LibriBrain
收藏arXiv2025-06-12 更新2025-06-14 收录
下载链接:
https://huggingface.co/datasets/pnpl/LibriBrain
下载链接
链接失效反馈官方服务:
资源简介:
LibriBrain数据集是一个非侵入性的MEG数据集,由一位健康参与者聆听超过50小时的音频书籍所采集。该数据集包含超过50小时的MEG记录,通过306个传感器覆盖整个头部/大脑。数据集与LibriSpeech语料库中的单词和音素级别对齐,便于自动语音识别(ASR)。数据集被分成训练、验证和测试集,并包含额外的比赛保留集用于排行榜更新和最终排名。LibriBrain数据集的发布旨在推动非侵入性脑机接口的进步,特别是在语音解码方面。
The LibriBrain dataset is a non-invasive magnetoencephalography (MEG) dataset collected from a healthy participant while they listened to over 50 hours of audiobooks. It contains more than 50 hours of MEG recordings that cover the entire head and brain via 306 sensors. The dataset is aligned with word and phoneme-level annotations from the LibriSpeech corpus, supporting tasks related to automatic speech recognition (ASR). It is split into training, validation, and test sets, and also includes an additional competition holdout set for leaderboard updates and final ranking. The release of the LibriBrain dataset aims to advance the development of non-invasive brain-computer interfaces (BCIs), particularly in the field of speech decoding.
提供机构:
PNPL
创建时间:
2025-06-12
搜集汇总
数据集介绍
构建方式
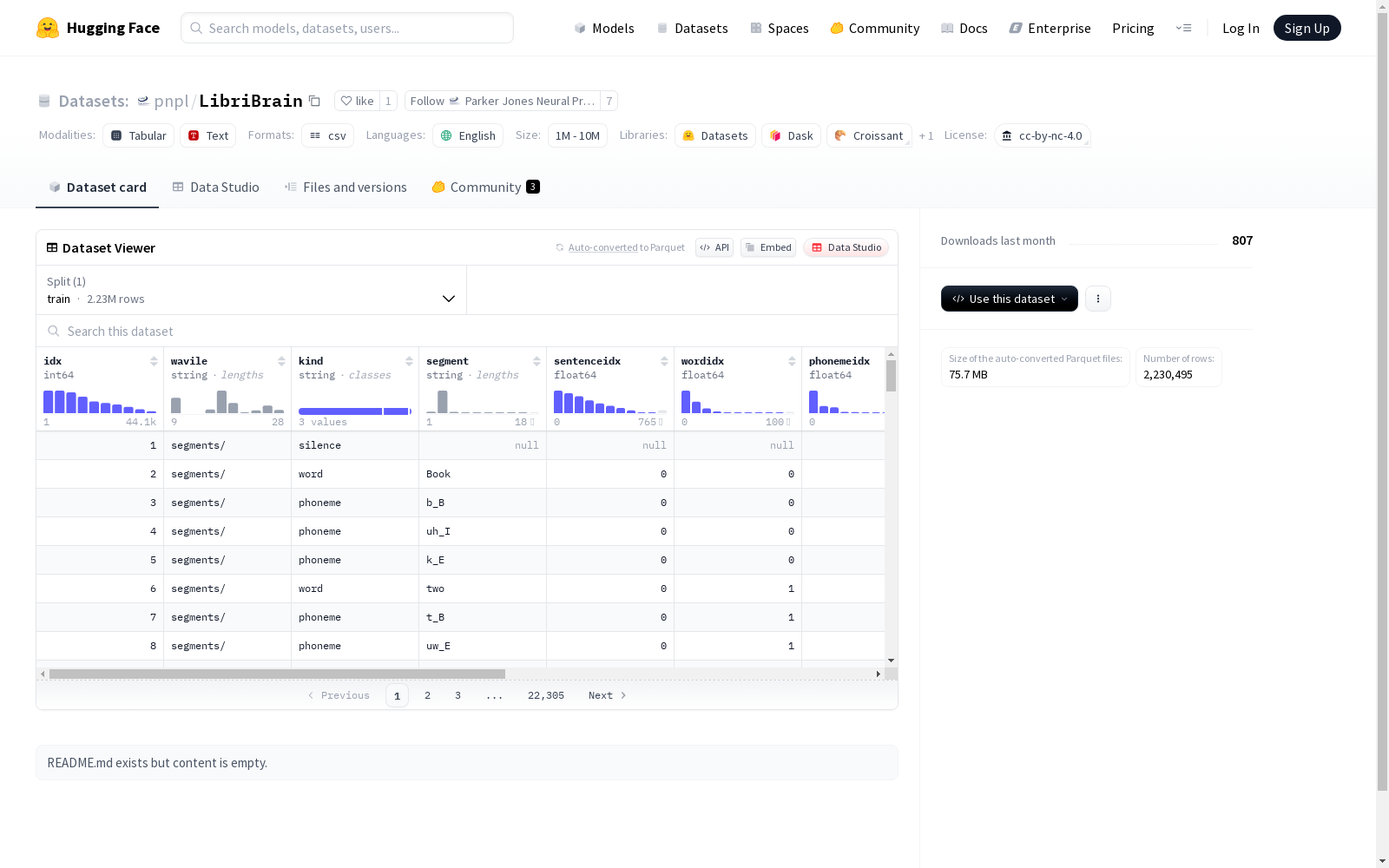
LibriBrain数据集作为当前最大的非侵入性脑磁图(MEG)语音解码数据集,其构建过程体现了多学科协作的精密设计。数据采集自单一健康受试者,通过306通道全头覆盖式MEG系统记录超过50小时的有声书听觉刺激神经响应,采样频率为250Hz。原始神经信号经过线噪消除和漂移校正等最小化预处理,并与LibriSpeech语料库严格对齐的单词及音素级标注相结合。数据集采用分层抽样策略划分为训练集(51.57小时)、验证集(0.36小时)和测试集(0.38小时),并额外设置竞赛专用保留集以确保评估公正性。这种深度纵向数据采集模式(较既往最大数据集扩容5倍)为探索个体神经表征稳定性提供了独特条件。
使用方法
研究者可通过标准化Python库(pnpl)实现便捷的数据访问与深度学习框架集成,安装仅需执行`pip install pnpl`指令。数据加载采用PyTorch原生DataLoader接口,支持自动下载与内存映射读取,示例代码`LibriBrainSpeech(data_path="/data")`即可完成数据部署。针对竞赛设置的两个核心任务(语音检测与音素分类),官方提供预训练基准模型(F1-macro分别达68.04%和60.39%)及Jupyter Notebook教程,支持在Google Colab免费GPU环境快速验证。参赛者需通过生成TSV预测文件提交至EvalAI平台,系统将基于F1-macro指标(兼顾精确率与召回率的调和平均数)自动更新排行榜。数据集特别设计标准赛道(仅限LibriBrain数据)和扩展赛道(允许使用外部数据),既鼓励算法创新也促进计算资源投入。
背景与挑战
背景概述
LibriBrain数据集由牛津大学PNPL实验室于2025年发布,是目前规模最大的被试内脑磁图(MEG)语音解码数据集,包含50小时高精度神经影像数据。该数据集源自LibriVox公开有声书,通过306通道MEG系统采集,旨在推动非侵入式脑机接口在语音重建领域的发展,尤其针对瘫痪患者的语言功能恢复。作为2025年PNPL竞赛的核心数据,其5倍于同类数据的规模特性为深度学习模型提供了关键训练资源,标志着神经解码领域向'ImageNet时刻'迈进的重要一步。
当前挑战
LibriBrain面临的核心挑战体现在两个维度:在科学层面,需解决MEG信号信噪比低、时空特征解耦困难等问题,当前非侵入式语音解码的词错误率仍接近100%;在工程层面,数据采集涉及毫秒级神经活动同步、39类音素标注对齐等复杂工序,50GB原始数据的清洗与标准化需克服磁干扰伪影、个体生理差异等干扰因素。此外,竞赛设计的语音检测与音素分类任务需平衡数据效率(152万音素样本)与模型泛化性,这对算法处理长时序依赖和跨被试迁移能力提出严峻考验。
常用场景
经典使用场景
LibriBrain数据集作为当前最大的单被试非侵入性脑磁图(MEG)语音解码数据集,其经典应用场景聚焦于探索大脑如何表征和处理语音信息。通过记录被试聆听超过50小时的有声书时的神经活动,该数据集为研究语音检测和音素分类两大基础任务提供了前所未有的高时空分辨率数据支持。其独特的深数据范式(deep data paradigm)——即对同一被试进行长时间重复扫描——显著提升了神经解码模型的性能基准,为理解语音处理的神经机制建立了新的实验标准。
解决学术问题
该数据集有效解决了非侵入式神经解码领域的关键学术问题:在避免外科手术风险的前提下,如何通过大规模高质量数据克服MEG信号信噪比低的固有局限。其提供的超长时程、精细标注的MEG-语音对齐数据,使得研究者能够系统探究音素层级的神经表征模式,并验证深度学习模型在跨模态解码中的有效性。通过标准化任务定义与评估指标,LibriBrain为比较不同解码算法的性能提供了统一基准,推动了脑机接口领域从侵入式向非侵入式技术路径的范式转变。
实际应用
在实际应用层面,LibriBrain的成果将直接助力于开发新型辅助沟通技术。对于因肌萎缩侧索硬化症等疾病导致语言功能障碍的患者,基于该数据集训练的MEG解码模型可构建安全的非侵入式语音神经假体。其音素分类能力可整合至脑控打字系统,而语音检测算法能实现思维言语的实时激活识别。此外,数据集揭示的神经编码规律也为开发更自然的听觉脑机交互系统提供了理论基础。
数据集最近研究
最新研究方向
近年来,LibriBrain数据集在非侵入式神经解码领域引起了广泛关注,特别是在语音检测和音素分类任务中展现了巨大的潜力。该数据集作为目前最大的受试者内MEG数据集,为研究人员提供了前所未有的数据规模和质量,极大地推动了脑机接口技术的发展。前沿研究方向主要集中在利用深度学习模型提升信号解码的准确性和效率,尤其是在低信噪比环境下优化模型性能。此外,结合自监督学习和领域适应技术,研究人员正在探索如何跨数据集整合信息以进一步提升解码效果。这一领域的突破不仅有望为言语障碍患者提供革命性的沟通工具,还可能为神经科学和人工智能的交叉研究开辟新的路径。
相关研究论文
- 1The 2025 PNPL Competition: Speech Detection and Phoneme Classification in the LibriBrain DatasetPNPL · 2025年
以上内容由遇见数据集搜集并总结生成


