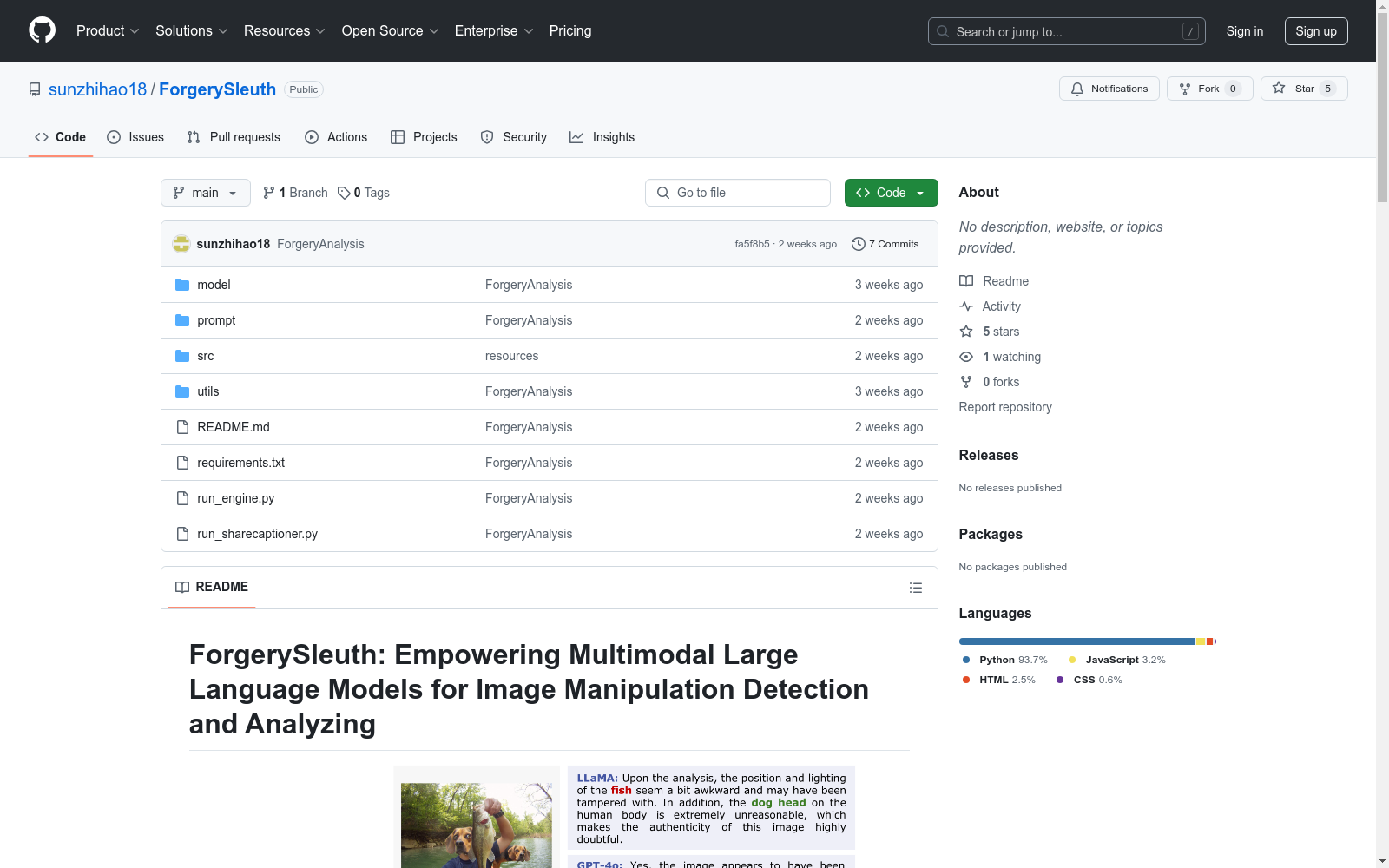
ForgeryAnalysis-PT
收藏ForgerySleuth: 图像篡改检测与分析的多模态大语言模型
摘要
本研究探索了多模态大语言模型在图像篡改检测任务中的潜力。我们构建了ForgeryAnalysis数据集,包含篡改分析文本注释。每个条目最初由GPT-4生成,并由专家审查。提出的数据引擎ForgeryAnalyst能够创建更大规模的ForgeryAnalysis-PT数据集用于预训练。我们还提出了ForgerySleuth,利用多模态大语言模型进行全面的线索融合,并生成指示特定篡改区域的分割输出。
ForgeryAnalysis 数据集
ForgeryAnalysis-PT
概述
ForgeryAnalysis-PT数据集由我们的数据引擎ForgeryAnalyst自动生成的篡改分析文本组成。该数据集对应于两个公开的图像篡改检测数据集:CASIA2和MIML。每个条目为对应的篡改图像提供篡改分析,包括线索和解释,结构化为Chain-of-Clues格式。
使用
在使用此数据集之前,请从各自的公开仓库下载原始的CASIA2和MIML数据集,因为ForgeryAnalysis-PT依赖于这些数据集中的对应篡改图像。
每个图像的篡改分析保存为与原始CASIA2和MIML数据集中篡改图像同名的.txt文件。您可以通过以下链接下载此数据集:Google Drive。
许可证
ForgeryAnalysis-PT数据集可免费用于学术研究和开发。但是,您必须遵守原始数据集CASIA2和MIML的条款和条件。
评估数据集
我们使用了几个公开的、广泛使用的图像篡改检测数据集来评估IMD方法的性能。您可以通过以下链接访问原始仓库并下载数据:
| 数据集 | 论文 | 下载URL |
|---|---|---|
| Columbia | Detecting Image Splicing Using Geometry Invariants And Camera Characteristics Consistency | https://www.ee.columbia.edu/ln/dvmm/downloads/authsplcuncmp |
| CASIA | Casia image tampering detection evaluation database | [Unofficial] https://github.com/namtpham/casia1groundtruth |
| [Unofficial] https://github.com/namtpham/casia2groundtruth | ||
| Coverage | COVERAGE - A Novel Database for Copy-move Forgery Detection | https://github.com/wenbihan/coverage |
| NIST16 | MFC Datasets: Large-Scale Benchmark Datasets for Media Forensic Challenge Evaluation | https://mfc.nist.gov/users/sign_in |
| IMD20 | IMD2020: A Large-Scale Annotated Dataset Tailored for Detecting Manipulated Images | https://staff.utia.cas.cz/novozada/db |
| COCOGlide | TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization | https://github.com/grip-unina/TruFor?tab=readme-ov-file#cocoglide-dataset |
引用
如果您发现此项目对您的研究和应用有用,请使用以下BibTeX进行引用:
@misc{sun2024forgerysleuth, title={ForgerySleuth: Empowering Multimodal Large Language Models for Image Manipulation Detection}, author={Sun, Zhihao and Jiang, Haoran and Chen, Haoran and Cao, Yixin and Qiu, Xipeng and Wu, Zuxuan and Jiang, Yu-Gang}, publisher={arXiv:2411.19466}, year={2024}, url={https://arxiv.org/abs/2411.19466}, }