估忽视时间维度的重要空白。
实际应用
在实际应用中,TimeStress为构建时间敏感的问答系统提供了关键测试平台。金融、医疗等领域需要处理时效性极强的专业知识,基于该数据集优化的模型能够更准确地识别过期信息,避免因时间错位导致的错误决策,显著提升了行业知识系统的可靠性。
数据集最近研究
最新研究方向
在自然语言处理领域,TimeStress数据集的推出为评估语言模型在时间推理和事实知识关联方面的鲁棒性提供了重要工具。该数据集通过系统性地标注事实的有效期,并生成不同时间粒度的自然语言陈述,使得研究者能够深入探究语言模型在处理时间上下文时的表现。前沿研究主要聚焦于如何提升模型对时间敏感事实的理解能力,尤其是在面对时间上下文变化时的稳定性。随着大语言模型在知识密集型任务中的广泛应用,TimeStress为评估模型在时间维度上的知识一致性提供了标准化基准。相关研究还探讨了模型在不同时间粒度下的表现差异,以及如何通过时间感知的预训练策略来增强模型的时间推理能力。这些研究不仅推动了时间敏感语言模型的发展,也为知识表示和时间推理的交叉研究开辟了新方向。
以上内容由遇见数据集搜集并总结生成


