OSACPairs
收藏Hugging Face2025-11-04 更新2025-11-05 收录
下载链接:
https://huggingface.co/datasets/reem444/OSACPairs
下载链接
链接失效反馈官方服务:
资源简介:
OSACPairs是一个阿拉伯语句子对数据集,用于检测句子是否具有相同意义(Paraphrase detection)。该数据集从Open-Source Arabic Corpora (OSAC)衍生而来,OSAC包含了超过22,000个阿拉伯语文档,涵盖10个类别。数据集包括通过改写工具生成的改写句子对和随机选取的非改写句子对。数据集的结构包括文件名、原始句子、改写句子和标签。数据集分为训练集、验证集和测试集。
OSACPairs is an Arabic sentence pair dataset dedicated to paraphrase detection, which aims to determine whether two sentences convey identical semantic meanings. This dataset is derived from the Open-Source Arabic Corpora (OSAC), which contains over 22,000 Arabic documents spanning 10 categories. The dataset includes two types of sentence pairs: paraphrase pairs generated by paraphrasing tools and non-paraphrase pairs randomly selected. The dataset structure consists of file names, original sentences, paraphrased sentences and labels. Additionally, the dataset is divided into training, validation and test sets.
创建时间:
2025-11-04
原始信息汇总
OSACPairs数据集概述
数据集简介
OSACPairs是一个用于复述检测的阿拉伯语句对数据集。该数据集源自开放源代码阿拉伯语语料库(OSAC),该语料库包含超过22,000个阿拉伯语文档,涵盖10个类别(经济学、历史、娱乐、教育与家庭、宗教与教法、体育、健康、天文学、法律、故事和烹饪食谱)。
数据集内容
- 包含从OSAC文章中提取的复述和非复述句对
- 正例通过从文档中选取句子并使用复述工具生成复述版本获得
- 负例通过从同一文档中随机选择两个不同句子获得
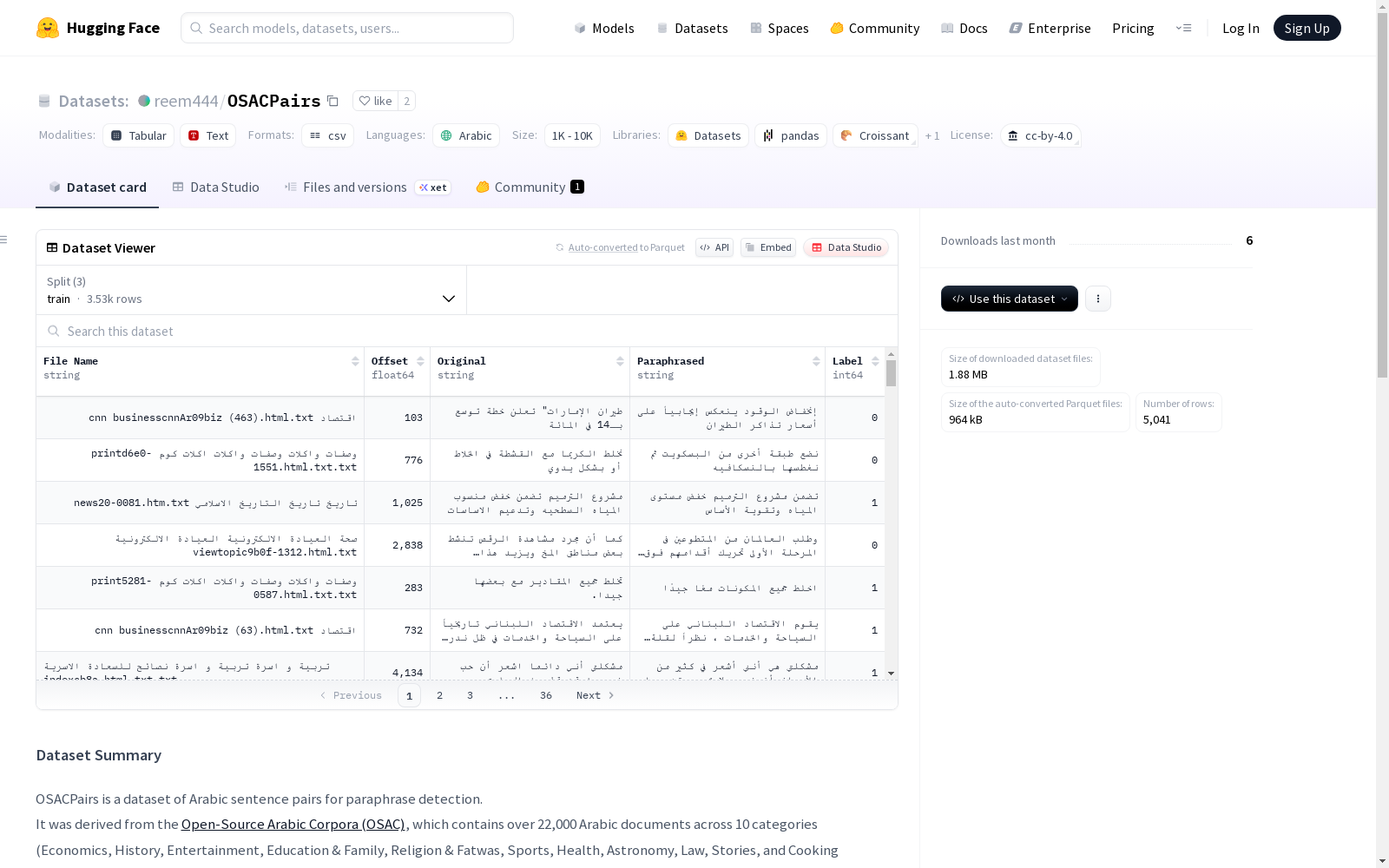
数据结构
| 字段名称 | 描述 |
|---|---|
| File Name | OSAC原始文档文件名 |
| Offset | 原始句子在文件中的位置 |
| Original | 从OSAC提取的原始句子 |
| Paraphrased | 复述或随机配对的句子 |
| Label | 1表示复述对,0表示非复述对 |
数据规模与划分
- 总句对数量:5,041对
- 训练集:3,528对(70%)
- 验证集:504对(10%)
- 测试集:1,009对(20%)
许可证
- 使用CC-BY-4.0许可证
语言
- 阿拉伯语
规模类别
- 1K<n<10K
快速开始
python pip install datasets
from datasets import load_dataset dataset = load_dataset("reem444/OSACPairs")
搜集汇总
数据集介绍
构建方式
在阿拉伯语自然语言处理领域,OSACPairs数据集通过系统化流程构建而成。其正例样本源自开源阿拉伯语语料库的原始句子,采用专业复述工具生成语义等效的改写版本;负例则通过同一文档内随机选取两个无关句子组合形成。这种基于人工标注与自动化工具结合的构建策略,既确保了语义关联的准确性,又维护了语言特征的多样性。
特点
该数据集囊括涵盖经济、法律、宗教等十大领域的阿拉伯语文本,呈现丰富的语体风格与专业术语。其核心价值在于包含5,041组经过严格标注的句对,每个样本均标注有原始文档来源及句子位置信息,为研究阿拉伯语复述检测提供了可靠的实验基础。数据划分遵循7:1:2的比例分配训练、验证与测试集,保障模型评估的科学性。
使用方法
研究者可通过HuggingFace生态系统快速调用该数据集,仅需安装datasets库并执行加载指令即可获取结构化数据。数据字段包含原始句子、复述文本及二分类标签,支持端到端的阿拉伯语复述识别模型开发。该资源特别适用于跨领域语义相似度计算、阿拉伯语文本生成质量评估等研究方向。
背景与挑战
背景概述
阿拉伯语自然语言处理领域长期面临语料资源稀缺的困境,OSACPairs数据集于2023年应运而生,由研究团队基于开源阿拉伯语语料库OSAC构建。该数据集聚焦于阿拉伯语句对复述检测这一核心任务,通过从涵盖经济、历史、宗教等十类主题的2.2万篇文档中提取语料,为阿拉伯语语义相似度计算提供了重要基准。其创新性地采用正负例组合构建模式,不仅填补了阿拉伯语复述识别数据空白,更为跨语言自然语言理解研究提供了关键支撑。
当前挑战
阿拉伯语复述检测面临语言形态复杂性与方言多样性的双重考验,动词变位丰富和词根派生规则增加了语义对齐难度。在数据构建过程中,自动复述工具对阿拉伯语语法特性的适应度不足,可能导致句式结构失真;而从同文档随机抽取负样本的策略,虽能确保主题相关性,但难以规避语义隐式关联的干扰。此外数据集规模受限及领域覆盖不均衡,也给模型泛化能力带来潜在挑战。
常用场景
经典使用场景
在阿拉伯语自然语言处理领域,OSACPairs数据集为文本相似度分析提供了重要支持。该数据集通过构建正负样本对,广泛应用于阿拉伯语复述检测模型的训练与评估,帮助研究者深入理解语义等价的边界条件。其多领域语料覆盖特性,使得模型能够适应从宗教文献到科技文本的多样化表达风格,为跨领域语义匹配研究奠定基础。
解决学术问题
该数据集有效解决了阿拉伯语复述识别中的标注数据稀缺问题。通过系统化构建语义等价与非等价样本,为深度学习模型提供了可靠的监督信号,显著提升了阿拉伯语语义相似度计算的准确度。其精心设计的正负样本平衡机制,为研究语言变异现象与语义保持的辩证关系提供了实验基础,推动了低资源语言理解技术的发展。
衍生相关工作
基于OSACPairs的语义表示研究催生了多项创新工作,包括融合词根特征的阿拉伯语BERT变体与注意力机制优化方案。该数据集启发的跨语言迁移学习框架,成功将阿拉伯语复述检测经验推广至其他闪族语言。相关研究还衍生出面向法律文本的专用检测模型,为阿拉伯语司法文书智能处理开辟了新路径。
以上内容由遇见数据集搜集并总结生成


