u2-bench
收藏Hugging Face2025-05-21 更新2025-05-22 收录
下载链接:
https://huggingface.co/datasets/DolphinAI/u2-bench
下载链接
链接失效反馈官方服务:
资源简介:
U2-BENCH是一个首个用于评估大型视觉语言模型在超声成像理解上的大规模多任务基准数据集,包含15个解剖区域和8个临床启发的任务,适用于分类、检测、回归和文本生成。
U2-BENCH is the first large-scale multi-task benchmark dataset for evaluating large vision-language models on ultrasound imaging understanding. It encompasses 15 anatomical regions and 8 clinically inspired tasks, covering classification, detection, regression, and text generation.
创建时间:
2025-05-13
原始信息汇总
U2-BENCH: Ultrasound Understanding Benchmark 数据集概述
基本信息
- 许可证: Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0)
- 任务类别: 问答
- 语言: 英语
- 标签: 医学
- 规模: 1K<n<10K
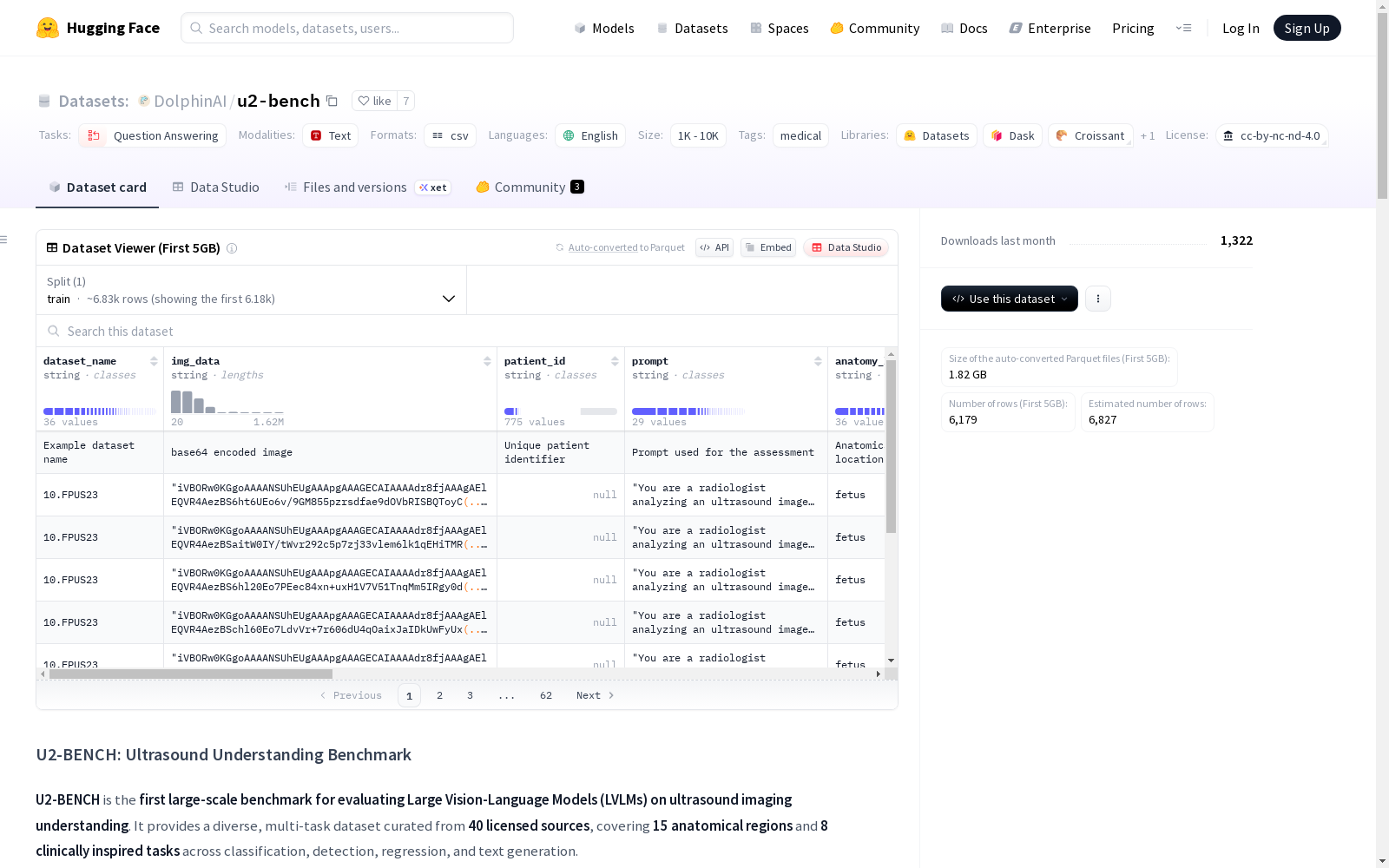
数据集结构
- 组织方式: 8个文件夹,每个对应一个基准任务
caption_generation/clinical_value_estimation/disease_diagnosis/keypoint_detection/lesion_localisation/organ_detection/report_generation/view_recognition_and_assessment/
- 注释文件:
an_explanation_of_the_columns.tsv解释各列含义
数据格式
- 文件类型:
.tsv文件 - 关键字段:
img_data: base64编码的图像(通常来自超声视频的2D帧)- 其他字段包括
dataset_name,anatomy_location,classification_task,caption,report,class_label,measurement,gt_bbox,keypoints等
任务列表
| 能力 | 任务名称 | 描述 |
|---|---|---|
| 分类 | 疾病诊断 (DD) | 从超声预测临床诊断 |
| 分类 | 视图识别 (VRA) | 分类超声检查中的标准视图 |
| 检测 | 病变定位 (LL) | 定位病变并进行空间分类 |
| 检测 | 器官检测 (OD) | 识别解剖结构的存在 |
| 检测 | 关键点检测 (KD) | 预测解剖标志(如生物测量) |
| 回归 | 临床价值估计 | 估计标量指标(如脂肪百分比、EF) |
| 生成 | 报告生成 | 生成结构化的临床超声报告 |
| 生成 | 描述生成 | 生成简短的解剖图像描述 |
数据集统计
- 总样本数: 7,241
- 解剖区域: 15个(如甲状腺、胎儿、肝脏、乳房、心脏、肺)
- 应用场景: 50个跨任务场景
- 多任务支持: 部分样本包含多个标签(如分类+回归)
伦理与使用
- 用途限制: 仅限非商业研究和评估
- 数据来源: 来自许可和公开可用的超声数据集
- 隐私保护: 所有图像均已去标识化,注释经过人工验证
- 临床使用警告: 未经监管批准不得用于诊断或临床部署
加载方式
使用 🤗 Datasets 加载数据集: python from datasets import load_dataset dataset = load_dataset("DolphinAI/u2-bench", split="train")
引用
bibtex @article{le2025u2bench, title={U2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding}, author={Le, Anjie and Liu, Henan and others}, journal={Under Review}, year={2025} }
贡献
欢迎社区贡献和评估脚本,可通过提交拉取请求或联系 Dolphin AI 进行合作。
搜集汇总
数据集介绍
构建方式
在医学影像分析领域,U2-BENCH数据集的构建采用了系统性整合策略,从40个经过严格授权的超声影像数据源中筛选出涵盖15个解剖区域的多样化样本。通过专业医学标注团队对7241个样本进行多维度标注,构建了包含分类、检测、回归与文本生成在内的8类临床任务框架,每个样本均以TSV格式存储基64编码图像及结构化注释,确保了数据来源的合规性与标注质量的可靠性。
特点
作为首个大规模超声影像理解基准,该数据集最显著的特点是实现了多模态任务的深度融合,其样本同时覆盖甲状腺、胎儿、心脏等15个解剖部位,并支持单样本多标签标注机制。数据集通过50种应用场景的精心设计,将临床诊断需求转化为可量化的评估任务,包括病灶定位、生物测量等8类核心能力验证,为视觉语言模型提供了接近真实医疗场景的评估环境。
使用方法
研究者可通过Hugging Face平台直接加载数据集进行模型评估,使用标准接口即可获取包含基64编码图像与多维注释的完整样本。针对不同任务需求,数据集按8个独立目录组织,每个目录的TSV文件均配有详细的列说明文档。评估过程建议结合官方发布的两种评测工具包,通过任务特定的指标对模型在疾病诊断、报告生成等临床任务上的表现进行系统性验证。
背景与挑战
背景概述
医学影像分析领域长期面临多模态数据融合的挑战,U2-BENCH作为首个大规模超声影像理解基准数据集于2025年问世,由Dolphin AI团队主导构建。该数据集整合了40个授权来源的7241个样本,涵盖甲状腺、胎儿、肝脏等15个解剖区域,通过8项临床任务系统评估大视觉语言模型在分类、检测、回归及文本生成等方面的综合能力。其创新性在于将传统超声诊断流程转化为标准化机器学习任务,为智能辅助诊断系统的开发提供了关键基础设施。
当前挑战
超声影像理解需克服模态特异性带来的技术障碍:图像中组织边界模糊性与伪影干扰对病变定位精度形成严峻考验;多解剖区域的结构差异要求模型具备跨域泛化能力。在数据构建层面,临床标注依赖专业医师知识,标注一致性保障与隐私脱敏处理构成双重挑战。此外,生成式任务需平衡医学术语准确性与自然语言流畅性,而严格的非商业许可协议限制了临床场景的直接应用。
常用场景
经典使用场景
在医学影像分析领域,U2-BENCH数据集作为首个大规模超声图像理解基准,主要应用于评估大型视觉语言模型的多模态能力。其经典使用场景涵盖从甲状腺、胎儿到心脏等15个解剖区域的超声图像分析,支持分类、检测、回归与生成等八类临床任务,为模型在真实医疗环境中的泛化性能提供标准化测试平台。
解决学术问题
该数据集有效解决了医学人工智能领域缺乏标准化超声评估体系的学术难题。通过整合40个授权来源的7241个样本,它建立了跨解剖区域与任务类型的统一评估框架,显著提升了模型在疾病诊断、病灶定位等关键任务中的可复现性与可比性,推动了超声影像分析从单一任务向多任务协同研究的范式转变。
衍生相关工作
该基准已催生多项医学多模态研究的经典工作。基于其构建的评估体系,研究者开发了专用于超声报告的生成模型、融合解剖先验的检测网络,以及面向临床价值估计的回归架构。这些衍生工作通过开源评测工具包持续扩展,形成了超声影像理解领域的技术演进脉络。
以上内容由遇见数据集搜集并总结生成


