b1_code_top_4_1k_eval_636d
收藏Hugging Face2025-04-25 更新2025-04-26 收录
下载链接:
https://huggingface.co/datasets/mlfoundations-dev/b1_code_top_4_1k_eval_636d
下载链接
链接失效反馈官方服务:
资源简介:
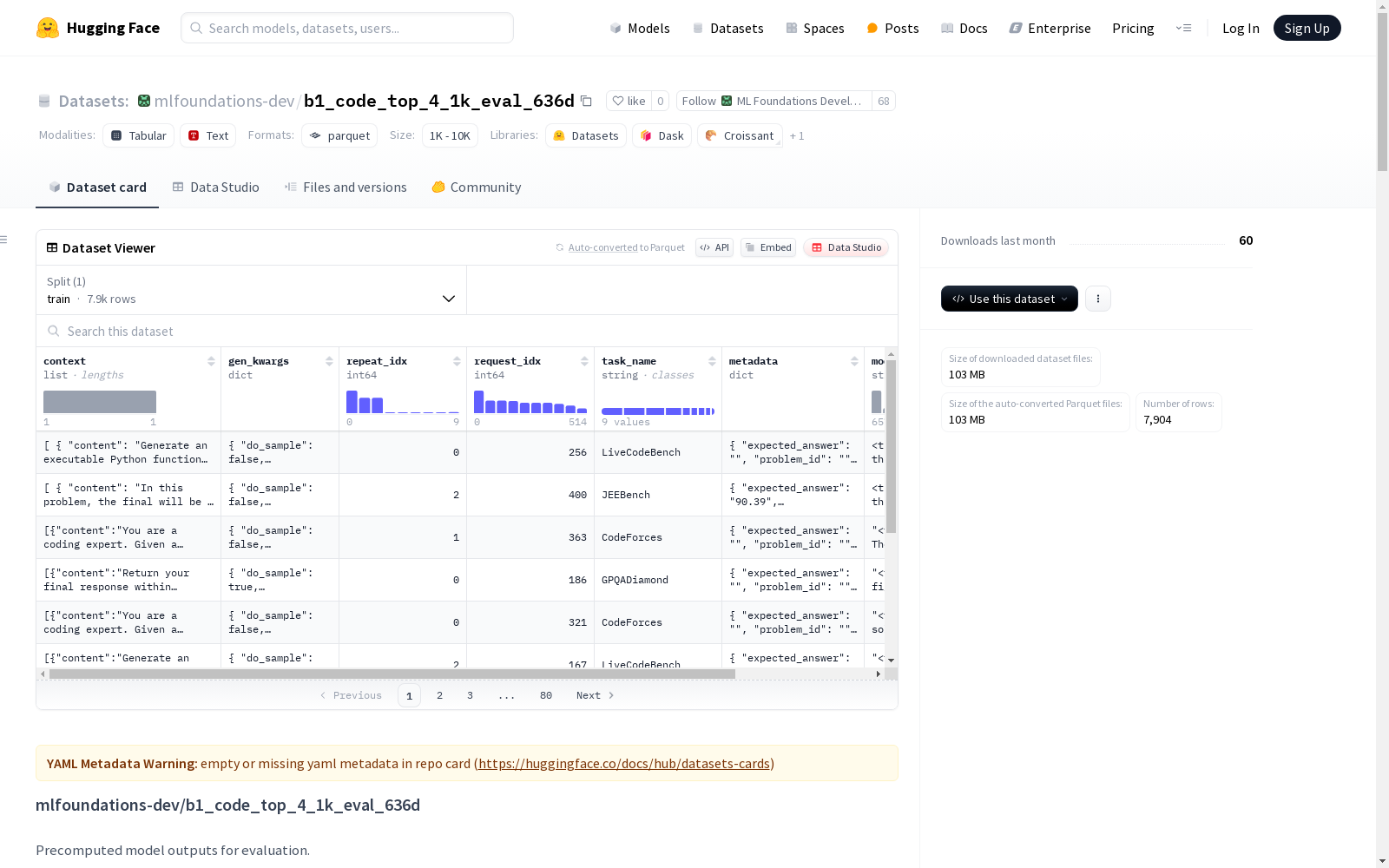
mlfoundations-dev/b1_code_top_4_1k_eval_636d数据集包含了多个编程和数学任务的标准测试结果,用于评估模型在特定领域的表现。这些任务包括AIME24、AMC23、MATH500、MMLUPro、JEEBench、GPQADiamond、LiveCodeBench、CodeElo和CodeForces,每个任务都提供了模型的准确率以及解决的问题数和总问题数。
The mlfoundations-dev/b1_code_top_4_1k_eval_636d dataset contains standard test results for a variety of programming and mathematical tasks, which are utilized to evaluate model performance in specific domains. These tasks include AIME24, AMC23, MATH500, MMLUPro, JEEBench, GPQADiamond, LiveCodeBench, CodeElo, and CodeForces. For each task, the model's accuracy, the number of solved problems, and the total number of problems are provided.
创建时间:
2025-04-25
搜集汇总
数据集介绍
构建方式
在代码生成与评估领域,b1_code_top_4_1k_eval_636d数据集通过预先计算的模型输出构建而成,旨在系统评估模型在多样化编程任务中的表现。该数据集整合了AIME24、AMC23、MATH500等九项权威评测任务,每项任务均采用多轮运行机制确保统计显著性,其中部分任务如MATH500采用全量测试集评估,而其他任务如LiveCodeBench则通过三次独立运行取均值以降低随机误差。数据构建过程严格记录每次运行的准确率、解题数量及总题量,形成结构化评估矩阵。
特点
该数据集最显著的特征在于其多维度的评估体系,覆盖从数学竞赛(AMC23)、编程竞赛(CodeForces)到通用代码生成(LiveCodeBench)等不同难度层级的任务。各子数据集具有鲜明的性能区分度,如MATH500展现68.8%的高准确率,而CodeElo仅5.63%,有效检验模型的泛化能力。所有结果均标注标准差(如AIME24的±1.79%),体现数据测量的科学严谨性。评估指标统一采用准确率与解题数量的双维度量化,便于横向对比模型在不同领域的表现差异。
使用方法
研究者可通过该数据集快速验证代码生成模型在跨领域任务中的综合性能。使用时应关注各子数据集的评估维度差异:对于固定题量的MATH500可直接比较绝对准确率,而存在多轮运行的AMC23需结合标准差分析稳定性。建议优先选择与目标场景匹配的子集(如学术编程评估侧重JEEBench,算法竞赛则参考CodeForces),同时利用CodeElo等低分项定位模型薄弱环节。数据以结构化表格呈现,支持直接导入分析工具进行统计检验或可视化对比。
背景与挑战
背景概述
数据集b1_code_top_4_1k_eval_636d由mlfoundations-dev团队构建,旨在为代码生成与评估领域提供预计算模型输出基准。该数据集聚焦于多维度评估模型的数学推理、编程能力及综合知识掌握程度,覆盖AIME24、AMC23、MATH500等九项权威测评任务。其核心研究问题在于如何通过标准化评估框架,量化模型在复杂逻辑推理和代码生成任务中的表现差异,为人工智能在STEM教育、自动化编程等领域的应用提供可量化的性能指标。
当前挑战
该数据集面临双重挑战:在领域问题层面,不同测评任务间的难度差异导致模型性能波动显著(如AMC23准确率53%而CodeElo仅5.63%),需解决评估体系跨任务一致性问题;在构建过程中,需平衡各测评任务的样本规模(30-515题不等)与代表性,同时处理数学符号、编程语法等特殊文本的标准化问题。此外,多轮次评估结果的标准差控制(如AIME24±1.79%)对数据采集的稳定性提出较高要求。
常用场景
经典使用场景
在人工智能与编程教育交叉领域,b1_code_top_4_1k_eval_636d数据集通过预计算模型输出为算法评估提供了标准化基准。该数据集特别适用于衡量模型在数学竞赛题解(如AMC23、AIME24)、专业编程评估(CodeForces)及综合知识测试(MMLUPro)等复杂认知任务中的表现,其多维度评估框架已成为比较不同AI系统解题能力的黄金标准。
解决学术问题
该数据集有效解决了智能系统在开放域问题求解中的评估难题,通过覆盖数学推理、代码生成、学科知识等九大评估维度,为研究者提供了量化模型认知能力的统一标尺。其细粒度的运行次数统计与准确率波动分析,尤其有助于识别模型在稳定性与泛化性方面的缺陷,推动了自适应学习与鲁棒性算法的理论研究。
衍生相关工作
基于该数据集衍生的研究包括《多模态推理模型的跨任务迁移分析》等突破性论文,其中AMC23评估结果被广泛引用作为数学推理能力的基准指标。后续工作如LiveCodeBench的动态评估框架,进一步扩展了数据集在持续学习场景下的应用价值。
以上内容由遇见数据集搜集并总结生成


