有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
该数据集包含 6,235 行 和 12 列。
列信息:
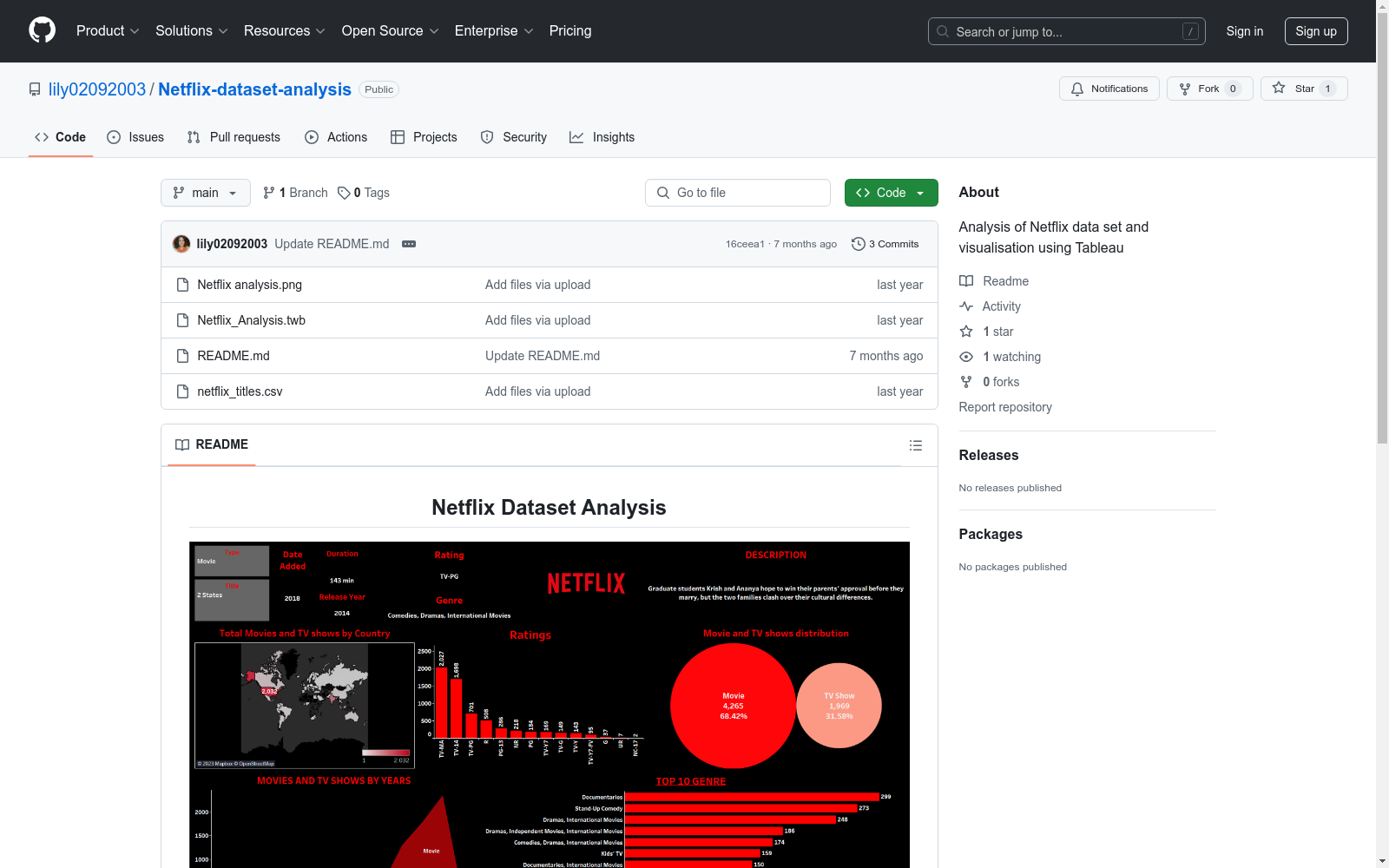
钻孔成像测井解译数据(2021-2022年)
利用测井设备实时获取的雄安新区D19,D21,D22,冀中坳陷地区JZ01,JZ04钻孔的测井数据,并由Techlog软件 WBI井眼成像解释模块解译的裂缝原始数据
国家地球系统科学数据中心 收录
CWRU bearing fault dataset
CWRU数据集的故障类别被总结为总共十类数据,包括一种正常数据和九种故障数据。该数据集包含两种采样频率的数据,12k Hz和48k Hz,正常数据除外,它只有48k Hz的采样频率。对于这些数据,我们使用12k Hz采样频率的数据。
github 收录
轴承故障数据集
本项目集成了多个公开的轴承故障数据集,所有数据均被处理为1秒/个的数据样本,并使用fft得到其频域特征。支持通过数据集、通道、故障、严重程度对所有样本进行筛选,并选择时域或频域显示。
github 收录
crack segmentation dataset
We have open-sourced a large-scale, meticulously annotated crack segmentation dataset, which is aimed at the most common on-board camera scenarios. This dataset consists of 3,540 high-resolution images (3840×2160 pixels) shot from several roads in Shandong Province, China, using a camera-equipped vehicle. The collected images are then meticulously annotated with pixel-level semantic masks by a team of professionals who meticulously annotated the locations and shapes of cracks on the images using the CVAT annotation tool. To note, the annotation process for each image underwent thorough inspection and verification to ensure the accuracy and consistency of the labels. Furthermore, we ensured that the dataset includes images captured under different road types (e.g., freeways, national and provincial highways, etc.) to enhance the model's generalization capability.
github 收录
中国区域交通网络数据集
该数据集包含中国各区域的交通网络信息,包括道路、铁路、航空和水路等多种交通方式的网络结构和连接关系。数据集详细记录了各交通节点的位置、交通线路的类型、长度、容量以及相关的交通流量信息。
data.stats.gov.cn 收录