fineweb-conversational
收藏Hugging Face2025-04-05 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/EpGuy/fineweb-conversational
下载链接
链接失效反馈官方服务:
资源简介:
fineweb-conversational数据集是一个专门为训练对话型AI模型而设计的指令遵循格式数据集。它将经过清洗和去重的英文网络数据转换为提示-完成结构,用于模拟用户查询和响应。该数据集由EpGuy策划,采用odc-by许可证,并处于持续开发中,会定期进行更新。
The fineweb-conversational dataset is an instruction-following format dataset specifically designed for training conversational AI models. It converts cleaned and deduplicated English web data into prompt-completion structures to simulate user queries and responses. This dataset is curated by EpGuy, released under the odc-by license, and is under active development with regular updates.
创建时间:
2025-04-04
原始信息汇总
FineWeb-Conversational 数据集概述
1. 数据集基本信息
- 许可证: odc-by
- 来源数据集: HuggingFaceFW/fineweb
- 任务类别: 文本生成
- 语言: 英语 (en)
- 标签: 对话式、指令式、聊天
- 规模分类: 1K<n<10K
- 数据集名称: FineWeb-Conversational
- 配置:
- 默认配置 (default)
- 数据文件:
- 训练集 (train): data.parquet
- 数据文件:
- 默认配置 (default)
2. 数据集概述
- 目的: 用于训练遵循指令格式的对话AI模型
- 数据来源: 来自FineWeb数据集的清洗和去重后的英文网页数据
- 维护状态: 由EpGuy维护,目前处于活跃开发阶段,定期更新
3. 数据结构与创建过程
- 数据格式: CSV
- 主要列:
- prompt: 使用Google Gemini 2.0 Flash模型生成的模拟用户查询的AI生成文本
- completion: 来自FineWeb数据集的原始文本,作为响应
- 创建过程:
- 使用Python脚本:
- 通过元提示指导Gemini 2.0 Flash生成自然、开放式的提示
- 将这些生成的提示与直接从FineWeb获取的相应完成配对
- FineWeb数据源自CommonCrawl (2013-2024)
- 使用Python脚本:
4. 使用与限制
- 用途: 主要用于微调大型语言模型以进行对话任务和指令遵循
- 限制:
- 偏见: 继承自网页来源数据的社会偏见和潜在有害内容
- AI生成提示: 提示生成过程可能偶尔产生不现实或不对齐的查询
- 数据完整性: 数据集尚未最终完成,随着更多数据的处理将进行更新
- 敏感信息: 尽管进行了匿名化处理,仍可能包含一些个人和敏感信息(PII)
5. 引用
bibtex @inproceedings{ penedo2024the, title={The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale}, author={Guilherme Penedo and Hynek Kydl{\i}{v{c}}ek and Loubna Ben allal and Anton Lozhkov and Margaret Mitchell and Colin Raffel and Leandro Von Werra and Thomas Wolf}, booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track}, year={2024}, url={https://openreview.net/forum?id=n6SCkn2QaG} }
搜集汇总
数据集介绍
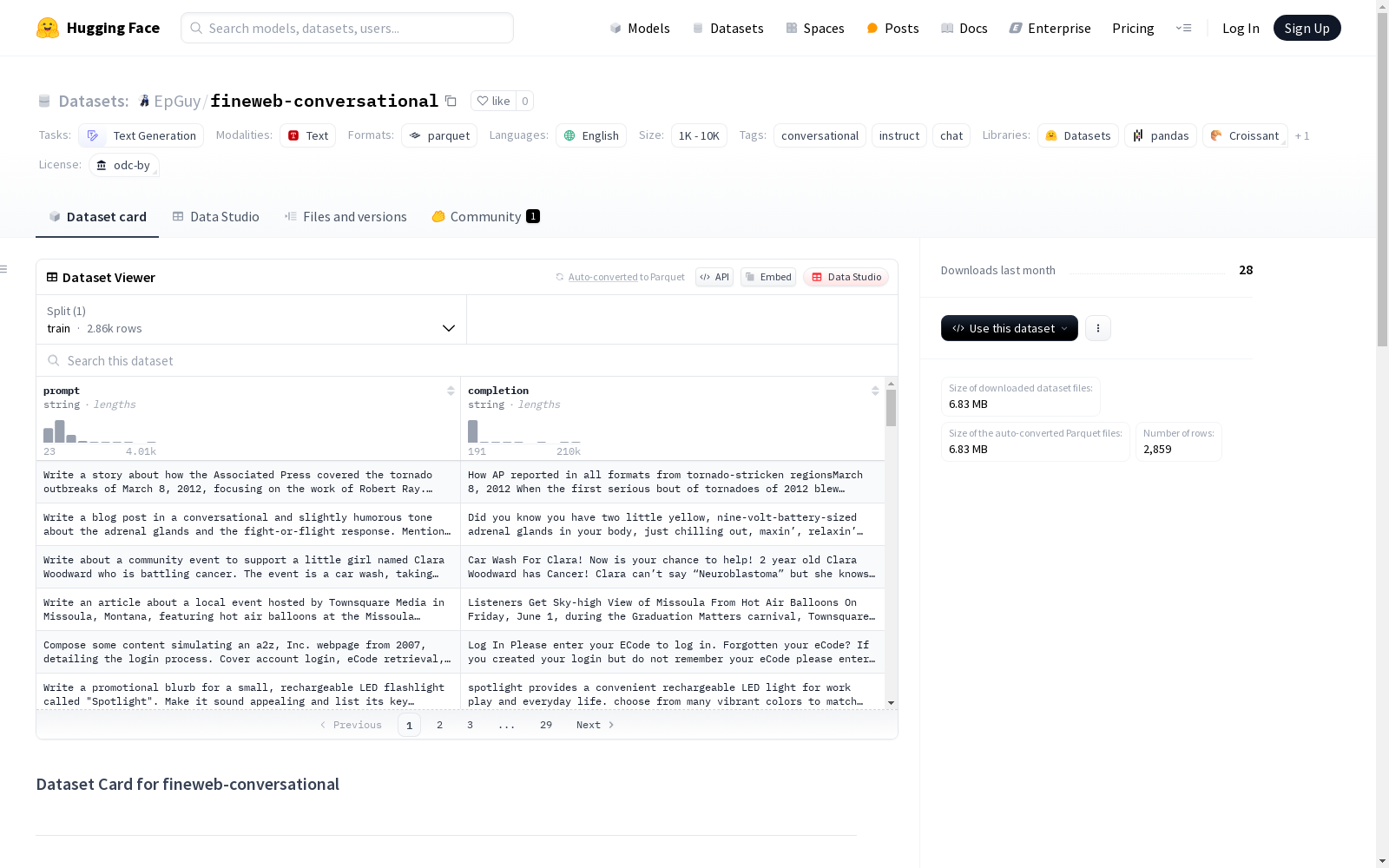
构建方式
在自然语言处理领域,fineweb-conversational数据集通过创新的数据重构方法,将FineWeb数据集中的原始文本转化为对话式指令微调格式。该数据集采用两阶段构建流程:首先运用Google Gemini 2.0 Flash模型生成符合自然对话特性的提示文本,随后将FineWeb中经过清洗和去重的网页文本作为对应回复。这种基于元提示的自动化构建策略,既保留了原始数据的语言多样性,又赋予了其对话交互的特性。
特点
作为专为对话式AI训练设计的语料库,fineweb-conversational最显著的特征在于其精心设计的提示-回复对结构。数据集包含数千条经过筛选的英语对话样本,每条数据均由AI生成的开放式提问与真实网页内容回复组成。这种独特的构造方式既模拟了真实人机对话场景,又继承了FineWeb数据集覆盖2013-2024年网络文本的时空广度。值得注意的是,该数据集仍处于动态更新阶段,持续优化数据质量与规模。
使用方法
该数据集主要服务于对话生成模型的微调任务,研究人员可通过加载标准parquet格式文件获取结构化数据。典型使用场景包括但不限于:训练模型理解复杂指令、提升多轮对话连贯性、增强开放域问答能力。使用时应充分注意数据可能存在的网络偏见及残留敏感信息,建议配合去偏算法和内容过滤机制。由于数据集采用odc-by许可,使用者需遵循相应引用规范,并在研究中注明原始FineWeb数据集的贡献。
背景与挑战
背景概述
fineweb-conversational数据集由研究人员EpGuy基于FineWeb数据集精心构建,旨在为对话式人工智能模型的训练提供高质量的指令遵循格式数据。该数据集将经过清洗和去重的英文网页数据转化为提示-完成结构,专注于提升模型在开放域对话中的表现。作为FineWeb数据集的重要衍生成果,其构建过程充分利用了Google Gemini 2.0 Flash模型生成自然流畅的用户查询提示,并与原始网页内容进行配对。该数据集的出现为对话系统研究领域注入了新的活力,特别是在指令微调和开放域对话生成方面展现出独特价值。
当前挑战
该数据集面临多重挑战:在领域问题层面,如何有效消除原始网页数据中潜在的社会偏见和有害内容成为关键难题;同时,AI生成的提示与真实用户查询之间的分布差异可能影响模型的实际应用效果。在构建过程中,数据清洗的完整性面临挑战,尤其是对个人敏感信息的彻底匿名化处理;此外,提示生成模型的局限性可能导致部分提示与完成内容出现语义偏差,这对数据质量提出了更高要求。随着数据集持续更新,如何保持版本迭代中的一致性与可靠性也是需要持续关注的问题。
常用场景
经典使用场景
在自然语言处理领域,fineweb-conversational数据集为对话式人工智能模型的训练提供了高质量的指令遵循数据。该数据集通过将FineWeb数据集中的原始文本转化为提示-补全结构,特别适合用于微调大语言模型,使其能够更好地理解并响应开放式的用户查询。这种结构化的对话数据对于提升模型的上下文理解能力和多轮对话流畅性具有显著效果。
实际应用
在实际应用中,fineweb-conversational数据集已被广泛用于开发各类智能对话系统,包括客服机器人、虚拟助手和教育领域的智能辅导系统。其丰富的对话结构和真实的语言表达方式,使得基于该数据集训练的模型能够生成更加自然、符合人类交流习惯的响应。特别是在需要处理复杂查询的行业场景中,这种高质量的对话数据显得尤为重要。
衍生相关工作
基于fineweb-conversational数据集,研究者们开展了一系列关于对话系统优化的经典工作。这些工作主要集中在提升模型的多轮对话能力、减少有害内容生成以及改善指令遵循的准确性等方面。该数据集也为Few-shot学习在对话系统中的应用研究提供了重要数据支持,推动了基于提示工程的对话模型微调技术的发展。
以上内容由遇见数据集搜集并总结生成


