uznlp-uz/UzEDSA
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/uznlp-uz/UzEDSA
下载链接
链接失效反馈官方服务:
资源简介:
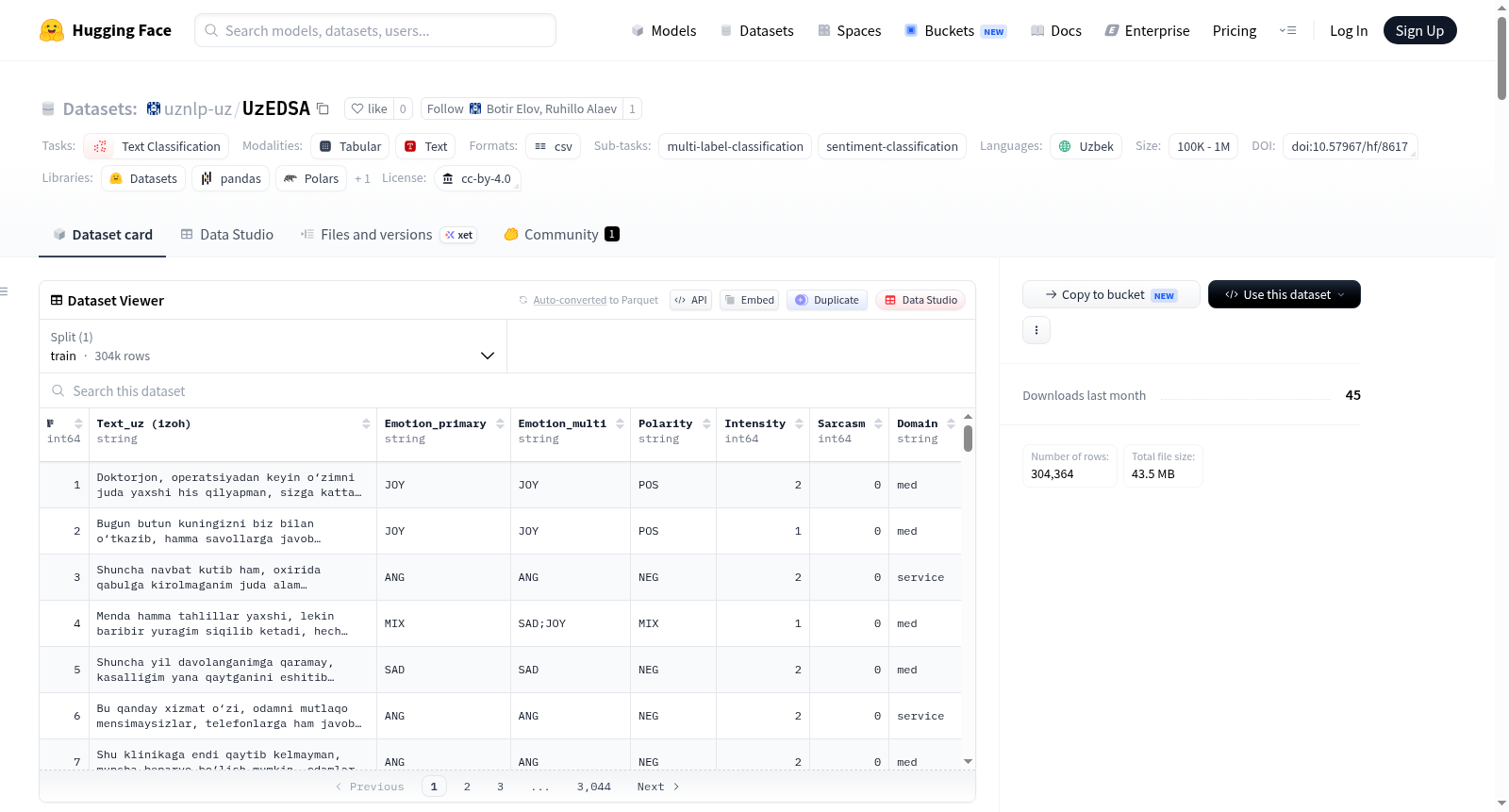
UzEDSA是一个用于**情感检测**和**情感分析**的大规模乌兹别克语数据集。当前版本包含**304,364**条带注释的行,涵盖九个领域的文本。每行包括:- 一个自由格式的乌兹别克语文本片段 - 一个主要情感标签 - 一个多标签情感注释(分号分隔) - 一个三向情感极性标签 - 一个情感强度分数 - 一个讽刺标志 - 一个领域标签。注释方案遵循Plutchik的八种基本情感,扩展了中性和混合类别。
UzEDSA is a large-scale Uzbek dataset for **emotion detection** and **sentiment analysis**. The current release contains **304,364** annotated rows in a single TSV file, covering texts from nine domains. Each row includes: - a free-form Uzbek text snippet - a primary emotion label - a multi-label emotion annotation (semicolon-separated) - a 3-way sentiment polarity label - an emotion intensity score - a sarcasm flag - a domain tag. The annotation scheme follows Plutchiks eight basic emotions extended with a neutral and a mixed category.
提供机构:
uznlp-uz
搜集汇总
数据集介绍
构建方式
UzEDSA是一个面向乌兹别克语的大规模情感与情绪分析数据集,其构建基于对来自九个领域(如医疗、教育、交通等)的自由文本进行系统化标注。数据集的注释体系以Plutchik的八种基本情绪理论为框架,并扩展了中性(NEU)和混合(MIX)类别,最终形成10类单标签情绪、多标签情绪组合、3类情感极性、0至2级的情绪强度以及讽刺标记。所有标注以制表符分隔的TSV格式存储,共计304,364条记录,当前版本仅包含训练集。
使用方法
使用者可通过HuggingFace Datasets库便捷加载UzEDSA。推荐采用两种方式:其一,从本地TSV文件读取,需指定分隔符为制表符并设置编码为utf-8-sig;其二,直接从HuggingFace Hub调用数据集标识符'uznlp-uz/UzEDSA'。加载后的数据集对象包含训练集,可通过索引访问单条样本,其列包括文本、主情绪、多标签情绪、极性、强度、讽刺标志及领域。该数据集适用于单标签情绪分类、多标签情绪检测、情感分类和讽刺检测四项任务,研究人员可根据需求选择相应的标注列作为目标变量。
背景与挑战
背景概述
UzEDSA是由乌兹别克斯坦自然语言处理研究团队于近期构建的大规模乌兹别克语情感与情绪分析数据集,涵盖304,364条来自九个领域的文本标注样本。该数据集基于Plutchik的八种基本情绪理论,扩展出中性及混合类别,提供了单标签情绪分类、多标签情绪检测、情感极性分析和讽刺检测等多重任务支持。其创建填补了低资源语言在情绪计算领域的空白,为乌兹别克语社交媒体分析、用户反馈挖掘和公共舆情监控等应用奠定了数据基础,推动了中亚语言情感计算研究的发展。
当前挑战
该数据集面临的核心挑战包括:1)情绪与情感分析的领域适配性——乌兹别克语缺乏大规模标注资源,现有模型多依赖英语数据,跨语言迁移时面临文化表达差异和词汇稀疏问题,导致情绪标签分布不均(如恐惧、信任类样本不足2%);2)构建过程中的标注复杂性——多标签情绪标注需同时识别10类情绪与4类极性,标注者需处理讽刺、混合情绪等语义模糊现象,讽刺样本仅占0.6%,加剧了模型对少数类别的学习困难;此外,九大领域间的文本风格差异(如医疗与营销)要求标注方案具备领域鲁棒性。
常用场景
经典使用场景
UzEDSA作为首个大规模乌兹别克语情感与情绪检测数据集,为低资源语言的自然语言处理研究奠定了坚实基础。其经典使用场景聚焦于情感分类与情绪识别任务,涵盖单标签情绪分类、多标签情绪检测、情感极性分析以及讽刺检测四大核心方向。研究者可借助该数据集中标注的情绪主标签、多标签组合、情感极性、强度评分及讽刺标记等丰富维度,构建面向乌兹别克语的文本情感理解模型。数据集覆盖通用、医疗、教育、交通等九个领域,确保了模型在不同语境下的泛化能力,推动了中亚语言情感分析技术的实质性进展。
解决学术问题
该数据集精准解决了乌兹别克语情感分析领域长期缺乏大规模标注语料的学术困境。传统的跨语言情感模型在该语言上表现欠佳,而UzEDSA提供了30余万条人工标注样本,使研究者能够系统性地探索低资源语言中情绪表达的多样性。它有力支撑了情感极性分类、细粒度情绪识别、多标签情绪检测及讽刺识别等学术问题的深入探究。数据集基于Plutchik心理学理论构建的十类情绪体系,为情感计算的跨文化研究提供了独特视角,显著拓展了自然语言处理在突厥语族语言中的研究边界与应用潜力。
实际应用
在实际应用中,UzEDSA为乌兹别克斯坦及中亚地区的智能化信息服务提供了关键技术支撑。基于该数据集训练的情感分析模型可部署于社交媒体舆情监控系统,实时捕捉公众对政策、医疗、教育等领域的情绪倾向。在电子商务领域,模型能够精准分析用户评论中的情感色彩与讽刺表达,辅助商家优化服务质量。此外,医疗健康平台可利用情绪识别功能自动感知患者评论中的焦虑、信任或不满情绪,及时提供心理支持或服务改进。该数据集还支持多语言情感分析系统的扩展,助力中亚本地化智能服务的全面发展。
数据集最近研究
最新研究方向
UzEDSA作为乌兹别克语领域首个大规模多标签情感与情绪检测数据集,其发布标志着低资源语言在自然语言处理前沿研究中的关键突破。该数据集涵盖了Plutchik八类基本情绪及中性、混合类别,并整合了情感极性、强度与讽刺检测等多维度标注,为构建细粒度情感理解模型提供了坚实的数据基石。当前研究热点集中于利用该资源探索跨域情感迁移学习、多任务联合训练框架,以及针对中亚语言特点的上下文感知情感分类方法。这一成果不仅推动了乌兹别克语人机交互、社交媒体舆情监测和医疗健康情感分析等应用的发展,也为其他突厥语系或资源匮乏语言的情感计算研究树立了范式,具有深远的学术与实践意义。
以上内容由遇见数据集搜集并总结生成


