blended-skill-talk
收藏Hugging Face2025-11-10 更新2025-11-10 收录
下载链接:
https://huggingface.co/datasets/anezatra/blended-skill-talk
下载链接
链接失效反馈官方服务:
资源简介:
Blended Skill Talk数据集包含了两个角色之间的对话,附加上下文、前一个发言、自由消息、引导消息、建议以及选择的建议,这些对话旨在创建具有个性、同理心和知识的自然多模态对话。该数据集用于评估对话系统在对话流程管理、话题控制和对话连贯性等方面的全面技术能力,并用于探索不同对话风格对用户参与度的影响。此外,该数据集还有助于在不同模态之间验证分布式对话系统,揭示不同上下文中的潜在偏见,并用于与类似领域的数据集进行基准测试,以开发能够随时间有效评估战术技能对话表现的自动评估系统。
The Blended Skill Talk dataset comprises dialogues between two characters, paired with supplementary elements including context, preceding utterances, free messages, guiding messages, suggestions, and selected recommendations. These dialogues are intended to produce natural multimodal conversations that exhibit personality, empathy, and domain-specific knowledge. This dataset is employed to evaluate the comprehensive technical capabilities of dialogue systems across key dimensions such as dialogue flow management, topic control, and dialogue coherence, as well as to investigate the effects of diverse dialogue styles on user engagement. Additionally, this dataset supports the validation of distributed dialogue systems across modalities, uncovers latent biases in various contexts, and acts as a benchmark for comparative evaluation with datasets in analogous domains, enabling the development of automated evaluation systems that can effectively assess the performance of tactical skill-based dialogues over time.
创建时间:
2025-11-08
原始信息汇总
Blended Skill Talk 数据集概述
数据集简介
该数据集包含两个角色之间的对话,附带额外上下文、先前话语、自由消息、引导消息、建议和引导选择建议,用于创建具有个性、同理心和知识的自然多模态对话。对话设计用于衡量全方位的技术能力,包括对话流程管理、主题控制和对话连贯性。同时为探索不同对话风格对用户参与度的影响提供基础。此外,该任务可用于验证跨多种模态的分布式对话系统,并揭示不同上下文中存在的潜在偏见。最后,支持对类似领域数据集进行基准测试,以开发自动评估系统来有效评估战术技能对话表现。
数据结构
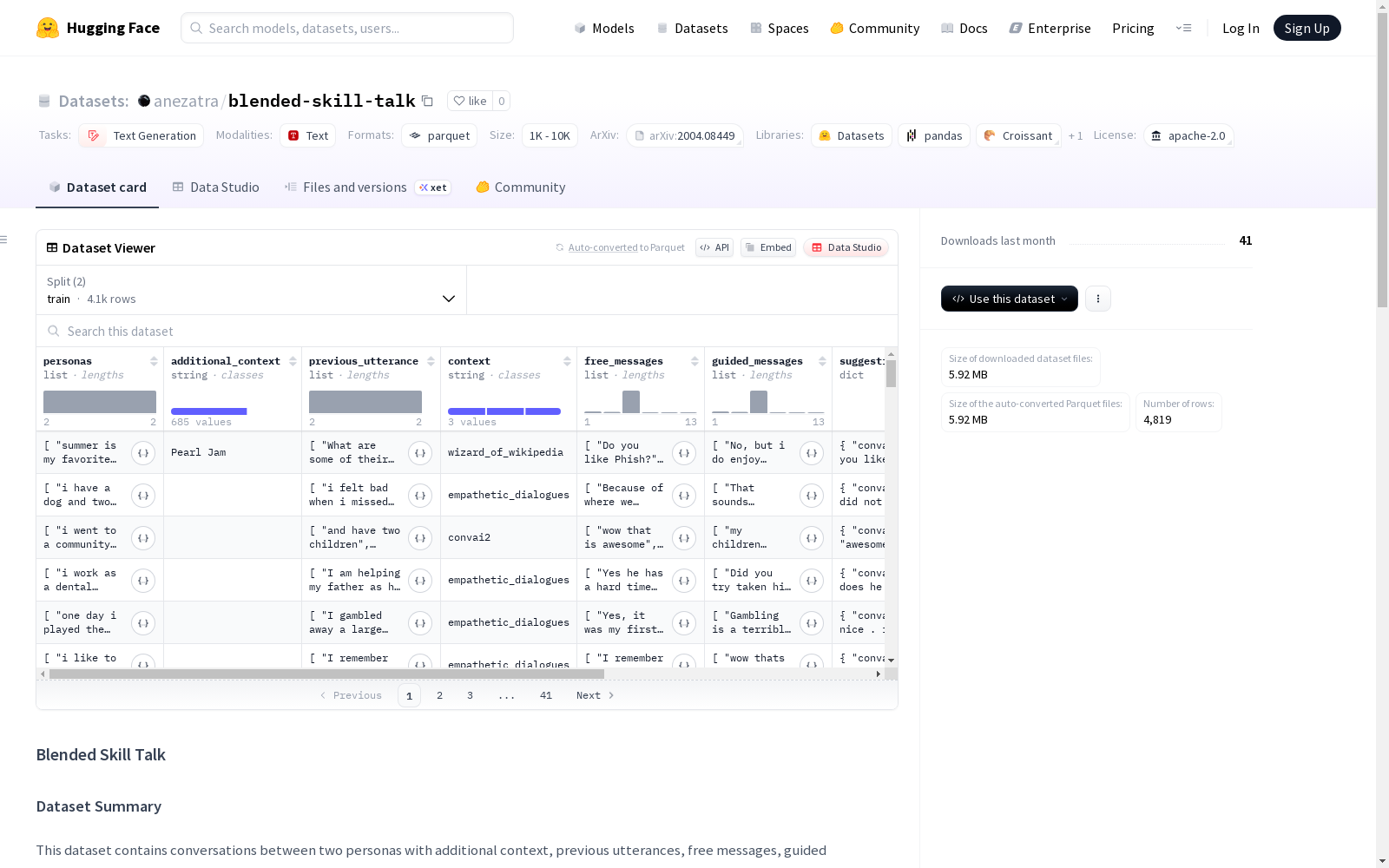
数据特征
- personas:参与对话的角色列表
- additional_context:额外上下文或场景描述
- previous_utterance:紧接在前的对话轮次
- context:通用对话上下文
- free_messages:自由形式的用户或系统消息
- guided_messages:通过引导提示生成的消息
- suggestions:来自ConvAI2、Empathetic Dialogues和Wizard of Wikipedia的建议回复
- guided_chosen_suggestions:对话中实际使用的选定建议
- label_candidates:可选候选标签(本数据集中为null)
数据划分
| 划分 | 样本数量 | 数据大小 | 用途 |
|---|---|---|---|
| 训练集 | 4,096 | 9,201,244字节 | 模型训练 |
| 验证集 | 723 | 1,629,426字节 | 验证和调参 |
总数据集大小: 10,830,670字节
总对话数量: 4,819
使用示例
python from datasets import load_dataset
ds = load_dataset("anezatra/blended-skill-talk", split="train") print(ds[0])
技术信息
- 许可证: Apache-2.0
- 任务类别: 文本生成
- 规模类别: 1K<n<10K
参考文献
Smith, E. M., Williamson, M., Shuster, K., Weston, J., & Boureau, Y. L. (2020). Can You Put it All Together: Evaluating Conversational Agents Ability to Blend Skills. arXiv preprint arXiv:2004.08449. (https://arxiv.org/abs/2004.08449)
搜集汇总
数据集介绍
构建方式
在对话系统研究领域,blended-skill-talk数据集通过精心设计的对话流程构建而成。该数据集整合了4096个训练样本和723个验证样本,每个对话实例包含人物角色设定、附加背景信息及历史对话记录。构建过程中采用多源建议机制,融合了ConvAI2、Empathetic Dialogues和Wizard of Wikipedia三个知名对话数据集的响应建议,通过自由对话与引导对话相结合的方式,确保对话兼具个性特征、情感共鸣与知识深度。
特点
该数据集最显著的特点在于其多维度的技能融合架构。对话内容同时涵盖人物性格塑造、情感认知与知识传递三大维度,每个对话回合均配备来自不同领域的响应建议。数据结构设计科学严谨,包含人物角色序列、上下文语境、自由消息与引导消息等丰富字段,为研究多模态对话交互提供了完整的信息基础。这种复合型结构使得该数据集能有效评估对话系统在话题连贯性、情感响应和知识准确性等方面的综合表现。
使用方法
在实际应用层面,研究人员可通过HuggingFace平台便捷加载该数据集进行模型训练与验证。使用时可重点关注对话流程管理、话题控制与响应一致性等核心指标。该数据集特别适用于评估分布式对话系统的多模态交互能力,通过分析引导选择建议与实际对话的对应关系,能够深入探究不同对话策略对用户参与度的影响。验证集的设计则为模型超参数调优和性能基准测试提供了可靠依据。
背景与挑战
背景概述
对话系统研究领域长期致力于开发能够整合多种交流能力的智能体,Blended Skill Talk数据集于2020年由Meta AI研究院团队主导构建,核心目标在于解决开放域对话中技能融合的复杂性。该数据集通过设计包含人物角色、情感共鸣与知识传递的多轮对话,为评估对话系统在个性表达、共情互动及事实准确性方面的综合表现提供了基准。其创新性地融合了ConvAI2、Empathetic Dialogues和Wizard of Wikipedia三大经典数据集的核心特征,推动了自然语言处理领域从单一技能评估向多维能力整合的范式转变。
当前挑战
在对话系统领域,实现个性、共情与知识的有机融合始终是核心难题,具体表现为对话连贯性维护、多主题平滑切换以及动态上下文理解的技术瓶颈。数据集构建过程中面临多重挑战:首先需协调不同对话数据集间的标注标准差异,确保角色设定与知识背景的逻辑一致性;其次在数据采集时需平衡自由对话与引导式响应的比例,避免模型过度依赖预设模板;最后在标注阶段需解决多源建议的筛选与整合问题,确保每轮对话同时具备自然流畅性与技能多样性特征。
常用场景
经典使用场景
在对话系统研究领域,blended-skill-talk数据集通过融合人物角色设定、上下文背景及多源建议机制,为构建具备个性化、共情能力和知识储备的自然对话模型提供了标准测试平台。其典型应用体现在评估智能体在连续对话中维持话题连贯性、管理对话流程以及平衡情感表达与事实准确性的综合能力,常被用于训练端到端的生成式对话系统。
衍生相关工作
基于该数据集衍生的经典研究包括Smith等人提出的多技能对话评估框架,其通过分层解码机制实现了知识、情感与人格特征的动态平衡。后续工作如动态注意力网络与元学习策略的引入,进一步拓展了跨领域对话迁移的学习范式,相关成果已成为ACL、EMNLP等顶级会议中对话生成任务的重要基线模型。
数据集最近研究
最新研究方向
在对话系统研究领域,blended-skill-talk数据集正推动多技能融合的前沿探索。该数据集通过整合角色扮演、共情回应与知识注入三大对话能力,为构建具备人类特质的智能体提供了关键实验基础。当前研究聚焦于跨模态对话的连贯性优化,利用其结构化建议机制探索上下文感知的响应生成,尤其在消除对话偏见和提升长程交互一致性方面成果显著。随着个性化人机交互需求日益增长,该数据集已成为验证分布式对话系统效能的重要基准,持续推动着自动评估体系与多技能协同理论的创新发展。
以上内容由遇见数据集搜集并总结生成


