lance-format/hotpotqa-distractor-lance
收藏Hugging Face2026-05-08 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/lance-format/hotpotqa-distractor-lance
下载链接
链接失效反馈官方服务:
资源简介:
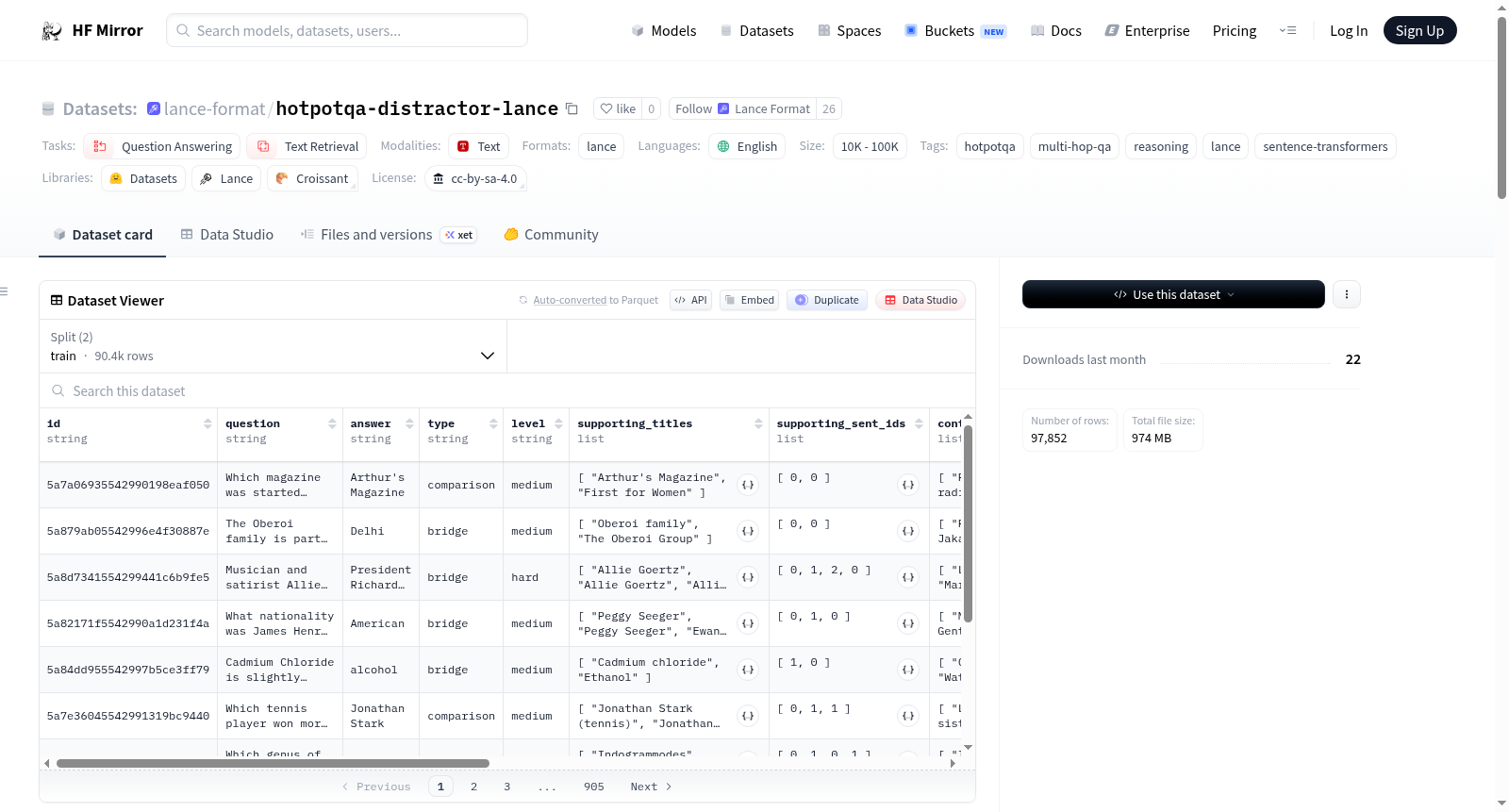
HotpotQA distractor (Lance Format)是基于HotpotQA数据集的一个版本,专门用于多跳阅读理解任务。每个问题的答案需要结合两个维基百科段落的事实。数据集采用了distractor配置,每个问题有10个候选段落(包括正确答案和8个干扰项)。数据集包含训练集和验证集,分别有90,447和7,405条记录。数据集模式包括问题ID、问题文本、答案、问题类型、难度级别、支持事实的标题和句子ID、所有段落标题和句子、扁平化的段落文本、支持事实的数量以及问题的嵌入向量。此外,数据集还提供了预构建的索引,支持快速检索和语义搜索。
HotpotQA distractor (Lance Format) is a variant of the HotpotQA dataset specifically designed for multi-hop reading comprehension tasks. Answering each question requires synthesizing facts from two Wikipedia paragraphs. The dataset employs the distractor setting, where each question is accompanied by 10 candidate paragraphs (one correct answer paragraph and eight distractors). It comprises training and validation subsets, with 90,447 and 7,405 entries respectively. The dataset schema includes question ID, question text, answer, question type, difficulty level, titles and sentence IDs of supporting facts, all paragraph titles and sentences, flattened paragraph text, count of supporting facts, and question embedding vectors. Furthermore, the dataset provides pre-built indexes to enable fast retrieval and semantic search.
提供机构:
lance-format
搜集汇总
数据集介绍
构建方式
本数据集源自HotpotQA的多跳阅读理解任务,聚焦于需要跨两个维基百科段落融合事实方能作答的复杂问题。基于其distractor配置,为每个问题配备十个候选段落,涵盖一个金标准段落与八个干扰项,并通过Lance格式高效存储与检索。数据划分包括训练集90,447条与验证集7,405条,字段设计精细,涵盖问题文本、答案、类型与难度等级,同时提供支持性标题与句子索引等关键信息。
特点
数据集具备显著的多跳推理特性,问题类型分为桥接型与比较型,难度梯度涵盖简单、中等与困难。每一问题的上下文均包含十个段落的句子级结构,干扰项丰富,促进鲁棒推理。预计算的问题嵌入采用sentence-transformers的all-MiniLM-L6-v2模型生成,维度384且经过余弦归一化,便于语义检索。此外,内置多种索引结构,如IVF_PQ向量索引、全文检索索引及位图索引,大幅提升查询效率。
使用方法
使用本数据集可通过Lance库轻松加载,支持直接读取HuggingFace上的Lance文件。适用于多跳语义搜索,利用预嵌入的问题向量与向量索引进行余弦相似度近邻查询,快速定位相似问题。亦可基于列过滤,如按类型与难度筛选特定子集,实现精细化的数据分析与模型评估。典型应用包括训练与评测多跳问答模型、探索性数据分析及搭建可解释的推理系统。
背景与挑战
背景概述
HotpotQA是一个由卡内基梅隆大学、斯坦福大学与蒙特利尔大学等机构的研究者于2018年提出的多跳问答数据集,旨在推动机器对复杂推理问题的理解能力。该数据集要求模型从两篇维基百科段落中提取并融合分散的事实信息,以回答需要跨段落推理的问题。与传统的单跳阅读理解不同,HotpotQA专注于评估模型在信息聚合与逻辑链条构建上的表现,其‘distractor’配置为每个问题提供10个候选段落(含正确答案段落与干扰项),进一步提升了任务的真实性与难度。该数据集的问世不仅催生了大量关于多跳推理的算法研究,也成为了评估语言模型推理与归因能力的重要基准。
当前挑战
HotpotQA所解决的领域挑战在于,传统问答系统通常缺乏对分散信息进行跨段落整合与逻辑链推理的能力,而现实世界中复杂问题往往需要多步骤的信息溯源与关联。构建过程中面临的挑战包括:如何设计兼具多样性与可解释性的高质量问题,确保每个问题都具有明确的多跳推理路径;如何从海量维基百科数据中精准标注支撑事实并筛选合理的干扰段落,以模拟真实检索环境中的噪声;此外,还需兼顾问题的难度分层与类型(如桥接型与比较型),以全面覆盖不同的推理模式。这些挑战使得HotpotQA成为评估模型综合推理、信息检索与可解释性的高难度测试集。
常用场景
经典使用场景
在自然语言处理与机器阅读理解交融的前沿领域,HotpotQA Distractor数据集扮演着评估模型多步推理能力的基准角色。其经典使用场景聚焦于多跳阅读理解任务,要求模型面对给定的问题,从提供的十个候选段落中精准定位并整合两个维基百科段落的知识片段,以形成最终答案。该数据集特别设计了干扰项(distractor)配置,即在每个问题中混入非相关的段落作为噪声,使得模型需具备辨别相关信息与避免误导的能力。这种设定模拟了真实世界中信息碎片化且冗余的特性,迫使模型超越简单的单段检索,发展出类似人类认知中联结多个知识点的复合推理链路。例如,模型需解答“哪位演员同时出演了《盗梦空间》和《敦刻尔克》?”这类问题,其答案必须跨越两部作品的信息才能正确获得。
衍生相关工作
该数据集自发布以来,催生了众多具有影响力的衍生研究工作,成为多跳推理领域的基石性资源。Yang等人(2018)在提出HotpotQA时同步发布了该数据集,并开发了基线模型以验证其挑战性。后续研究中,经典的“推理跨越文档的图神经网络”(Graph Neural Networks over Document Sets)方法应运而生,利用段落间的实体链接构建图结构,在HotpotQA上实现了显著的性能提升。另一重要工作是“融合检索与推理的联合学习”(Joint Retrieval and Reasoning)框架,通过端到端训练将初步段落筛选与精细推理步骤无缝衔接。此外,预训练语言模型如DeBERTa和Longformer均在其多跳推理论文中将HotpotQA视为关键评估基准,推动了长文本建模技术的发展。近期,基于检索增强生成(RAG)范式的模型,如REALM和FiD,也常在此数据集上衡量其跨段落知识整合的有效性。
数据集最近研究
最新研究方向
HotpotQA作为多跳推理问答的经典基准,其distractor配置在当前研究中被广泛应用于评估模型在复杂语义理解与段落间事实聚合方面的能力。该Lance格式版本整合了预计算的句子嵌入与多种索引结构(IVF_PQ、FTS等),极大提升了大规模语义检索与过滤效率,契合了近年来多跳QA研究向高效、可扩展方向演进的前沿趋势。随着大规模语言模型对长程依赖与多文档推理能力的持续突破,该数据集在验证模型拟人化推理、支持事实溯源以及幻觉抑制等热点议题中扮演着关键角色,成为连接传统检索式问答与新兴生成式对话系统之间不可或缺的评估桥梁。
以上内容由遇见数据集搜集并总结生成


