UAE-corptax-training
收藏Hugging Face2025-12-26 更新2025-12-27 收录
下载链接:
https://huggingface.co/datasets/vikramlingam/UAE-corptax-training
下载链接
链接失效反馈官方服务:
资源简介:
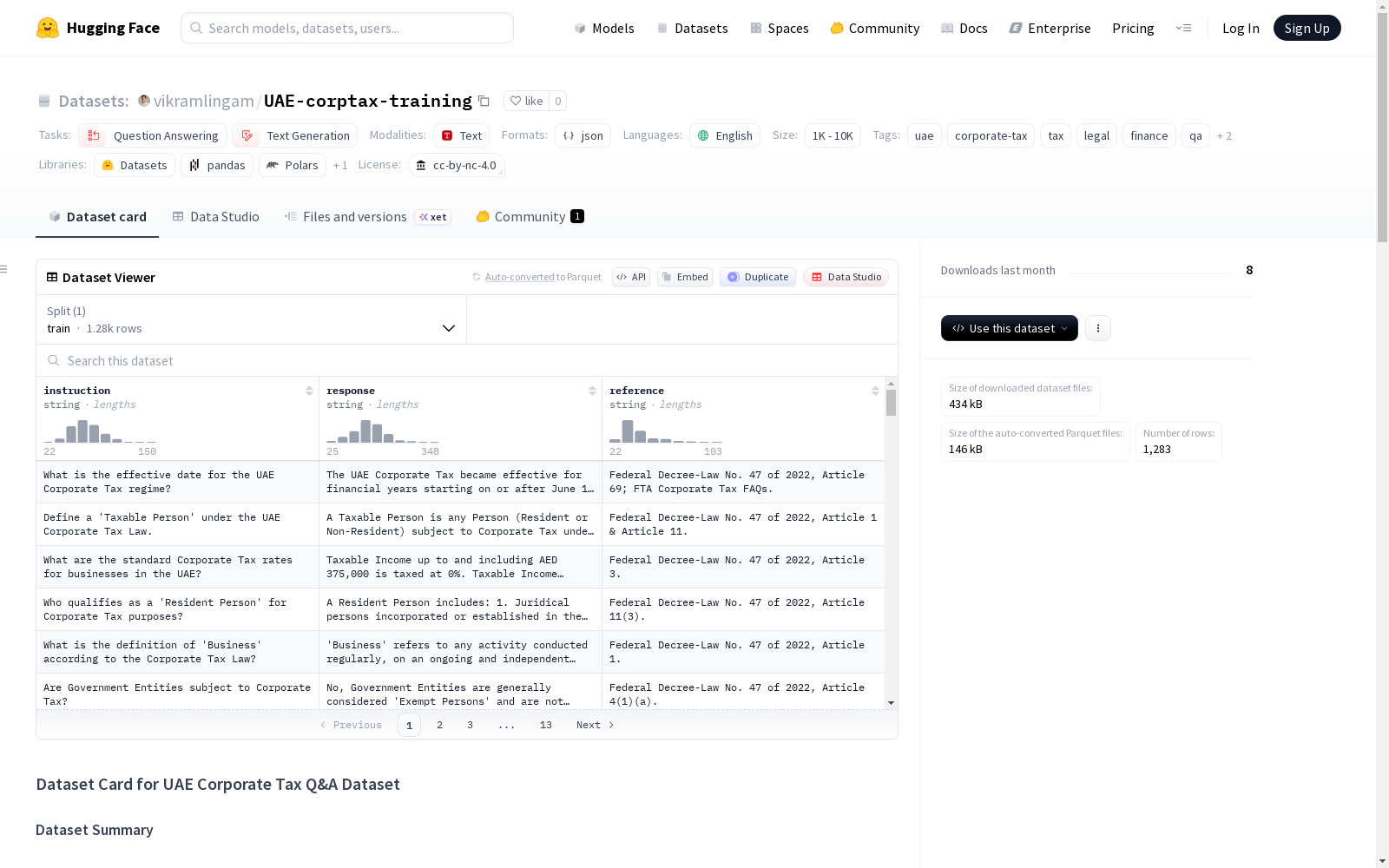
该数据集包含1,283个指令-响应对,覆盖了2022-2025年阿联酋公司税法规。每个响应都包含适当的法律引用。适用于微调大型语言模型用于阿联酋税务咨询、构建检索增强生成(RAG)系统或培训税务合规工具。数据集基于官方公开来源构建,生成过程包括下载官方文档、分块处理、生成问答对并确保法律引用的准确性。注意:数据集仅用于教育和AI模型训练目的,不构成专业税务建议。
This dataset contains 1,283 instruction-response pairs, covering corporate tax regulations in the United Arab Emirates (UAE) from 2022 to 2025. Each response includes appropriate legal citations. It is suitable for fine-tuning large language models (LLMs) for UAE tax consultation, building retrieval-augmented generation (RAG) systems, or training tax compliance tools. The dataset is constructed based on official public sources, and its generation process includes downloading official documents, chunking processing, generating question-answer pairs, and ensuring the accuracy of legal citations. Note: This dataset is for educational and AI model training purposes only and does not constitute professional tax advice.
创建时间:
2025-12-25
原始信息汇总
UAE Corporate Tax Q&A 数据集概述
数据集基本信息
- 数据集名称: UAE Corporate Tax Q&A Dataset
- 语言: 英语
- 许可证: CC-BY-NC-4.0
- 任务类别: 问答、文本生成
- 标签: 阿联酋、企业所得税、税务、法律、金融、问答、指令微调、税务合规
- 规模: 1K<n<10K
- 数据实例总数: 1,283 个独特条目
数据集内容与结构
数据摘要
该数据集包含 1,283 个指令-响应对,涵盖 2022 年至 2025 年的阿联酋企业所得税法规。数据源自多个官方来源。每个响应均包含适当的法律引用。
支持的任务
- 指令遵循:训练模型以准确回答阿联酋税务问题。
- 问答:用于聊天机器人和咨询系统的税务特定问答。
- 信息检索:用于税务合规工具的 RAG 增强。
数据实例结构
每个数据实例包含以下字段:
instruction: 关于阿联酋企业所得税的问题或查询。response: 包含解释和示例的答案。reference: 指向官方来源的法律引用。
数据划分
未提供预定义的训练/测试划分,用户应根据自身需求进行划分。
数据集创建
数据来源
基于公开可用的官方来源构建。
数据收集与处理流程
- 下载阿联酋官方税务 PDF 和文本文档。
- 将文档分块以便处理。
- 使用本地嵌入模型创建向量嵌入。
- 存储在本地向量数据库中。
- 使用 x-ai/grok-4.1-fast 根据分块内容生成问答对。
- 确保每个响应包含正确的法律引用。
标注说明
无人工标注。使用 x-ai/grok-4.1-fast 通过提示工程生成,以确保准确性和正确的引用格式。
使用注意事项
已知偏差
- 数据集反映了截至 2025 年 12 月的阿联酋政府官方立场和解释。
- 可能未涵盖 500 多页 FTA 指南中的每个边缘案例。
- 部分响应倾向于简洁而非详尽解释。
- 约 15 个条目使用了生成时的临时性语言,未来可能需要更新。
其他已知限制
- 不构成专业税务建议。
- 未深入涵盖国际税收条约的影响。
- 未包含 2025 年 12 月之后发布的新 FTA 指南。
- 部分条目响应非常简短。
用户在生产使用前,应针对关键信息核对官方 FTA 来源。
附加信息
数据集维护者
由 vikramlingam 使用公开的官方税务来源创建。
贡献
欢迎通过拉取请求提交错误或更新的 FTA 指南。
免责声明:此数据集仅用于 AI 模型训练和教育目的。不构成专业税务建议。具体税务事宜请务必咨询合格的税务顾问或直接联系 FTA。
搜集汇总
数据集介绍
构建方式
在税务合规与法律咨询领域,高质量的数据集对于训练专业语言模型至关重要。UAE Corporate Tax Q&A Dataset的构建过程体现了严谨的数据工程方法:首先从阿联酋联邦税务局(FTA)发布的官方PDF与文本文件中提取原始内容,随后通过文档分块技术将冗长的法律文本分割为可处理的片段。利用本地嵌入模型生成向量表示并存储于向量数据库中,最终借助x-ai/grok-4.1-fast模型通过提示工程自动生成问答对。每个回答均严格附有法律条文引用,确保信息溯源至《2022年第47号联邦法令》等权威来源,实现了自动化流程与法律准确性的平衡。
特点
该数据集的核心价值在于其专业性与结构化设计。1283条指令-响应对全面覆盖2022至2025年阿联酋企业所得税法规,每条回答均包含具体法律条款索引,如'Article 3'等精确引用,为法律可解释性提供支撑。数据内容聚焦税率计算、合规要求等实务场景,同时标注了大型跨国企业可能适用的15%全球最低税等特殊条款。尽管部分条目存在表述简略或时间性语言局限,但整体上构建了层次清晰的税务知识体系,特别适合作为检索增强生成(RAG)系统的专业语料库。
使用方法
在人工智能驱动的税务咨询系统开发中,本数据集可服务于多阶段模型训练。开发者可将其用于指令微调,使语言模型掌握阿联酋税法的专业表述框架;也可作为检索增强生成系统的核心知识库,通过向量相似度匹配实现动态法规查询。实际应用时建议根据具体场景划分训练集与验证集,并注意结合2025年后FTA的最新指南进行内容更新。需强调的是,所有输出均应通过官方渠道二次核验,因其设计初衷为教育研究与模型优化,而非替代专业税务顾问的法律效力。
背景与挑战
背景概述
随着全球数字经济的蓬勃发展,税务合规与法律咨询领域对智能化工具的需求日益增长。在此背景下,UAE-corptax-training数据集应运而生,由研究者vikramlingam于2025年前后构建,专注于阿联酋企业所得税法规的智能问答任务。该数据集基于2022至2025年间的官方税务文件,旨在通过指令微调提升大型语言模型在税务咨询、合规工具及检索增强生成系统中的专业性能,为金融科技与法律人工智能领域提供了重要的数据支撑。
当前挑战
该数据集致力于解决税务法律领域的复杂问答挑战,其核心在于准确解析多变的法规条文并提供权威引用,这要求模型具备深度的法律语义理解与实时更新能力。在构建过程中,挑战主要源于官方文档的庞杂性,需从数百页指南中提取有效信息并生成精确的问答对,同时确保引用格式的规范性;此外,数据生成依赖自动化流程,可能遗漏边缘案例,且部分内容存在时效性局限,需持续跟踪法规变更以维持数据可靠性。
常用场景
经典使用场景
在税务合规与法律智能领域,UAE Corporate Tax Q&A Dataset 为大型语言模型的指令微调提供了精准的语料基础。该数据集通过涵盖阿联酋2022至2025年企业税法规的指令-响应对,使模型能够学习如何依据官方法律条文生成准确、可溯源的税务解答。这一场景典型应用于构建专业税务问答系统,模型经过微调后,可模拟税务顾问的推理过程,针对复杂的企业税问题提供结构清晰且附带法律引用的回答,从而在合规咨询场景中实现高效的信息交付。
解决学术问题
该数据集直接应对了法律与金融文本理解中准确性与可解释性并重的核心学术挑战。它通过提供带有严格法律引证的问答对,为研究如何使语言模型生成可靠、可验证的专业内容提供了实验基准。其意义在于推动了法律人工智能领域在事实一致性、领域知识融合以及减少模型幻觉方面的进展,使得模型不仅能理解一般语言,还能掌握特定司法管辖区下精密的法律条文与官方解释,为构建可信赖的专业领域助手奠定了数据基础。
衍生相关工作
围绕该数据集,已衍生出专注于法律垂直领域模型优化的系列工作。例如,研究者利用其进行对比学习或领域自适应预训练,以提升模型对税务术语和法规逻辑的捕捉能力。同时,它常作为基准数据集,用于评估检索增强生成系统在法律问答任务中的表现,特别是检验系统检索相关法条并生成准确摘要的能力。这些工作共同推动了法律人工智能从通用对话向高精度、高可靠性专业服务的技术演进,并激发了针对其他司法管辖区创建类似高质量专业数据集的趋势。
以上内容由遇见数据集搜集并总结生成


