DFNDR-12M-bf16
收藏数据集卡片:DFNDR-12M-BFloat16
数据集描述
DFNDR-12M-BFloat16 是一个图像-文本数据集,基于多模态数据集强化策略构建。该数据集包含 DFNDR-12M 的合成字幕、嵌入向量和元数据。元数据使用预训练的图像-文本模型在 DFN-12M(DFN-2B 的一个均匀采样子集,包含 1280 万样本)上生成。这是一个 BFloat16 版本的数据集,嵌入以压缩的 .pth.gz 格式存储,采用 BFloat16 精度。
- 组织者: 原始数据由 DataComp 提供,元数据由 Apple 生成。
- 许可证: 元数据采用 Apple 提供的许可协议;原始图像 URL-文本样本由 DataComp 以 Creative Common CC-BY-4.0 许可证发布;个体图像受其各自的版权保护。
- 仓库: ml-mobileclip GitHub
- 论文: MobileCLIP2 论文
数据集用途
使用 DFNDR 进行训练相比标准 CLIP 训练表现出显著的学习效率提升。在 DFNDR-12M 上训练相比 DataComp-1B 12M 效率最高提升 5 倍,相比 DFN-12M 提升 3.3 倍,相比 DataCompDR-12M 提升 1.3 倍。
数据集结构
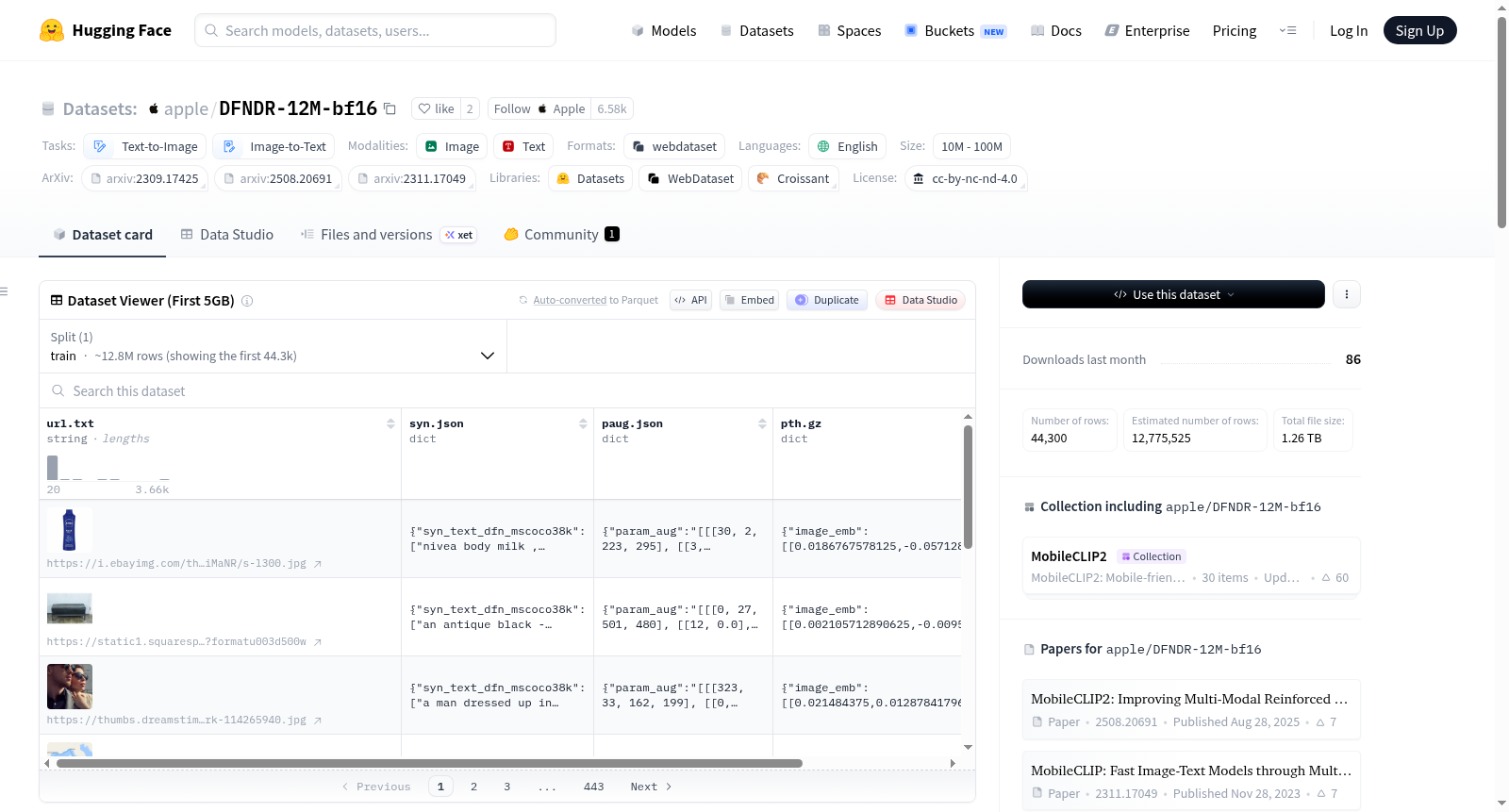
数据集包含以下文件格式和字段(以唯一标识符 <uid> 组织):
<uid>.url.txt:图像 URL(字符串)<uid>.syn.json:syn_text_dfn_mscoco38k:合成字幕列表(字符串列表)
<uid>.paug.json:param_aug:数据增强参数列表(整数或浮点数嵌套列表)
<uid>.pth.gz:image_emb:多次图像增强对应的图像嵌入向量列表(BFloat16 嵌套列表)
<uid>.pth.gz(续):text_emb:真实/合成字幕对应的文本嵌入向量列表(BFloat16 嵌套列表)syn_text_dfn_mscoco38k_emb:合成字幕对应的嵌入向量列表(BFloat16 嵌套列表)
数据集详情
- 语言: 英语
- 任务类别: 文本到图像、图像到文本
- 数据集大小: 基于 DFN-12M,包含约 1280 万样本
- 嵌入维度: 1536 维,由两个 768 维向量拼接而成
- 样本构成: 每个样本包含一个随机增强图像、一个真实字幕和一个随机选择的合成字幕
- 增强策略: 对 DFNDR-12M 应用 30 种强随机图像增强
- 教师模型: 使用两个更强的 DFN 教师模型(
DFN2B-CLIP-ViT-L-14和DFN2B-CLIP-ViT-L-14-39B)及改进的合成字幕生成模型MobileCLIP2-CoCa-ViT-L-14 - 浮点32版本: 可在 apple/DFNDR-12M 获取
引用
MobileCLIP2: Improving Multi-Modal Reinforced Training (TMLR 2025 特色认证)
bibtex @article{faghri2025mobileclip2, title={Mobile{CLIP}2: Improving Multi-Modal Reinforced Training}, author={Fartash Faghri and Pavan Kumar Anasosalu Vasu and Cem Koc and Vaishaal Shankar and Alexander T Toshev and Oncel Tuzel and Hadi Pouransari}, journal={Transactions on Machine Learning Research}, issn={2835-8856}, year={2025}, url={https://openreview.net/forum?id=WeF9zolng8}, note={Featured Certification} }
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training (CVPR 2024)
bibtex @InProceedings{mobileclip2024, author = {Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel}, title = {MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2024}, }