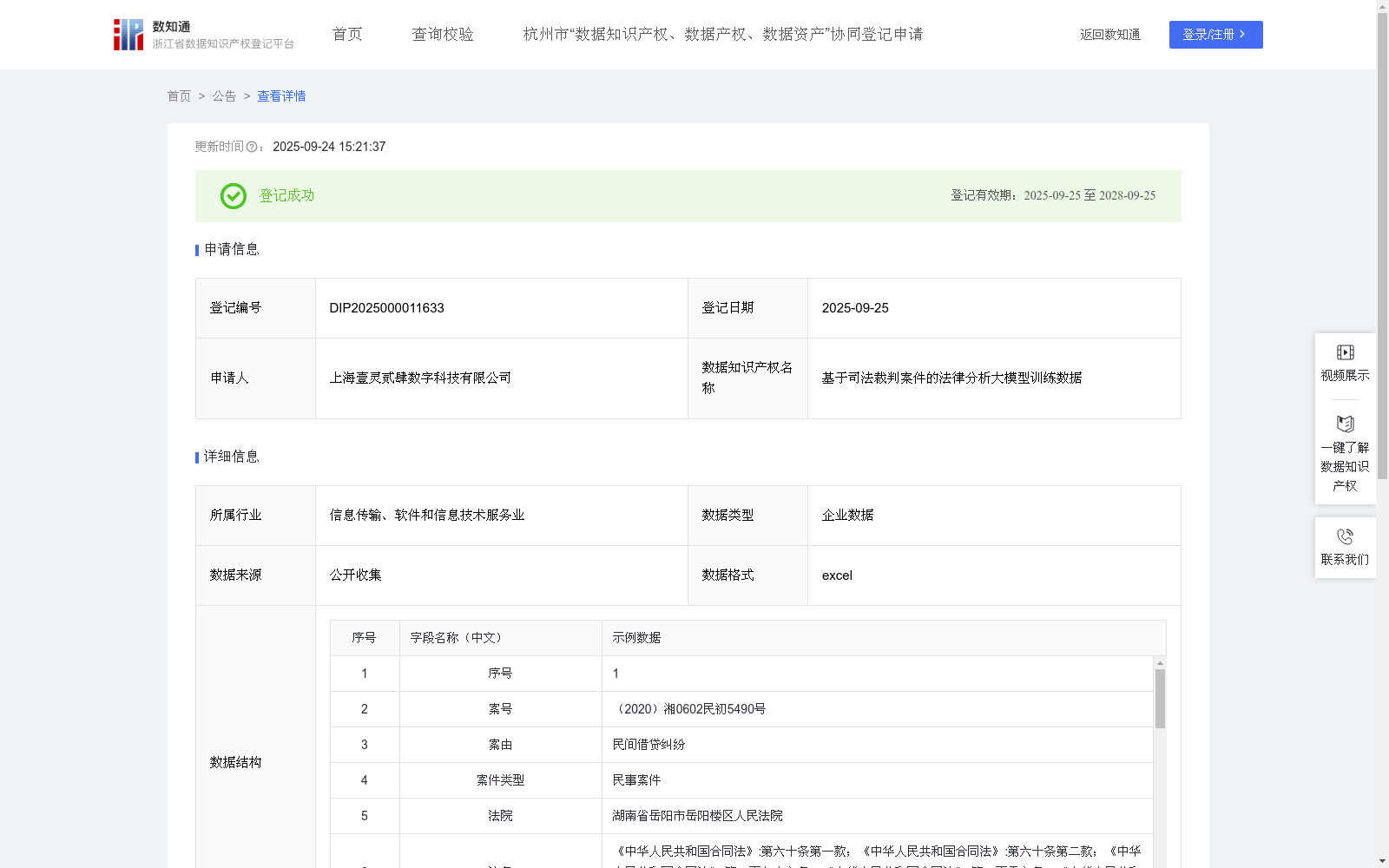
基于司法裁判案件的法律分析大模型训练数据
收藏浙江省数据知识产权登记平台2025-09-24 更新2025-09-25 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/185341
下载链接
链接失效反馈官方服务:
资源简介:
通过整合我公司开发的司法裁判案件的法律分析大模型训练数据即智能法律问答分析模型训练数据,可构建数据语料库,实现自动生成结构化、标准化的法律建议报告,用于分析案件的胜诉率与败诉率,以及案件败诉原因,切实提高法律从业者工作效率。同时,分析司法裁判案件的法律分析大模型训练数据可为生成式法律建议(如案件分析、案例筛选、相关案例推送、诉讼策略与证据清单生成等)提供了基础支撑,从而可推动生成式法律分析的发展。此外,借助分析司法裁判案件的法律分析大模型训练数据可推动法律从业者提升对复杂案件事实与争议焦点,为合同起草、合同审查及模拟法庭等场景的应用提供基础。实现上述应用场景的核心在于,通过海量数据的深度学习,AI模型能够掌握语言规律、理解领域知识,从而显著提升其识别、分类、生成和推理能力。这些数据堪称AI模型的“燃料”,其质量直接决定了模型的性能表现和泛化能力。最终,可输出经过充分训练和优化的AI模型即智能法律问答分析模型产品,推动法律服务的优化升级,并为司法裁判的精准裁判提供关键助力。1、数据来源:通过已公开的裁判文书,收集司法裁判相关判决书中的案号、案由、裁判时间、案件类型、诉讼程序等信息;
2、数据处理:对收集到的数据进行去重、合并、累加,便于分析使用;
3、算法规则:采用NLP模型并基于DeepSeek向量模型进行法律领域专门优化,将法律问题、案件文本转化为1024维的高维向量,利用余弦相似度和欧氏距离混合度量进行相似度计算,通过分词、向量检索和倒排索引实现关键词精确匹配。同时,基于Neo4j的路径查询和图神经网络(GNN)预测案例相似度构建知识图谱推理层,分析并结构化存储历史案件向量及关键标签,如裁判要旨、原告是否胜诉、胜诉/败诉的主要证据因素、胜诉/败诉的主要程序因素。
By integrating the training data of the legal analysis large language model for judicial adjudication cases developed by our company, namely the training data of the intelligent legal question answering and analysis model, a data corpus can be constructed to automatically generate structured and standardized legal advisory reports, which are used to analyze the winning rate, losing rate and the reasons for case losses, effectively improving the work efficiency of legal practitioners. Meanwhile, the training data of the legal analysis large language model for judicial adjudication cases can provide foundational support for generative legal advisory services, such as case analysis, case screening, relevant case recommendation, litigation strategy and evidence list generation, thereby promoting the development of generative legal analysis. In addition, leveraging such training data can further enable legal practitioners to better grasp complex case facts and controversial issues, and provide foundational support for applications in scenarios such as contract drafting, contract review and mock trials. The core of realizing the above application scenarios lies in that through deep learning on massive data, AI models can master linguistic laws and understand domain-specific knowledge, thereby significantly improving their capabilities in recognition, classification, generation and reasoning. These data can be regarded as the "fuel" of AI models, and their quality directly determines the model's performance and generalization ability. Ultimately, fully trained and optimized AI models, namely the intelligent legal question answering and analysis model products, can be output to promote the optimization and upgrading of legal services, and provide critical support for accurate judicial adjudication. 1. Data Source: Collect information such as case number, cause of action, adjudication time, case type and litigation procedure from publicly available judicial judgments. 2. Data Processing: Deduplicate, merge and aggregate the collected data to facilitate analysis and usage. 3. Algorithm Rules: Adopt NLP models and conduct domain-specific optimization for the legal field based on the DeepSeek vector model. Convert legal questions and case texts into 1024-dimensional high-dimensional vectors, use a hybrid metric of cosine similarity and Euclidean distance for similarity calculation, and achieve precise keyword matching through word segmentation, vector retrieval and inverted index. Meanwhile, build a knowledge graph inference layer based on Neo4j's path query and Graph Neural Network (GNN) for predicting case similarity, analyze and structurally store historical case vectors and key tags, such as adjudication gist, whether the plaintiff prevails in the case, main evidence factors for winning or losing, and main procedural factors for winning or losing.
提供机构:
上海壹灵贰肆数字科技有限公司
创建时间:
2025-07-20
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


