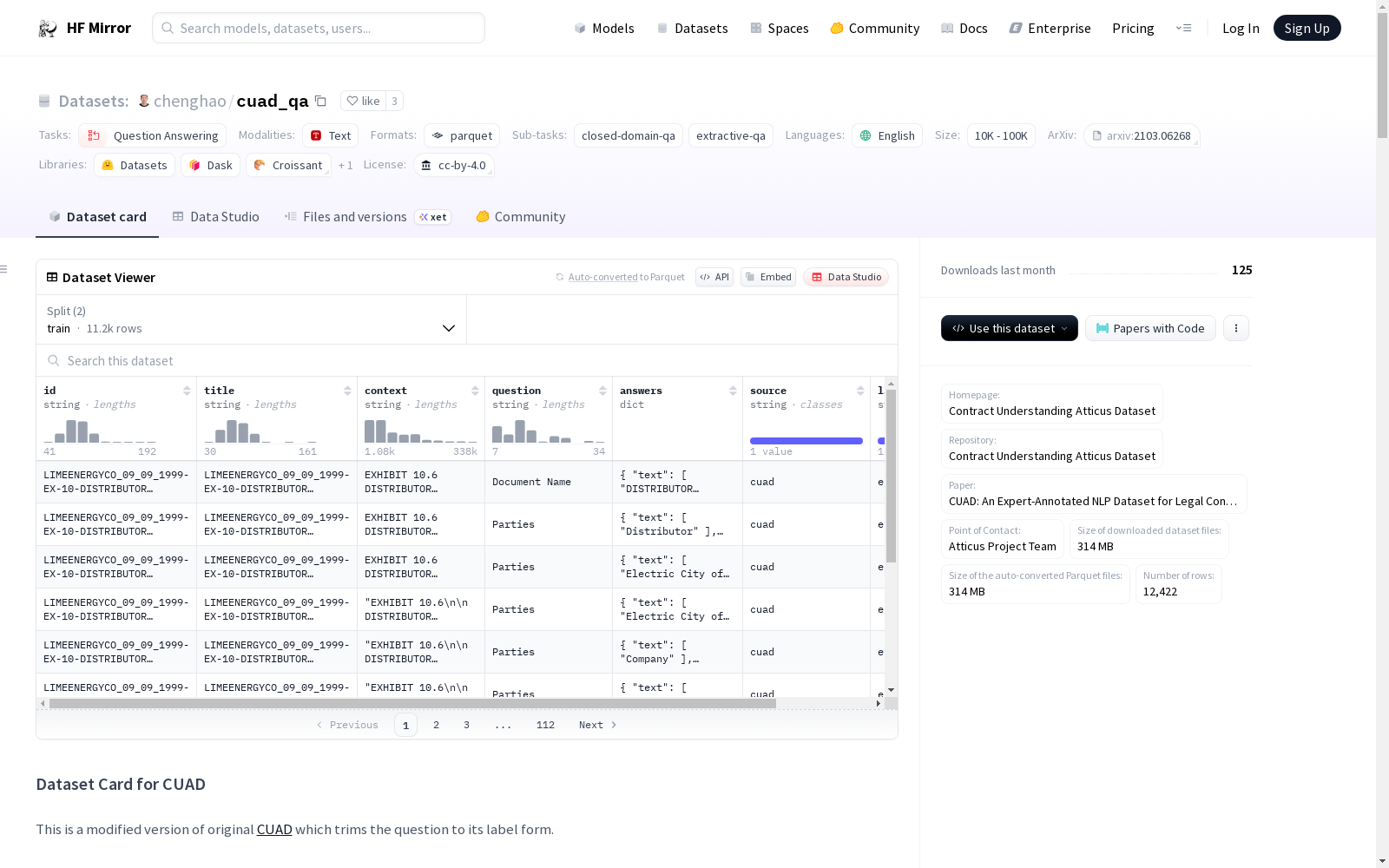
chenghao/cuad_qa
收藏Hugging Face2022-09-14 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/chenghao/cuad_qa
下载链接
链接失效反馈官方服务:
资源简介:
CUAD(Contract Understanding Atticus Dataset)v1是一个包含510份商业法律合同中超过13,000个标签的语料库,这些标签由法律专家手动标注,用于识别41个重要条款类别。该数据集由The Atticus Project, Inc.维护,旨在支持法律合同审查的自然语言处理研究和开发。数据集包括训练集和测试集,分别包含22,450和4,182个样本。数据集的创建目的是为了减少合同审查的社会成本,并研究NLP模型在专业领域的泛化能力。
CUAD (Contract Understanding Atticus Dataset) v1 is a corpus containing over 13,000 manually annotated labels from 510 commercial legal contracts. These labels are manually marked by legal experts to identify 41 critical clause categories. Maintained by The Atticus Project, Inc., this dataset aims to support natural language processing (NLP) research and development for legal contract review. The dataset includes a training set and a test set, with 22,450 and 4,182 samples respectively. It was developed to reduce the social costs of contract review and to study the generalization capability of NLP models in professional domains.
提供机构:
chenghao
原始信息汇总
数据集概述:CUAD
数据集描述
- 名称:CUAD(Contract Understanding Atticus Dataset)
- 语言:英语
- 许可:CC-BY-4.0
- 多语言性:单语种
- 大小:10K<n<100K
- 来源:原始数据
- 任务类别:问答(question-answering)
- 任务ID:
- closed-domain-qa
- extractive-qa
- 训练/评估索引:
- 配置:默认
- 任务:问答
- 任务ID:extractive_question_answering
- 分割:
- 训练分割:train
- 评估分割:test
- 列映射:
- 问题:question
- 上下文:context
- 答案:
- 文本:text
- 答案开始位置:answer_start
- 指标:
- 类型:cuad
- 名称:CUAD
数据集结构
- 数据实例:包含问题、上下文、答案等字段。
- 数据字段:
- id:字符串
- title:字符串
- context:字符串
- question:字符串
- answers:字典,包含text(字符串)和answer_start(整数)
- 数据分割:分为训练集和测试集,具体样本数为22450(训练)和4182(测试)。
数据集创建
- 注释创建者:专家生成
- 源数据:来自EDGAR系统的商业合同
- 注释过程:涉及法律学生和律师的多步骤标注过程,确保准确性。
- 个人和敏感信息:部分合同条款因保密原因被编辑。
搜集汇总
数据集介绍
构建方式
CUAD数据集由The Atticus Project团队构建,该团队致力于通过自然语言处理技术提高法律合同审查的自动化水平。数据集包括510份商业法律合同的超过13,000个标签,这些标签由律师和学生手动标注,旨在识别41个律师在审查与公司交易相关的合同时所寻找的重要条款类别。数据集的构建经历了多个阶段,包括法律学生的培训、合同审查和标注、关键词搜索、类别报告审查、律师审查以及最终报告的生成。数据来源为美国证券交易委员会(SEC)的EDGAR数据库,其中包含美国上市公司的合同。
特点
CUAD数据集的特点包括:1. 高质量的专家标注:数据集由经验丰富的律师和经过培训的法律学生进行标注,确保了数据的高质量和准确性。2. 多样化的合同类型:数据集包含了25种不同类型的商业合同,涵盖了广泛的法律领域。3. 详细的标注类别:数据集包含了41个不同的标注类别,涵盖了合同审查中的关键要素。4. 明确的数据结构:数据集以JSON格式组织,包含了合同标题、上下文、问题和答案等字段,方便研究人员使用。5. 开放的许可协议:数据集采用Creative Commons Attribution 4.0 (CC BY 4.0)许可协议,可供商业和非商业用途免费使用。
使用方法
使用CUAD数据集进行研究和开发时,可以按照以下步骤进行:1. 数据准备:下载CUAD数据集,并将其解压到本地目录。2. 数据加载:使用适合的编程语言和库加载JSON格式的数据集,例如Python的pandas库。3. 数据探索:对数据集进行初步的探索,了解其结构和内容。4. 模型训练:使用自然语言处理模型对数据集进行训练,例如基于Transformer的模型。5. 模型评估:使用测试集对训练好的模型进行评估,例如计算准确率、召回率和F1分数等指标。6. 应用开发:将训练好的模型应用于实际的法律合同审查任务,例如自动识别合同中的关键条款。
背景与挑战
背景概述
合同理解Atticus数据集(CUAD)v1是一个包含超过510份商业法律合同的人工标注数据集,共包含13,000多个标签。该数据集由Atticus项目团队创建并维护,旨在支持自然语言处理(NLP)在法律合同审查领域的研究与发展。该数据集的研究背景源于合同审查这一高价值的专业任务,这一任务通常耗费大量的人力、物力和时间。许多律师事务所将大约50%的时间用于审查合同,且律师的收费通常在每小时500至900美元之间。因此,许多交易仅为了验证合同中不存在有问题的义务或要求,就需花费公司数十万美元。合同审查的自动化,通过公开释放高质量数据和微调模型,可以增加小企业和个人获得法律支持的机会,使法律支持不再仅限于富裕公司。为了减少合同审查的社会成本,并研究NLP模型在专业领域中的泛化能力,CUAD数据集被引入。该数据集由数十名法学生标注者、律师和机器学习研究人员经过一年的努力创建,包括超过500份合同和超过13,000个专家标注,涵盖41个标签类别。对于每个不同的标签,模型必须学习突出合同中最相关的部分,使任务成为在 haystack 中寻找 needles。
当前挑战
CUAD数据集在构建过程中面临了多项挑战。首先,合同审查是一个高度专业化的任务,需要大量的专业知识。其次,合同数据通常包含敏感信息,需要在数据集创建过程中确保隐私保护。第三,合同审查任务的多样性导致数据集构建过程中需要考虑多种不同的合同类型和条款。第四,合同审查的自动化需要高精度的模型,而模型训练需要大量高质量的标注数据。第五,合同审查任务的复杂性和多样性导致模型泛化能力不足,需要进一步的研究和改进。
常用场景
经典使用场景
CUAD数据集作为法律合同审查的自然语言处理(NLP)领域的一个重要资源,其经典使用场景在于提供了一组标注过的合同数据,用于训练和评估模型在识别合同中关键条款的能力。通过对510份商业合同中的超过13,000个标签进行标注,CUAD支持模型学习识别41种重要条款类别,这对于法律专业人士来说至关重要。这一能力使得模型能够在合同审查过程中自动化部分工作,从而减轻法律专业人士的负担,并提高合同审查的效率和准确性。
解决学术问题
在学术研究方面,CUAD数据集解决了法律合同审查领域长期缺乏大规模、高质量标注数据的问题。法律合同审查是一个高度专业化的任务,以往需要大量人工时间、金钱和注意力。CUAD的推出为研究者提供了宝贵的资源,使得他们能够研究和开发新的NLP模型,以自动识别合同中的关键条款。这对于推动法律合同审查的自动化和智能化具有重要意义。
衍生相关工作
CUAD数据集的推出也衍生了一系列相关的研究工作。研究者们利用CUAD数据集,开发了多种基于深度学习的合同审查模型,并在多个任务上取得了显著的性能提升。此外,一些研究者还基于CUAD数据集,研究了法律合同审查中的各种挑战,如条款识别的准确性、合同结构的复杂性等,为法律合同审查领域的研究提供了新的思路和方向。
以上内容由遇见数据集搜集并总结生成


