ClusterWise
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/MachaParfait/ClusterWise
下载链接
链接失效反馈官方服务:
资源简介:
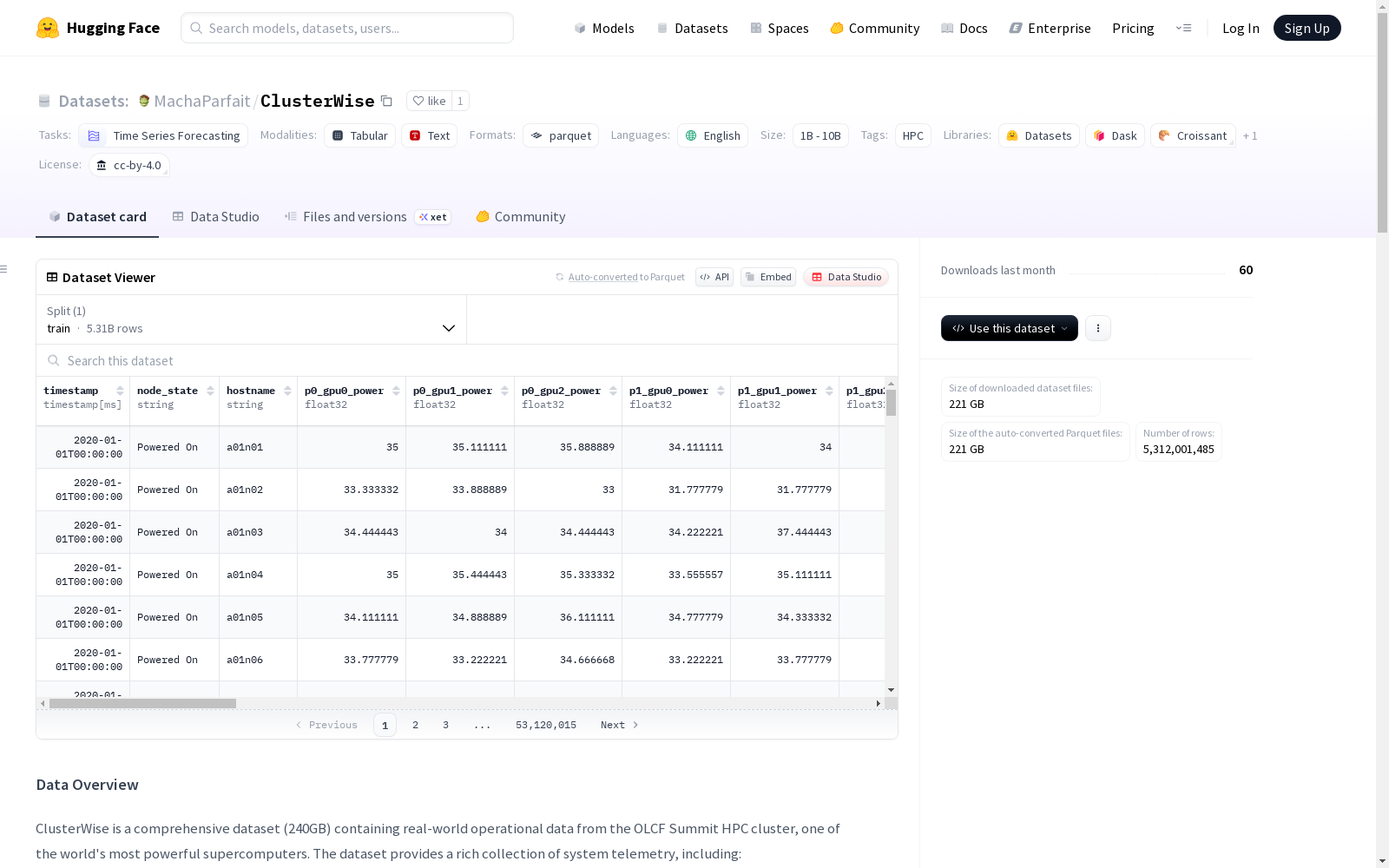
ClusterWise数据集是一个包含来自OLCF Summit HPC集群的实际操作数据的综合数据集,大小为240GB。该数据集提供了丰富的系统遥测信息,包括作业调度日志、GPU故障事件日志、CPU和GPU的高分辨率温度测量、组件之间的详细功耗指标以及节点的物理布局信息。
The ClusterWise Dataset is a comprehensive dataset containing real-world operational data from the OLCF Summit HPC cluster, with a total size of 240 GB. It provides rich system telemetry information, including job scheduling logs, GPU fault event logs, high-resolution temperature measurements for CPUs and GPUs, detailed power consumption metrics between components, and physical layout information of the nodes.
创建时间:
2025-05-16
搜集汇总
数据集介绍
构建方式
在高性能计算系统监控领域,ClusterWise数据集通过采集OLCF Summit超级计算机的实际运行数据构建而成。该数据集整合了作业调度日志、GPU故障事件记录以及高分辨率温度测量等多维度系统遥测数据,形成240GB的完整数据集合。研究人员基于开源的数据处理流程,能够复现生成450GB规模的原始数据集,确保了数据来源的真实性与可追溯性。
特点
作为高性能计算领域的专业数据集,ClusterWise提供了详尽的节点物理布局信息与实时运行状态监控。数据集包含精确到毫秒级的时间戳记录,以及GPU核心与内存温度、CPU功耗与温度极值、电源模块输入功率等关键指标。特别值得注意的是,数据集标注了故障事件标签与NVIDIA错误代码,为系统可靠性研究提供了宝贵的标注信息。
使用方法
针对时间序列预测与分析任务,研究者可通过HuggingFace数据集库直接加载ClusterWise数据集。使用标准代码接口即可获取结构化数据,支持对超级计算机运行状态的深度分析。该数据集遵循CC BY 4.0许可协议,允许商业与非商业用途,但使用者需自行确认数据许可与预期用途的兼容性。
背景与挑战
背景概述
高性能计算集群的可靠性与能效优化是超级计算机运维领域的核心研究议题。ClusterWise数据集由OLCF Summit超级计算机运维团队于2025年创建,汇集了该集群240GB实时运行数据,涵盖任务调度日志、GPU故障事件、温度监测与功耗指标等多维度遥测数据。该数据集通过精确记录节点物理布局与硬件状态,为构建智能运维模型提供了关键数据支撑,显著推进了高性能计算系统故障预测与能效管理的研究进程。
当前挑战
在故障预测领域,该数据集需解决高维时序数据中罕见故障事件的精准检测难题,以及多变量耦合条件下系统状态演变的非线性建模问题。数据构建过程中面临异构传感器采样频率同步、海量数据清洗验证、以及敏感操作日志脱敏等技术挑战,同时需确保数据采集过程不影响超级计算机正常运行的实时性要求。
常用场景
经典使用场景
在超级计算机运维领域,ClusterWise数据集为高性能计算集群的故障预测与健康管理提供了关键支撑。该数据集通过整合作业调度日志、GPU故障事件记录以及高分辨率温度测量等多维度遥测数据,为研究人员构建时间序列预测模型奠定了坚实基础。其经典应用场景聚焦于基于历史运行数据的异常检测算法开发,能够有效识别GPU硬件故障的早期征兆,为大规模计算系统的可靠性保障提供数据驱动的研究范式。
衍生相关工作
该数据集催生了多个具有影响力的衍生研究。基于其多维时间序列特性,研究者开发了融合图神经网络与注意力机制的故障传播模型,深入揭示了计算节点间的故障关联规律。此外,其开放的数据管道设计促进了跨机构合作,衍生出面向异构计算架构的联合学习框架,为超算集群的分布式智能监控开辟了新的技术路径。这些工作共同推动了高性能计算与人工智能技术的深度融合。
数据集最近研究
最新研究方向
在高性能计算系统可靠性研究领域,ClusterWise数据集正推动基于多模态时序数据的故障预测与健康管理前沿探索。该数据集整合了Summit超级计算机的作业调度日志、GPU故障事件与高分辨率温度功耗指标,为构建动态资源失效预警模型提供了关键支撑。当前研究聚焦于融合图神经网络与时空注意力机制,通过节点物理布局与热力分布特征解析硬件退化规律,显著提升了亿级参数规模计算集群的容错调度效率。这类工作直接关联到Exascale计算时代系统稳定性挑战,为超大规模人工智能训练与科学模拟任务提供了可靠性保障范式。
以上内容由遇见数据集搜集并总结生成


