ViDia2Std
收藏Hugging Face2025-11-29 更新2025-11-30 收录
下载链接:
https://huggingface.co/datasets/Biu3010/ViDia2Std
下载链接
链接失效反馈官方服务:
资源简介:
ViDia2Std是一个高质量的手工注释平行语料库,用于将越南语方言(北方、中部、南方)翻译成标准越南语。该语料库来源于越南全国63个省份的社交媒体评论,适用于方言标准化和适应任务的基准测试。
ViDia2Std is a high-quality manually annotated parallel corpus dedicated to translating Vietnamese dialects (Northern, Central, Southern) into Standard Vietnamese. This corpus is sourced from social media comments across all 63 provinces of Vietnam, and serves as a benchmark dataset for dialect standardization and adaptation tasks.
创建时间:
2025-11-17
原始信息汇总
ViDia2Std 数据集概述
基本信息
- 数据集名称: ViDia2Std
- 许可证: CC-BY-NC-4.0
- 任务类别: 翻译
- 语言: 越南语
- 数据规模: 10K-100K
- 标签: 方言规范化、越南语方言、社交媒体、低资源
数据集描述
ViDia2Std是一个高质量、手动标注的平行语料库,用于将越南语方言(北部、中部、南部)翻译为标准越南语。数据来源于越南全部63个省份的真实社交媒体评论,可作为方言规范化和适应任务的基准数据集。
数据集结构
文件组成
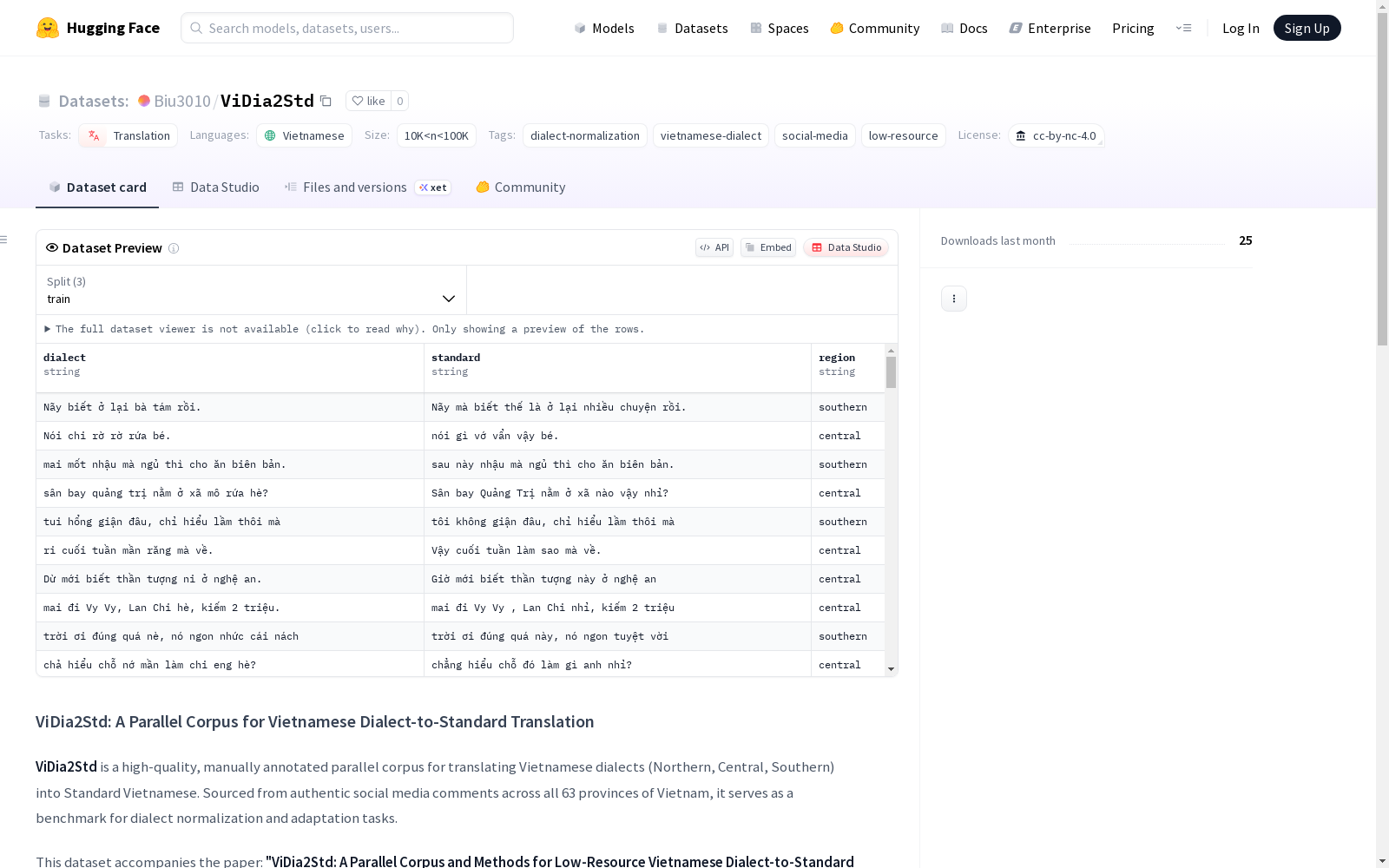
- 训练集: train.csv (10,870对)
- 验证集: dev.csv (1,184对)
- 测试集: test.csv (1,603对)
数据字段
| 字段 | 描述 |
|---|---|
| dialect | 原始方言输入句子(源),包含地区词汇和非标准语法 |
| standard | 手动规范化的标准越南语句子(目标),与源句意义和意图相同 |
| region | 源句的方言区域:northern、central或southern |
| sentiment | 句子情感标签(仅测试集包含):positive、negative、neutral |
数据统计
| 分割 | 样本数量 |
|---|---|
| 训练集 | 10,870 |
| 验证集 | 1,184 |
| 测试集 | 1,603 |
| 总计 | 13,657 |
相关论文
本数据集配套论文:"ViDia2Std: A Parallel Corpus and Methods for Low-Resource Vietnamese Dialect-to-Standard Translation"(已获AAAI-26接收)
搜集汇总
数据集介绍
构建方式
在越南语方言翻译研究领域,ViDia2Std数据集的构建采用了系统化的采集与标注流程。研究团队从越南63个省份的真实社交媒体评论中收集原始语料,覆盖北部、中部和南部三大方言区。通过专业语言学工作者的手工标注,将非标准化的方言表达转化为规范的越南标准语,确保语义对等性和语言规范性,最终形成包含13,657对平行句对的高质量语料库。
使用方法
研究者可通过标准数据分割方案使用该数据集,其中训练集包含10,870个样本,验证集1,184个,测试集1,603个。使用Pandas库可直接加载CSV格式文件,通过'dialect'和'standard'列分别获取源语言和目标语言文本。该数据集适用于方言标准化、机器翻译模型训练等任务,测试集的情感标签还可支持跨领域评估研究。
背景与挑战
背景概述
随着社交媒体在越南的普及,方言文本的自动处理成为自然语言处理领域的重要课题。ViDia2Std数据集由研究团队于2026年创建,专门针对越南三大方言区(北部、中部、南部)与标准越南语之间的转换任务。该数据集覆盖越南全部63个省份的真实社交评论,通过人工标注构建平行语料,为低资源方言翻译研究提供了关键基础设施,显著推动了东南亚语言技术的发展和跨方言交流的智能化进程。
当前挑战
方言标准化任务面临多重挑战:方言词汇与标准语间的语义鸿沟、区域性语法结构的差异性转换、以及社交媒体文本中特有的非正式表达处理。在数据构建过程中,标注团队需克服方言标注规范缺失的困难,确保不同方言变体与标准语间的语义等价性,同时还要应对低资源环境下数据稀疏性问题,这些因素共同构成了该领域研究的核心难点。
常用场景
经典使用场景
在越南语自然语言处理领域,ViDia2Std数据集为方言标准化任务提供了关键支撑。该数据集通过构建北部、中部与南部三大方言区与标准越南语的平行语料,成为训练神经机器翻译模型的基准资源。研究者可基于其标注的方言区域标签,系统分析不同方言变体对标准化的影响,为低资源语言处理开辟了新路径。
解决学术问题
该数据集有效解决了越南语方言与标准语间的语义鸿沟问题。通过提供人工标注的标准化对照文本,为方言语法规范化、词汇映射等研究提供量化依据。其覆盖全境63省份的社交媒体语料,显著提升了方言翻译模型在真实场景下的泛化能力,对低资源语言技术发展具有里程碑意义。
实际应用
在现实应用中,该数据集支撑着越南社交媒体的内容治理与信息标准化。基于其训练的翻译模型可自动转换用户生成的方言内容为规范文本,助力政府机构实现跨地域信息同步。同时为商业平台提供方言区用户意图理解能力,在电商客服、舆情监测等领域产生实际价值。
数据集最近研究
最新研究方向
在低资源方言处理领域,ViDia2Std数据集推动了方言标准化翻译的前沿探索。该数据集聚焦越南三大方言区与标准越南语的转换,其独特价值在于覆盖全境63个省份的真实社交媒体语料。当前研究热点集中于跨方言迁移学习与多任务框架构建,通过联合学习方言归一化与情感分析任务,显著提升模型在非标准文本场景下的鲁棒性。该资源为东南亚语言技术发展提供了重要基准,尤其在社交媒体内容理解与数字鸿沟消解方面具有深远影响。
以上内容由遇见数据集搜集并总结生成


