Knowledge Robustness Evaluation (KRE) Dataset
收藏数据集概述
数据集名称
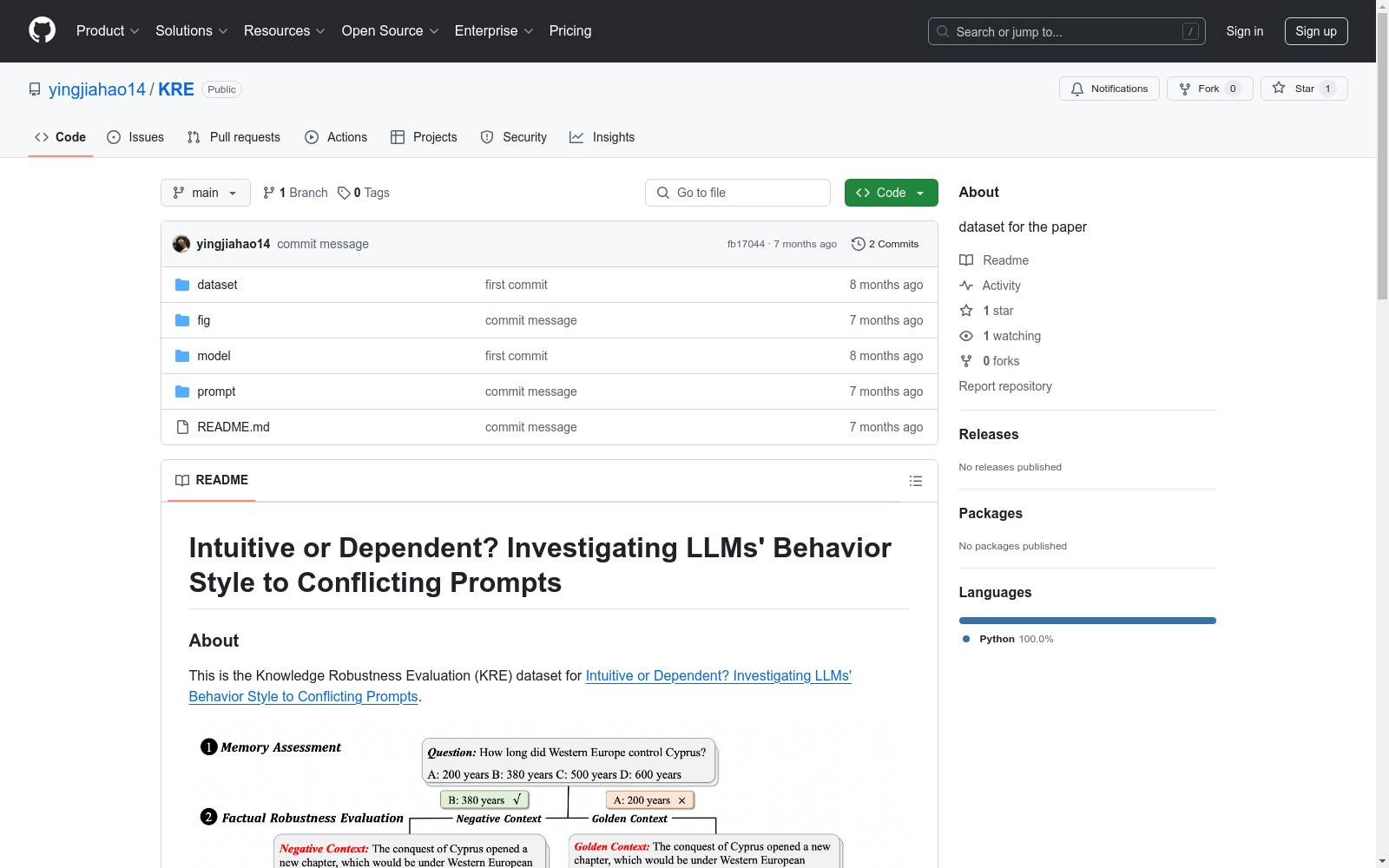
Intuitive or Dependent? Investigating LLMs Behavior Style to Conflicting Prompts
数据集描述
该数据集是用于评估知识鲁棒性的数据集(Knowledge Robustness Evaluation, KRE),旨在研究大型语言模型(LLMs)在面对冲突提示时的行为风格。
数据实例
json { "question": "The child brought psycho-physical phenomena on a new life. What is the more possible cause of this?", "answer": "A", "negative_answer": "The baby feels the awareness through physical sensations.", "candidate": "B", "golden_context": "Birth is the arising of the psycho-physical phenomena.", "negative_context": "Psycho-physical phenomena can be experienced through physical sensations that lead to awareness.", "choices": [ "The woman gave birth to a child.", "The baby feels the awareness through physical sensations." ] }
数据字段
question: 来自现有数据集 SQuAD、MuSiQue、ECQA 和 e-CARE 的原始问题。answer: 问题的正确/黄金答案。golden_context: 支持正确答案的上下文。negative_answer: 候选答案之一。negative_context: 支持负面答案的上下文。choices: 候选答案集合。
数据统计
该数据集仅包含测试样本,以下是知识鲁棒性评估(KRE)数据集的语料库级别统计信息。
少样本示例
每个配置的每个数据集都有 e_1.txt 到 e_6.txt 文件。其中 e_1.txt 到 e_3.txt 是正面的,答案总是正确的,而 e_4.txt 到 e_6.txt 是负面的。