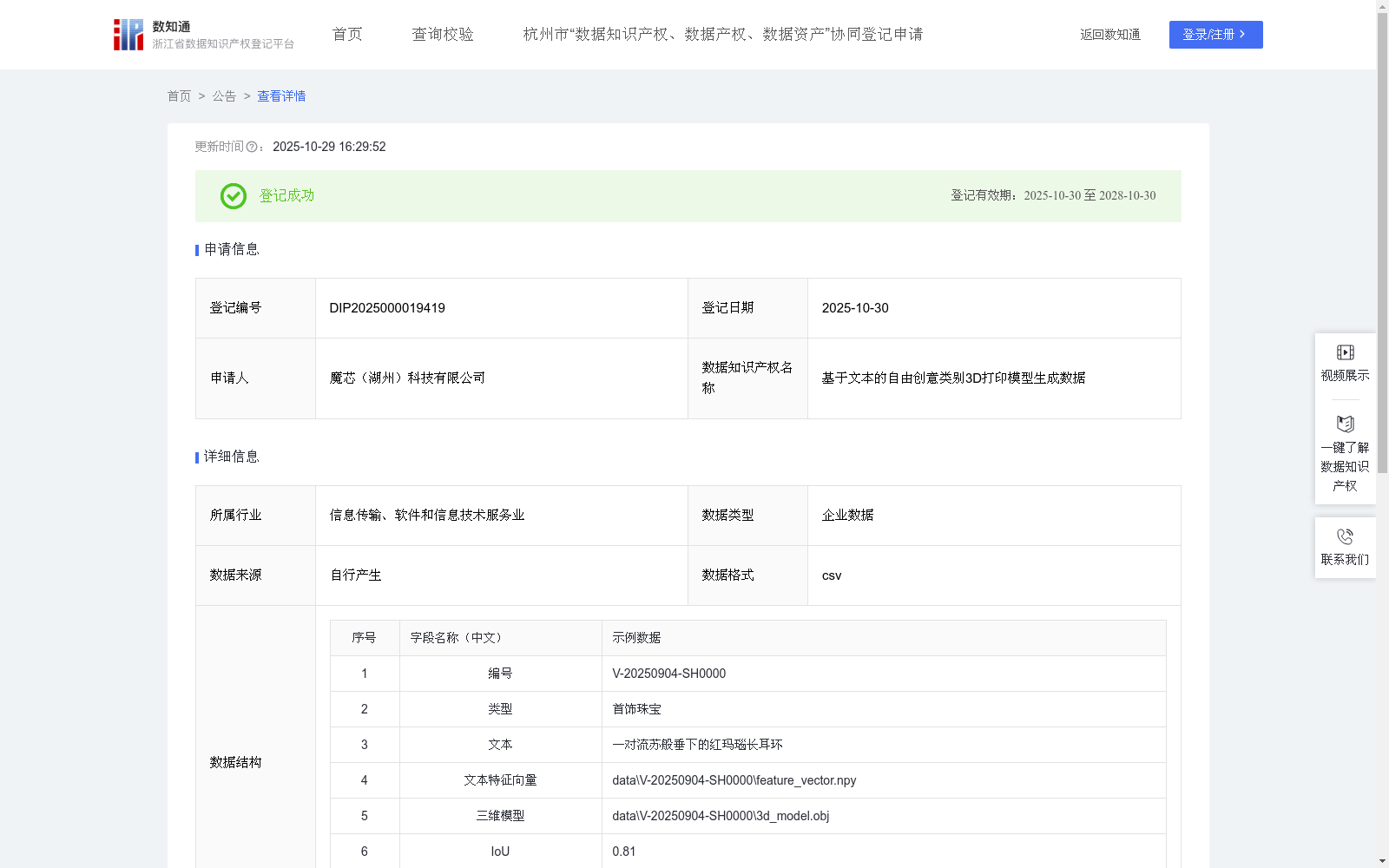
基于文本的自由创意类别3D打印模型生成数据
收藏浙江省数据知识产权登记平台2025-10-29 更新2025-10-30 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/6644245
下载链接
链接失效反馈官方服务:
资源简介:
通过构建一个包含大量不同类别自由创意、且均为水密性的3D打印模型及其对应文本标签的大规模配对数据集,可以为深度学习模型提供训练基础,使其学习从类别文本生成特定领域的三维几何模型。这一数据集主要适用于教育领域、个性化玩具定制、博物馆展览以及桌面游戏模型制作。利用该数据训练出的模型,能够让教师、学生和爱好者通过输入自由创意名称或简单描述来直接生成可供3D打印的模型,解决了在网络上寻找特定物种且质量可靠的打印模型耗时耗力,以及从零开始创作技术门槛高的问题。基于文本生成特定类别(如自由创意)的可3D打印模型,旨在简化专业内容的创作流程。具体过程包括:(1)数据收集:用户输入描述目标自由创意类别和姿态的文本提示(T_prompt)(2)数据处理:将输入的文本提示送入一个预训练的文本编码器,将其转换为一个能捕捉自由创意类别和形态关键语义的特征向量。特征向量通过公式 F_text = Encoder_text(T_prompt) 提取,其中 F_text 为文本特征向量,Encoder_text 为文本编码器。(3)模型构建:使用提取的文本特征向量作为条件输入,设计并搭建一个在该自由创意数据集上经过优化的深度几何生成模型。该模型专门学习生成自由创意形态的隐式三维表示。根据公式 SDF = Decoder_3D(F_text) 从文本特征中解码出三维模型的SDF表示,其中 SDF 为三维模型的表面符号距离场,Decoder_3D 为三维形状解码器。生成模型的几何准确度通常通过与该类别下的真实模型对比来评估,关键的评估指标包括交并比(Intersection over Union, IoU)和倒角距离(Chamfer Distance, CD)。此方法适用于按需生成特定领域的3D打印内容,特别是为教育和娱乐行业提供快速、便捷的自由创意模型生成方案。
Building a large-scale paired dataset containing numerous watertight 3D-printable models across various free creative categories along with their corresponding text labels can provide a training foundation for deep learning models, enabling them to learn to generate 3D geometric models in specific domains from category text. This dataset is primarily applicable to education, personalized toy customization, museum exhibitions, and tabletop game model production. Models trained using this data allow teachers, students, and enthusiasts to directly generate 3D-printable models by inputting free creative names or simple descriptions, addressing the issues of time-consuming and laborious searches for high-quality printable models of specific categories online, as well as the high technical threshold of creating models from scratch. Generating 3D-printable models of specific categories (e.g., free creative ideas) based on text aims to simplify the creation process of professional content. The specific process includes: (1) Data Collection: Users input text prompts ($T_{ ext{prompt}}$) that describe the target free creative category and posture; (2) Data Processing: The input text prompt is fed into a pre-trained text encoder, which converts it into a feature vector that captures the key semantics of the free creative category and its morphology. The feature vector is extracted via the formula $F_{ ext{text}} = ext{Encoder}_{ ext{text}}(T_{ ext{prompt}})$, where $F_{ ext{text}}$ is the text feature vector and $ ext{Encoder}_{ ext{text}}$ is the text encoder; (3) Model Construction: Using the extracted text feature vector as conditional input, a deep geometric generative model optimized on this free creative dataset is designed and built. This model specializes in learning implicit 3D representations of free creative shapes. The signed distance field (SDF) representation of the 3D model is decoded from the text features via the formula $ ext{SDF} = ext{Decoder}_{ ext{3D}}(F_{ ext{text}})$, where $ ext{SDF}$ is the surface signed distance field of the 3D model and $ ext{Decoder}_{ ext{3D}}$ is the 3D shape decoder. The geometric accuracy of the generative model is typically evaluated by comparing with real models of the same category, with key evaluation metrics including Intersection over Union (IoU) and Chamfer Distance (CD). This method is suitable for on-demand generation of 3D printing content in specific fields, particularly providing fast and convenient solutions for generating free creative models for the education and entertainment industries.
提供机构:
魔芯(湖州)科技有限公司
创建时间:
2025-09-04
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含4555条CSV格式数据,每条记录包括文本描述、特征向量和3D模型文件,用于训练深度学习模型从文本生成自由创意类别的3D打印模型。它支持教育、玩具定制等应用场景,通过预训练算法简化模型生成流程,并采用IoU和CD指标评估几何准确性。
以上内容由遇见数据集搜集并总结生成


