recmeapp/mobilerec
收藏Hugging Face2023-02-21 更新2024-03-04 收录
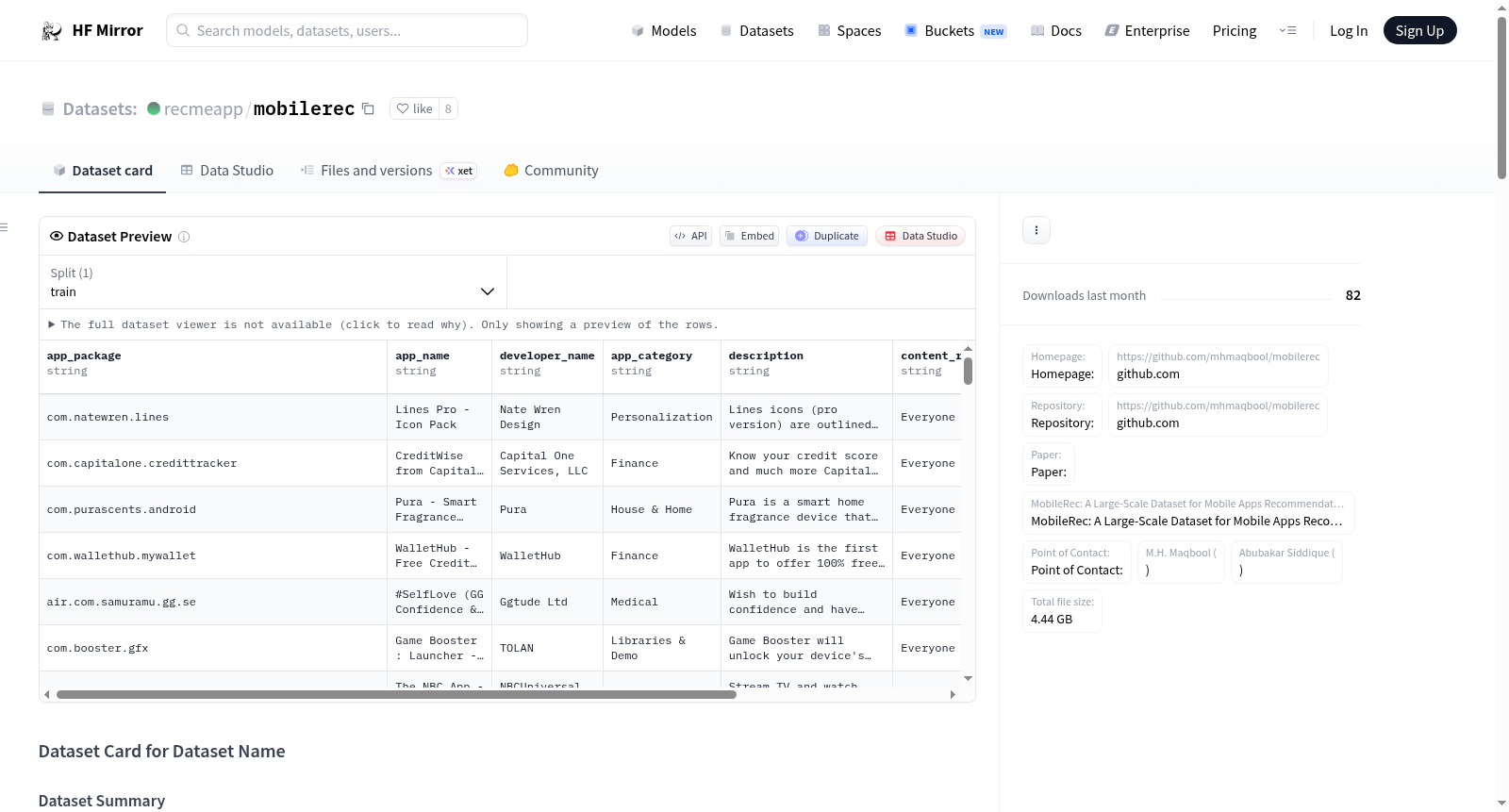
下载链接:
https://hf-mirror.com/datasets/recmeapp/mobilerec
下载链接
链接失效反馈官方服务:
资源简介:
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/datasets-cards
{}
---
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- https://github.com/mhmaqbool/mobilerec
- **Repository:**
- https://github.com/mhmaqbool/mobilerec
- **Paper:**
- MobileRec: A Large-Scale Dataset for Mobile Apps Recommendation
- **Point of Contact:**
- M.H. Maqbool (hasan.khowaja@gmail.com)
- Abubakar Siddique (abubakar.ucr@gmail.com)
### Dataset Summary
MobileRec is a large-scale app recommendation dataset. There are 19.3 million user\item interactions. This is a 5-core dataset.
User\item interactions are sorted in ascending chronological order. There are 0.7 million users who have had at least five distinct interactions.
There are 10173 apps in total.
### Supported Tasks and Leaderboards
Sequential Recommendation
### Languages
English
## How to use the dataset?
```
from datasets import load_dataset
import pandas as pd
# load the dataset and meta_data
mbr_data = load_dataset('recmeapp/mobilerec', data_dir='interactions')
mbr_meta = load_dataset('recmeapp/mobilerec', data_dir='app_meta')
# Save dataset to .csv file for creating pandas dataframe
mbr_data['train'].to_csv('./mbr_data.csv')
# Convert to pandas dataframe
mobilerec_df = pd.read_csv('./mbr_data.csv')
# How many interactions are there in the MobileRec dataset?
print(f'There are {len(mobilerec_df)} interactions in mobilerec dataset.')
# How many unique app_packages (apps or items) are there?
print(f'There are {len(mobilerec_df["app_package"].unique())} unique apps in mobilerec dataset.')
# How many unique users are there in the mobilerec dataset?
print(f'There are {len(mobilerec_df["uid"].unique())} unique users in mobilerec dataset.')
# How many categoris are there?
print(f'There are {len(mobilerec_df["app_category"].unique())} unique categories in mobilerec dataset.')
```
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
# 关于数据集卡片元数据的参考规范,请参阅:https://github.com/huggingface/hub-docs/blob/main/datasetcard.md?plain=1
# 文档/使用指南:https://huggingface.co/docs/hub/datasets-cards
{}
---
# 数据集卡片:数据集名称
## 数据集概览
- **主页:**
- https://github.com/mhmaqbool/mobilerec
- **仓库:**
- https://github.com/mhmaqbool/mobilerec
- **论文:**
- 《MobileRec:面向移动应用推荐的大规模数据集》
- **联系人:**
- M.H. Maqbool (hasan.khowaja@gmail.com)
- Abubakar Siddique (abubakar.ucr@gmail.com)
### 数据集摘要
MobileRec是一款大规模移动应用推荐数据集,共计包含1930万条用户-项目交互记录,属于5-core(5-core dataset)数据集。所有用户-项目交互记录均按时间升序排列。数据集内共有70万用户,每位用户至少拥有5次不同的交互记录;总计涵盖10173款移动应用。
### 支持任务与排行榜(Leaderboards)
序列推荐
### 语言
英语
## 数据集使用方法
from datasets import load_dataset
import pandas as pd
# load the dataset and meta_data
mbr_data = load_dataset('recmeapp/mobilerec', data_dir='interactions')
mbr_meta = load_dataset('recmeapp/mobilerec', data_dir='app_meta')
# Save dataset to .csv file for creating pandas dataframe
mbr_data['train'].to_csv('./mbr_data.csv')
# Convert to pandas dataframe
mobilerec_df = pd.read_csv('./mbr_data.csv')
# How many interactions are there in the MobileRec dataset?
print(f'There are {len(mobilerec_df)} interactions in mobilerec dataset.')
# How many unique app_packages (apps or items) are there?
print(f'There are {len(mobilerec_df["app_package"].unique())} unique apps in mobilerec dataset.')
# How many unique users are there in the mobilerec dataset?
print(f'There are {len(mobilerec_df["uid"].unique())} unique users in mobilerec dataset.')
# How many categoris are there?
print(f'There are {len(mobilerec_df["app_category"].unique())} unique categories in mobilerec dataset.')
[需补充更多信息]
## 数据集结构
### 数据实例
[需补充更多信息]
### 数据字段
[需补充更多信息]
### 数据划分
[需补充更多信息]
## 数据集构建
### 遴选依据
[需补充更多信息]
### 源数据
#### 初始数据收集与归一化
[需补充更多信息]
#### 源语言生产者是谁?
[需补充更多信息]
### 标注信息
#### 标注流程
[需补充更多信息]
#### 标注人员是谁?
[需补充更多信息]
### 个人与敏感信息
[需补充更多信息]
## 数据使用注意事项
### 数据集的社会影响
[需补充更多信息]
### 偏差讨论
[需补充更多信息]
### 其他已知局限性
[需补充更多信息]
## 附加信息
### 数据集策展人
[需补充更多信息]
### 许可信息
[需补充更多信息]
### 引用信息
[需补充更多信息]
### 贡献说明
[需补充更多信息]
提供机构:
recmeapp
原始信息汇总
数据集概述
数据集名称
MobileRec
数据集描述
数据集总结
- 类型: 大型移动应用推荐数据集
- 用户-项目交互: 19.3 million
- 核心数据: 5-core
- 用户数量: 0.7 million (至少有五次交互的用户)
- 应用数量: 10173
支持的任务
- 序列推荐
语言
- 英语
如何使用数据集
- 使用
datasets库加载数据集和元数据。 - 将数据集保存为
.csv文件,并转换为 pandas DataFrame。 - 可以查询数据集中的交互次数、唯一应用数量、唯一用户数量和唯一类别数量。
搜集汇总
数据集介绍
构建方式
MobileRec数据集专为移动应用推荐领域而构建,旨在解决大规模应用推荐中的序列建模问题。该数据集源自真实用户与移动应用的交互历史,经过严格的5-core过滤处理,确保每位用户至少拥有五次不同的交互记录,从而提升数据的可靠性与稠密度。数据集包含约1930万条用户-应用交互记录,覆盖超过70万用户和10173个应用,所有交互均按时间升序排列,以保留用户行为的时序依赖关系,为序列推荐任务提供坚实的数据基础。
特点
MobileRec数据集以大规模、高覆盖和时序完整性著称。其交互记录数量高达1930万,用户规模达70万,应用种类超过一万,充分反映了移动应用生态的多样性与复杂性。数据经过5-core筛选,有效降低了冷启动用户和稀疏交互带来的噪声,同时保持了用户行为序列的自然连续性。此外,应用元数据(如类别信息)的整合进一步丰富了数据维度,为多角度分析用户偏好提供了支持。
使用方法
使用MobileRec数据集时,可通过HuggingFace的datasets库便捷加载。首先,利用load_dataset函数分别加载交互数据与元数据,其中交互数据位于'interactions'子目录,元数据位于'app_meta'子目录。加载后,可将训练集转换为CSV格式以创建Pandas DataFrame,便于后续分析。通过DataFrame可快速统计交互总数、唯一应用数、唯一用户数及类别数量。该数据集默认划分为训练集,适用于序列推荐模型的训练与评估,用户可结合自定义逻辑进行进一步的数据划分与预处理。
背景与挑战
背景概述
移动应用推荐系统作为个性化服务的重要一环,旨在从海量应用中精准捕捉用户偏好,提升用户体验与留存率。然而,现有数据集多聚焦于通用商品或内容推荐,缺乏针对移动应用生态的专门资源,限制了该领域模型的泛化能力与实用性。MobileRec数据集由M.H. Maqbool与Abubakar Siddique等人于近年创建,依托GitHub平台公开,旨在填补这一空白。该数据集包含约1930万条用户-应用交互记录,覆盖70万用户与10173个应用,所有交互按时间升序排列,并经过5-core过滤以确保数据质量。其核心研究问题聚焦于序列推荐任务,即通过用户历史行为序列预测下一款可能感兴趣的应用,为移动应用推荐算法的研发与评估提供了大规模、标准化的基准,显著推动了该方向的发展。
当前挑战
MobileRec数据集所面临的挑战多维且深刻。首先,在领域问题层面,移动应用推荐需应对用户兴趣的动态演化与冷启动问题——用户行为序列虽按时间排序,但应用生态更新迅速,新应用缺乏历史交互,导致模型难以有效泛化。其次,数据稀疏性依然突出,尽管经过5-core处理,但70万用户与10173个应用构成的交互矩阵仍高度稀疏,加剧了推荐精度提升的难度。在构建过程中,挑战包括从原始应用商店日志中提取并规范化交互数据,确保时间戳准确性与隐私去标识化;同时,应用元数据的整合(如类别信息)需处理不一致性与缺失值,以维护数据集的一致性与可靠性。这些困难共同构成了推动更鲁棒推荐算法设计的核心驱动力。
常用场景
经典使用场景
MobileRec数据集作为移动应用推荐领域的里程碑式资源,其最经典的使用场景在于支撑序列化推荐模型的训练与评估。该数据集包含了1930万条用户与应用的交互记录,并按时间升序排列,能够天然地捕捉用户行为的时间动态性。研究者通常利用其五核(5-core)过滤后的约70万用户与10173款应用构成的交互序列,构建基于Transformer、GRU或注意力机制的序列推荐模型,以预测用户下一个可能安装或使用的移动应用,从而推动移动应用商店个性化推荐技术的边界。
解决学术问题
该数据集有效解决了移动应用推荐研究中长期存在的两大核心问题:一是缺乏大规模、真实且带有时间戳的用户行为数据,导致模型泛化能力受限;二是传统推荐算法在移动场景下难以处理应用冷启动和用户兴趣漂移。MobileRec通过提供海量、有序的交互实例,为研究者提供了探索用户短期偏好演化与长期兴趣融合的基准平台。其发布显著推动了序列化推荐、跨域推荐及用户行为建模等学术方向的发展,为验证算法在稀疏性与动态性环境下的鲁棒性提供了关键支撑。
衍生相关工作
MobileRec数据集的发布催生了一系列经典衍生工作,包括基于图神经网络的移动应用会话推荐框架、融合应用元数据(如类别与描述)的多模态序列模型,以及针对冷启动场景的元学习推荐方法。这些工作不仅扩展了原始数据集的应用边界,还引入了诸如对比学习、知识蒸馏等前沿技术,进一步提升了推荐系统的准确性与可解释性。同时,该数据集也常被用作基准,与Amazon、Yelp等传统推荐数据集进行对比分析,推动了移动领域推荐算法的标准化评估体系建立。
以上内容由遇见数据集搜集并总结生成


