Nemotron-RLHF-GenRM-v1-prompt-only
收藏Hugging Face2026-06-30 更新2026-07-01 收录
下载链接:
https://huggingface.co/datasets/jamesdborin/Nemotron-RLHF-GenRM-v1-prompt-only
下载链接
链接失效反馈官方服务:
资源简介:
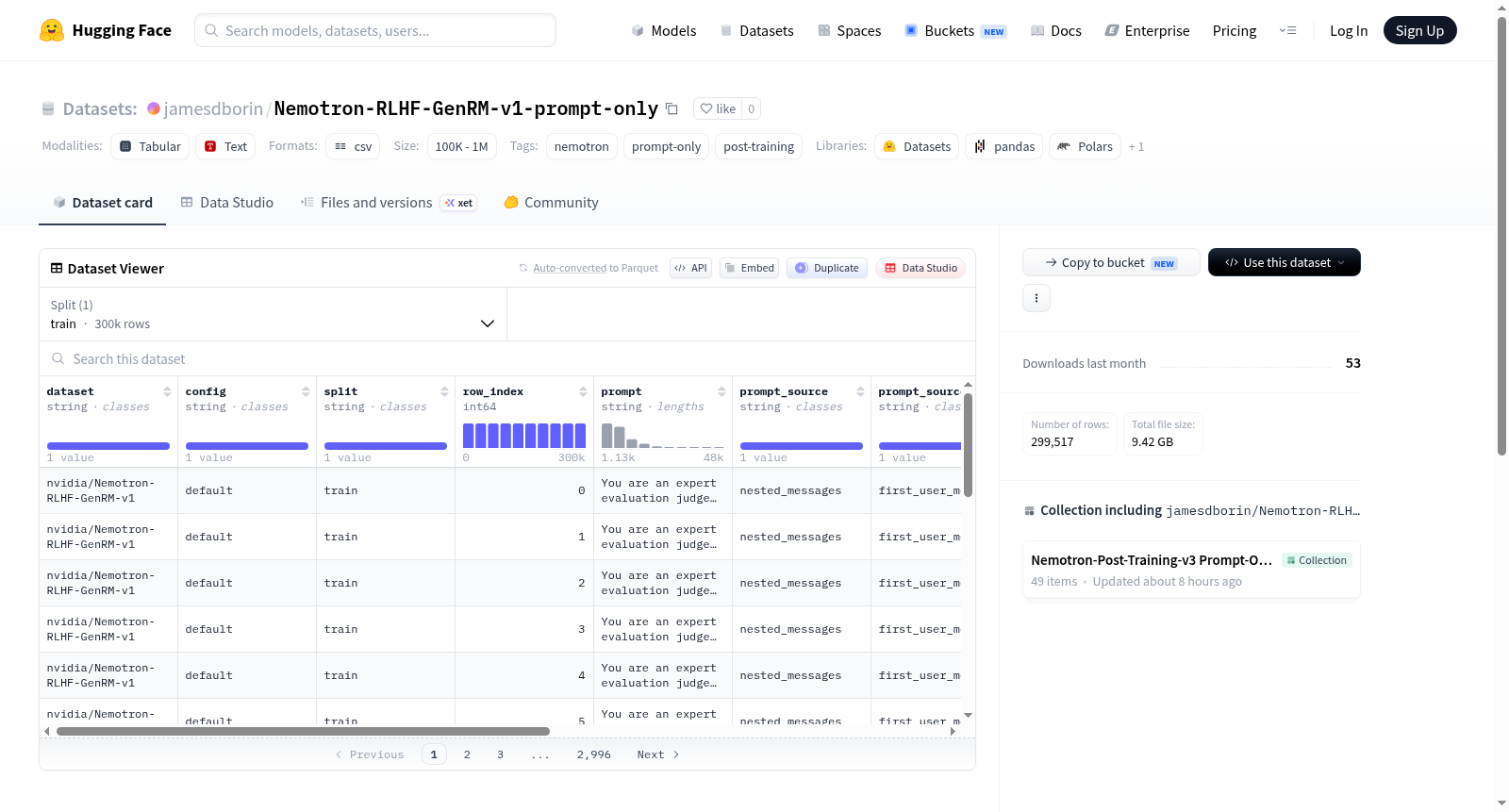
Nemotron-RLHF-GenRM-v1-prompt-only是一个从源数据集nvidia/Nemotron-RLHF-GenRM-v1中提取的仅包含提示部分的数据集,属于Nemotron后训练工作流的一部分,专门用于生成式奖励模型(GenRM)的强化学习人类反馈(RLHF)场景。核心文件prompts.csv包含299,517条提示记录,每条记录包括提示(prompt)、系统提示(system_prompt)以及当源行定义可用工具时的结构化工具(tools)字段,其中嵌套值以JSON格式编码存储于CSV单元格中。辅助文件包括summary.md(记录源行计数、提取行计数、计数差值和失败提示计数)和null_or_empty_rows.md(记录提示提取结果为null或空值的行索引)。数据提取过程零失败,行数无差异。该数据集适用于需要纯提示文本进行模型训练、评估或分析的任务,特别是在工具增强对话或指令遵循场景下。
Nemotron-RLHF-GenRM-v1-prompt-only is a dataset extracted from the source dataset nvidia/Nemotron-RLHF-GenRM-v1, containing only the prompt portion. It is part of the Nemotron post-training workflow, specifically designed for reinforcement learning human feedback (RLHF) scenarios with generative reward models (GenRM). The core file is prompts.csv, which includes 299,517 extracted prompt records, each containing prompt, system_prompt, and structured tools fields (when available tools are defined in the source row), with nested values encoded in JSON format stored in CSV cells. Additionally, the dataset includes two auxiliary files: summary.md (recording source row count, extracted row count, count difference, and failed prompt count) and null_or_empty_rows.md (recording row indices where prompt extraction resulted in null or empty values). The data extraction process had zero failures (no failed prompt rows) and no row count discrepancies. This dataset is suitable for tasks requiring pure prompt text for model training, evaluation, or analysis, particularly in tool-augmented dialogue or instruction-following scenarios.
创建时间:
2026-06-26
原始信息汇总
数据集名称
Nemotron-RLHF-GenRM-v1-prompt-only
数据集描述
该数据集是从 nvidia/Nemotron-RLHF-GenRM-v1 中提取的仅包含提示(prompt)部分的数据子集,源自 Nemotron Post-Training v3 提示提取器工作流。
数据集内容
数据集包含以下文件:
- prompts.csv:每条源记录对应一个提示提取记录。记录包含
prompt、分离的system_prompt,以及当源记录定义了可用工具时的结构化tools。嵌套值以 JSON 格式编码在 CSV 单元格内。 - summary.md:源记录行数、提取行数、行数变化量以及失败提示数量。
- null_or_empty_rows.md:提示提取产生空值或空字符串提示的行索引。
数据统计
- 提取行数:299,517
- 失败提示行数:0
- 行数变化量:0
标签与来源
- 标签:nemotron、prompt-only、post-training
- 源数据集:nvidia/Nemotron-RLHF-GenRM-v1(https://huggingface.co/datasets/nvidia/Nemotron-RLHF-GenRM-v1)
搜集汇总
数据集介绍
构建方式
在强化学习后训练的数据处理流程中,从原始数据集'nvidia/Nemotron-RLHF-GenRM-v1'中提取仅含提示(prompt)的字段,构建了Nemotron-RLHF-GenRM-v1-prompt-only数据集。具体而言,每条源记录被解析为一个独立的提示行,并保留系统提示词(system_prompt)以及当源行定义了可用工具时结构化的工具描述(tools)。嵌套的值以JSON编码形式嵌入CSV单元格中,以确保复杂结构的完整性与可解析性。最终生成了包含299517条提取行的prompts.csv文件,提取失败行数为0,行数差为零,验证了数据提取的可靠性。
特点
该数据集专注于提供纯净的提示文本,剥离了配对响应或其他训练标签,使其成为评估生成式奖励模型(GenRM)时独立输入的理想基准。其三大核心特征包括:一是保留结构化系统提示和工具定义,支持对复杂多轮对话或工具调用场景的模拟;二是格式统一为CSV,便于直接用作下游脚本或框架的数据加载源;三是提供了详细的摘要统计(summary.md)及空值记录索引(null_or_empty_rows.md),确保了数据质量的透明可追踪。
使用方法
使用该数据集时,可直接加载prompts.csv文件,并通过标准CSV解析库读取每一行。每行包含三个字段:'prompt'(核心提示文本)、'system_prompt'(系统级指令)及'tools'(工具定义,可以为空)。对于需要结构化输入的生成式奖励模型或提示评估管线,可逐行提取这些字段,并将'tools'字段中的JSON字符串解析为Python对象,以构造完整的模型输入。此外,summary.md和null_or_empty_rows.md可作为过滤或验证辅助文件,帮助快速识别并排除有问题的记录。
背景与挑战
背景概述
Nemotron-RLHF-GenRM-v1-prompt-only数据集由NVIDIA研究团队于近期创建,专注于后训练阶段的大语言模型强化学习,尤其是基于生成式奖励模型(GenRM)的优化。该数据集从NVIDIA/Nemotron-RLHF-GenRM-v1中提取了约30万个提示样本,旨在为研究者提供高质量的指令-系统提示对,以减少奖励模型训练中的噪声。作为Nemotron系列的一部分,该数据集填补了后训练阶段中奖励信号获取成本高昂的空白,通过结构化的提示设计,显著提升了模型在复杂任务上的对齐效果,对强化学习与模型微调领域具有重要推动意义。
当前挑战
该数据集面临的挑战集中在两个层面。在领域问题层面,它旨在解决大语言模型在后训练阶段奖励信号稀疏且不可靠的难题,现有的奖励模型常因提示设计与系统指令不匹配而产生偏差,导致模型对齐效果欠佳。在构建过程层面,数据提取需从原始多源记录中精确分离提示、系统提示和工具信息,嵌套值的JSON编码在CSV中易引入格式错误,且需确保近30万条记录的完整性,避免空或无效提示的干扰,这对数据清洗与异构结构对齐提出了较高要求。
常用场景
经典使用场景
Nemotron-RLHF-GenRM-v1-prompt-only数据集,作为从nvidia/Nemotron-RLHF-GenRM-v1中精心提取的纯提示子集,在强化学习与人类反馈(RLHF)领域扮演着关键角色。其最经典的应用场景在于为大语言模型的后训练阶段提供高质量的提示样本,用以训练生成式奖励模型。通过保留原始数据中的提示、系统提示及结构化工具信息,该数据集使研究者能够专注于评估模型对复杂指令的理解与遵循能力,从而推动RLHF流程中奖励信号的精准建模与优化。
实际应用
实际应用中,该数据集可被直接集成至大语言模型的微调与对齐管道中,用于训练能够区分高质量与低质量响应的奖励模型。在对话系统、代码生成、机器人控制等需要严格遵循复杂指令的场景下,企业可借助该数据集优化模型的安全性与用户意图匹配度。此外,其cvs格式的便捷性降低了数据预处理门槛,使得中小型团队也能高效开展RLHF实验,加速从研究到产品落地的转化进程。
衍生相关工作
该数据集衍生了一系列具有影响力的研究工作,包括基于提示增强的奖励模型架构设计、工具感知的RLHF算法改进,以及面向多任务场景的动态提示生成方法。例如,后续研究利用其system_prompt和tools字段,探索了结构化提示对模型推理能力的影响,并催生出如“上下文依赖奖励建模”和“工具使能的对齐策略”等新方向。这些工作不仅深化了对RLHF中提示工程作用的理解,也为构建更可信赖的通用人工智能系统奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


