GLAMI-1M
收藏Hugging Face2025-04-05 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/pySilver/GLAMI-1M
下载链接
链接失效反馈官方服务:
资源简介:
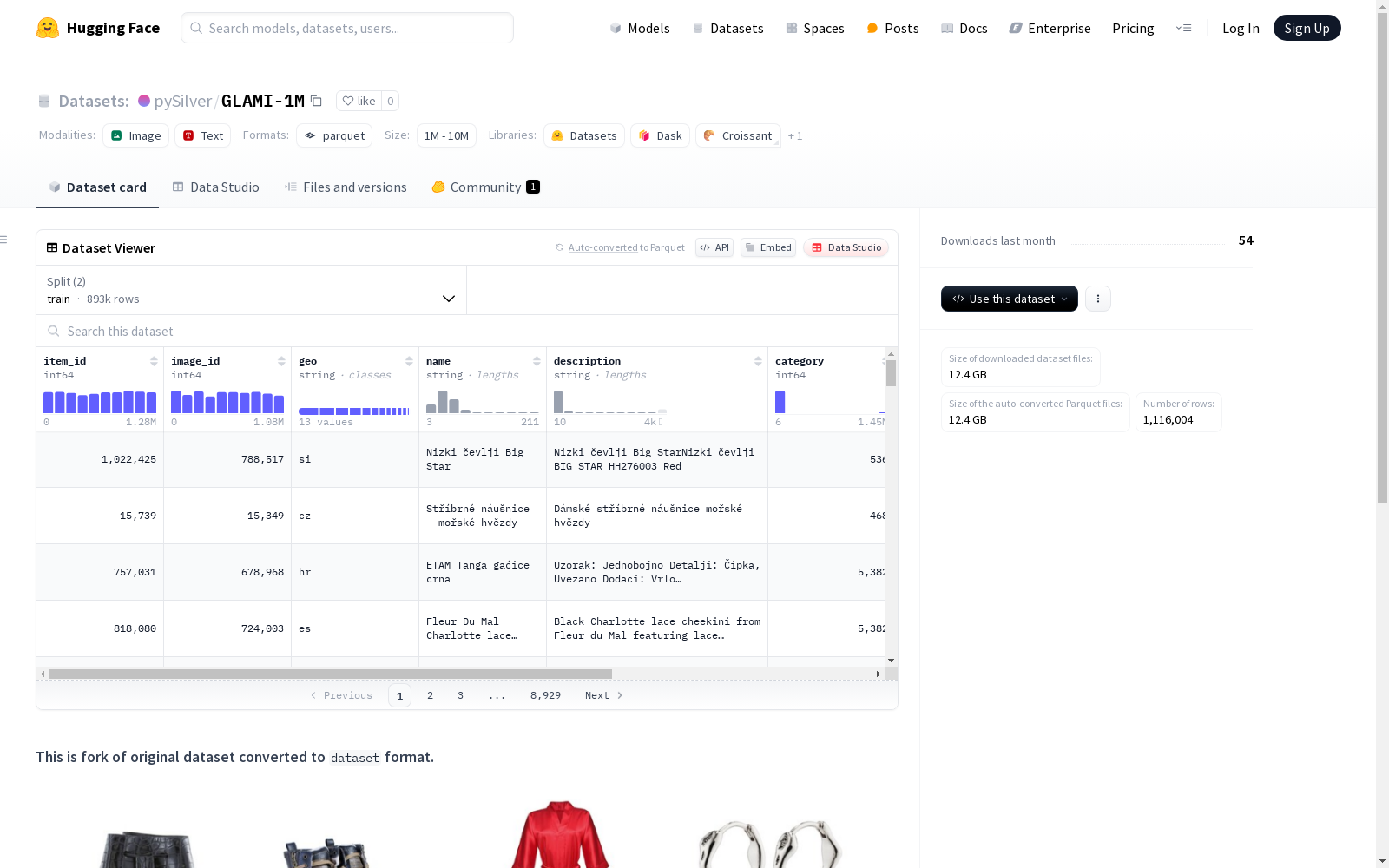
GLAMI-1M数据集包含110万时尚商品,96.8万唯一图片和100万唯一文本,涵盖13种语言,主要包括欧洲语言。该数据集分为191个细粒度类别,例如包含15种不同的鞋类。每个样本都有一张图片、国家代码、对应语言的产品名称、描述、目标类别和标签来源,这些标签来源可能是人工的或者基于规则的,但大多数是基于人工标注的。
The GLAMI-1M dataset contains 1.1 million fashion products, 968,000 unique images, and 1 million unique texts, covering 13 languages, primarily European languages. It is divided into 191 fine-grained categories, including 15 different footwear categories as an example. Each sample includes an image, a country code, product names and descriptions in the corresponding language, the target category, and the label source. The label sources may be either manual or rule-based, but most are manually annotated.
创建时间:
2025-04-04
原始信息汇总
GLAMI-1M 数据集概述
数据集基本信息
- 数据量: 1.1百万个时尚商品
- 唯一图像数量: 96.8万张
- 唯一文本数量: 100万条
- 语言种类: 13种(主要为欧洲语言)
- 细粒度类别: 191个(例如包含15种鞋类)
数据集特征
- item_id: 商品ID(int64)
- image_id: 图像ID(int64)
- geo: 国家代码(string)
- name: 商品名称(对应语言)(string)
- description: 商品描述(string)
- category: 商品类别(int64)
- category_name: 类别名称(string)
- label_source: 标签来源(string)
- image: 商品图像(image)
数据划分
- 训练集(train):
- 样本数量: 892,803
- 数据大小: 10,129,258,280.46字节
- 测试集(test):
- 样本数量: 223,201
- 数据大小: 2,579,288,717.72字节
下载与存储信息
- 下载大小: 12,362,292,055字节
- 数据集总大小: 12,708,546,998.18字节
其他信息
- 标签来源: 专业策展人提供的高质量标注,包含人工标注和基于规则的标注,多数为人工标注。
- 应用场景: 面向生产行业的复杂问题解决。
- 更多详情: GLAMI-1M GitHub主页
搜集汇总
数据集介绍
构建方式
在时尚电商领域,多语言商品数据的标准化处理面临重大挑战。GLAMI-1M数据集通过专业策展团队精心构建,采集了欧洲市场13种语言的110万件时尚单品数据,涵盖191个精细商品类别。数据集采用人工标注与规则标注相结合的方式,其中主要标注工作由专业标注人员完成,确保每个样本包含商品图像、地理编码、多语言名称与描述、细粒度分类标签及标注来源等结构化信息。
特点
该数据集以其多语言覆盖和细粒度分类体系著称,包含96.8万张独特商品图像和100万条独特文本描述,覆盖15种鞋类等191个精细商品子类。数据样本具有标注质量高的显著优势,专业策展人员提供的标注信息为时尚行业的实际生产问题提供了可靠基准。多模态数据结构将视觉信息与多语言文本有机整合,为跨语言商品理解任务提供了理想实验平台。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,其标准化的dataset格式支持高效访问训练集(892,803样本)和测试集(223,201样本)。典型应用场景包括多语言文本分类、跨模态检索及细粒度图像识别等任务。数据集中提供的标注来源字段允许用户根据需求筛选人工标注样本,确保模型训练数据的可靠性。对于时尚电商领域的算法开发,建议结合图像与多语言文本特征进行联合建模。
背景与挑战
背景概述
GLAMI-1M数据集作为时尚领域的大规模多语言数据集,由专业机构GLAMI于近年推出,旨在为时尚行业的计算机视觉与自然语言处理研究提供高质量标注资源。该数据集收录了来自欧洲主要语区的110万件时尚单品,涵盖968,000张独特图像和100万条文本描述,涉及13种语言和191个细粒度商品类别。其核心价值在于通过专业策展人员标注的高质量数据,解决了时尚领域多模态学习中的数据稀缺问题,为商品分类、跨语言检索等任务建立了新的基准。
当前挑战
构建GLAMI-1M面临双重挑战:在领域问题层面,时尚商品的细粒度分类需要处理高度相似子类间的细微差异(如15种鞋类的区分),且多语言描述存在文化特异性表达;在技术实现层面,协调13种语言的标注一致性、处理非标准化的商品描述文本,以及保证百万级数据中人工标注的质量控制,均为数据集构建的关键难点。这些挑战使得该数据集成为检验多模态模型跨语言理解和细粒度识别能力的试金石。
常用场景
经典使用场景
GLAMI-1M数据集作为时尚领域的大规模多语言数据集,其经典使用场景主要集中在跨模态检索和细粒度分类任务。在跨模态检索中,研究者利用其丰富的图像-文本对数据,训练模型实现时尚商品图像与多语言描述的精准匹配。细粒度分类任务则得益于其191个精细标注的类别,为区分高度相似的时尚单品(如15种鞋类子类)提供了可靠基准。
解决学术问题
该数据集有效解决了时尚计算领域两个关键学术问题:多语言环境下商品表征学习的语义鸿沟问题,以及细粒度分类中类间差异微小导致的模型区分度不足问题。通过提供13种欧洲语言的标准化标注和人类专家审核的类别体系,为跨文化时尚推荐系统和视觉属性分析研究提供了高质量数据支撑,显著提升了相关领域模型的泛化能力。
衍生相关工作
基于GLAMI-1M衍生的经典工作包括跨模态预训练模型FashionBERT和多语言时尚检索系统StyleMatch。前者通过联合学习图像与多语言文本特征,在时尚领域实现了最先进的零样本检索性能;后者则创新性地利用地理标签信息,开发出适应区域偏好的个性化推荐框架,相关成果均发表于计算机视觉顶会。
以上内容由遇见数据集搜集并总结生成


