agarwalayushi/hinglish
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/agarwalayushi/hinglish
下载链接
链接失效反馈官方服务:
资源简介:
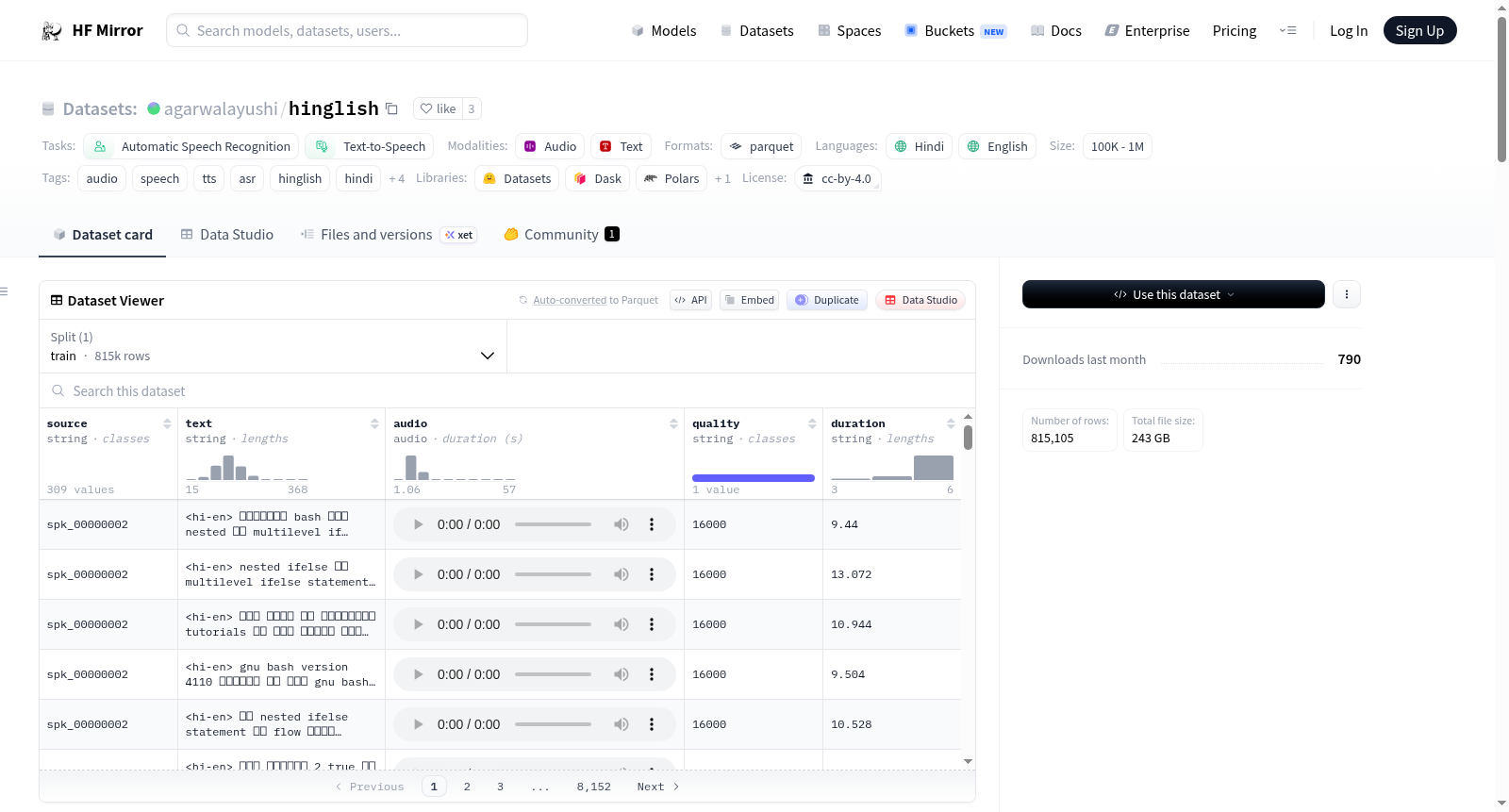
Hinglish Concatenated Audio Dataset是一个大规模、经过清理和注释的语音数据集,涵盖印地语、Hinglish(印地语-英语代码转换)和印度英语。该数据集由14个公共语料库和原始自定义录音编译而成,统一为一个具有一致模式的Parquet数据集。数据集包含815,171个音频片段,总计超过2,264小时的录音,来自6,304个独特的说话者。音频格式为嵌入Parquet的WAV文件,支持ASR、TTS微调、语音克隆和语音研究等任务。数据集经过重新分段以去除静音和交叉对话,转录文本已标准化为Unicode NFC,并添加了语言标签(如`<hi-en>`表示代码转换的语句)。
A large-scale, cleaned and annotated speech dataset covering Hindi, Hinglish (Hindi–English code-switching), and Indian English — compiled from 14 public corpora and original custom recordings, unified into a single Parquet dataset with consistent schema. The dataset contains 815,171 audio clips totaling over 2,264 hours of recordings from 6,304 unique speakers. Audio is stored as WAV embedded in Parquet, supporting tasks like ASR, TTS fine-tuning, voice cloning, and speech research. The dataset has been re-segmented to remove silence and cross-talk, with transcripts normalized to Unicode NFC and language tags added (e.g., `<hi-en>` for code-switched utterances).
提供机构:
agarwalayushi
搜集汇总
数据集介绍
构建方式
Hinglish数据集是一个大规模、经过清洗和标注的语音语料库,涵盖了印地语、印地语-英语混合语及印度英语三种语言变体。该数据集通过整合14个公开语料库与原创定制录音构建而成,所有数据均统一为Parquet格式并采用一致的Schema。在构建过程中,研究团队对所有音频片段进行了静音和串扰去除的重新分割,对转录文本进行了Unicode NFC标准化处理,并为代码切换语句添加了<hi-en>语言标签。同时,重复及近似重复的片段被剔除,最终形成包含815,171个音频片段、总时长超过2,264小时、涵盖6,304位独特说话人的高质量语音集合。
特点
该数据集最显著的特点在于其多语言混合性与大规模覆盖能力,不仅包含了纯印地语和印度英语,更关键的是大量印地语-英语代码切换的语音内容,真实反映了南亚地区日常交流中的语言混合现象。数据来源多样化,既包括AI4Bharat、Mozilla Common Voice等知名学术开源项目,也包含专业录音棚品质的TTS语料和社区贡献的语音数据,保证了语音风格、口音和录音环境的丰富性。所有音频以Wave格式嵌入Parquet文件中,原始采样率得以保留,并附带说话人来源、清洗后转录文本、质量评分及时长等元数据,便于下游任务调用。
使用方法
该数据集可直接用于自动语音识别(ASR)和文本转语音(TTS)任务的微调与评估,亦适用于语音克隆及多语言语音研究。用户可通过Hugging Face Datasets库加载Parquet格式数据,利用内置的audio字段访问Wave音频,并依据source、text、quality等元数据进行子集筛选或按说话人划分训练/测试集。对于需要进行语言标识的任务,代码切换语句中的<hi-en>标签可辅助模型学习语言边界。研究人员应遵守CC BY 4.0许可协议,在使用时注明数据集及上游源头,并避免将数据用于生成未经同意的合成语音或欺诈、骚扰等不当用途。
背景与挑战
背景概述
在自动语音识别与文本转语音研究领域,多语言和代码混合语音数据的匮乏长期制约着模型对南亚语言变体的泛化能力。Hinglish Concatenated Audio Dataset由Ayushi Agarwal于2026年创建,旨在构建一个覆盖印地语、印地-英语代码混合语及印度英语的大规模语音数据集。该数据集整合了来自AI4Bharat、Mozilla Common Voice等14个公共语料库及原始定制录音,总计超过81.5万条语音片段、2264小时音频和6304位独立说话人,并以统一的Parquet格式存储。其发布对低资源语音技术发展具有重要意义,为研究语码转换、多说话人声学建模及TTS/ASR跨语言迁移学习提供了标准化的基准数据集。
当前挑战
该数据集所解决的领域问题核心在于语码转换语音识别的挑战:印地语与英语在高频交互中产生的混合语言结构缺乏足量标注数据,导致现有模型难以捕捉语种边界动态切换的声学与语言特征。在构建过程中,面临多源数据异构性难题——不同语料库的采样率、标注规范、噪声水平及说话人身份编码存在显著差异,需经过统一的静音裁剪、文本归一化(Unicode NFC)、重复片段去重及语言标签注入等预处理流程。此外,部分上游数据集的许可证不统一,且自建录音需控制录音环境以保证声学一致性,均对数据质量与合规性管理构成严峻挑战。
常用场景
经典使用场景
在语音技术与计算语言学交叉领域中,Hinglish数据集凭借其涵盖印地语、印地英语混合语码及印度英语的多语言音频语料,成为自动语音识别与文本转语音系统微调的核心资源。研究者常利用其超过81.5万条经过去噪、去重及文本归一化处理的音频片段,构建跨语言语音识别模型,尤其在处理语码切换这一挑战性任务时,该数据集提供了高质量的标注样本,使得模型能够精准捕捉两种语言在音素、韵律及语法层面的交互特征,从而显著提升在真实对话场景中的鲁棒性。
解决学术问题
该数据集有效回应了低资源语言语音处理中的两大瓶颈:一是缺乏大规模、多说话人的高质量语料,二是语码切换现象的标注数据稀缺。通过聚合14个公开语料库并补充定制录音,Hinglish填补了印地语与英语混合语音在学术研究中的空白,使得研究者能够探索说话人无关的语音识别方法、多语言语音克隆技术以及跨语种迁移学习范式。其意义在于推动了南亚语言语音技术的民主化,为后续构建包容性更强的多语言语音接口奠定了数据基础。
衍生相关工作
围绕Hinglish数据集已衍生出多项经典学术工作,包括基于其基线构建的语码切换语音识别基准模型,以及利用其多说话人属性开展的表征学习研究。其中,研究者通过在该数据集上微调Wav2Vec 2.0和Whisper等预训练模型,验证了数据增强策略对语码切换识别精度的提升效果。此外,该数据集还催生了针对印度英语口音可控的TTS合成方法,以及将语音与文本模态对齐的跨语言表示学习框架,进一步拓展了多语言语音处理的边界。
以上内容由遇见数据集搜集并总结生成


