BlendNet
收藏Hugging Face2024-12-17 更新2024-12-18 收录
下载链接:
https://huggingface.co/datasets/FreedomIntelligence/BlendNet
下载链接
链接失效反馈官方服务:
资源简介:
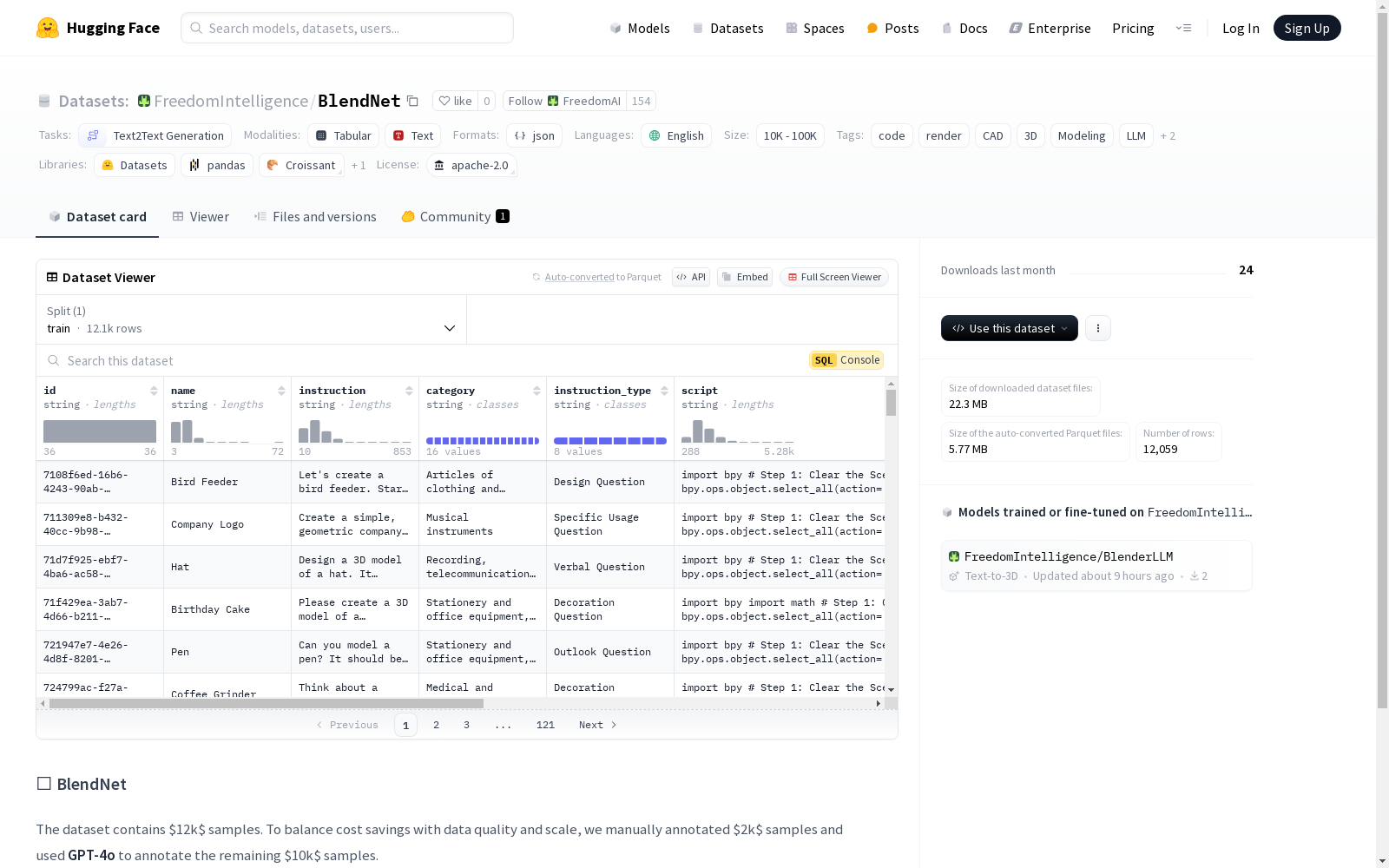
BlendNet数据集包含12,000个样本,用于文本到文本生成任务。数据集中的2,000个样本是手动标注的,以确保高质量,而其余的10,000个样本则由GPT-4o自动标注,以平衡成本和数据规模。该数据集涉及代码、渲染、CAD、3D建模等领域。
The BlendNet dataset consists of 12,000 samples intended for text-to-text generation tasks. Among them, 2,000 samples are manually annotated to ensure high data quality, while the remaining 10,000 samples are automatically annotated using GPT-4o to strike a balance between cost control and dataset scale. This dataset covers multiple domains including coding, rendering, CAD, 3D modeling, and other related fields.
提供机构:
FreedomAI
创建时间:
2024-12-11
原始信息汇总
BlendNet 数据集概述
基本信息
- 许可证: Apache-2.0
- 任务类别: 文本生成
- 语言: 英语
- 标签: 代码, 渲染, CAD, 3D, 建模, LLM, bpy, Blender
- 数据集名称: BlendNet
- 数据集规模: 10K<n<100K
数据集详情
- 样本数量: 12,000
- 标注方式:
- 手动标注: 2,000 样本
- GPT-4o 自动标注: 10,000 样本
相关链接
搜集汇总
数据集介绍
构建方式
BlendNet数据集的构建方式体现了成本与质量的平衡策略。该数据集包含12,000个样本,其中2,000个样本通过人工标注确保高质量,而剩余的10,000个样本则利用GPT-4o进行自动化标注,以提高效率并降低成本。这种混合标注方法不仅确保了数据集的规模,还兼顾了标注的准确性和一致性。
特点
BlendNet数据集的显著特点在于其专注于代码生成与3D建模领域,涵盖了CAD设计、渲染和Blender脚本编写等多个应用场景。数据集的语言以英语为主,且标签丰富,包括代码、渲染、CAD、3D建模等,使其在自然语言处理与计算机图形学交叉领域具有广泛的应用潜力。
使用方法
BlendNet数据集适用于文本到文本生成任务,尤其在代码生成和3D建模领域具有显著的应用价值。用户可以通过加载该数据集进行模型训练,以生成高质量的Blender脚本或CAD设计代码。此外,数据集的多样性和规模使其成为研究自然语言处理与计算机图形学结合的理想选择。
背景与挑战
背景概述
BlendNet数据集由FreedomIntelligence机构主导开发,专注于文本到文本生成任务,特别是在代码生成、渲染、CAD建模和3D建模等领域。该数据集创建于近期,包含12,000个样本,旨在通过结合人工标注与GPT-4o自动标注的方式,平衡数据质量与成本效益。主要研究人员通过精心设计,确保了数据集在规模与质量上的平衡,为相关领域的研究提供了宝贵的资源。BlendNet的推出,不仅丰富了文本生成领域的数据资源,也为3D建模和CAD设计等应用场景提供了新的研究方向。
当前挑战
BlendNet数据集在构建过程中面临多项挑战。首先,如何在有限的预算内实现高质量的数据标注是一个关键问题。为此,研究人员采用了人工标注与GPT-4o自动标注相结合的方式,尽管这种方法提高了效率,但也带来了标注一致性和准确性的挑战。其次,数据集的多样性问题同样不容忽视,如何在12,000个样本中涵盖广泛的3D建模和CAD设计场景,确保数据的代表性和实用性,是另一个重要挑战。此外,随着GPT-4o等大型语言模型的应用,如何评估和保证自动标注的可靠性,也是未来研究中需要解决的问题。
常用场景
经典使用场景
BlendNet数据集在文本到文本生成任务中展现了其独特的应用价值,尤其是在代码生成、3D建模和渲染领域。该数据集通过结合GPT-4o的自动标注与人工校验,提供了高质量的样本,使得其在训练大型语言模型(LLM)以生成精确的3D建模指令和渲染代码方面表现卓越。
衍生相关工作
基于BlendNet数据集,研究者们开发了一系列相关的经典工作,包括改进的文本到代码生成模型、增强的3D建模自动化工具以及更高效的渲染算法。这些工作不仅提升了模型的性能,还为3D设计和渲染领域带来了新的技术突破,推动了整个行业的技术进步。
数据集最近研究
最新研究方向
在计算机辅助设计(CAD)与三维建模领域,BlendNet数据集的引入为文本生成与三维渲染任务提供了新的研究视角。该数据集通过结合GPT-4o的自动化标注与人工校验,实现了大规模数据的高效生成与质量控制,为基于语言模型的三维建模技术提供了丰富的训练资源。这一研究方向不仅推动了CAD与自然语言处理的交叉应用,还为未来智能设计工具的开发奠定了基础,具有重要的学术与工业应用价值。
以上内容由遇见数据集搜集并总结生成


