SAND-Math
收藏arXiv2025-07-28 更新2025-07-30 收录
下载链接:
https://huggingface.co/datasets/amd/SAND-MATH
下载链接
链接失效反馈官方服务:
资源简介:
SAND-Math数据集是一个通过利用大型语言模型(LLM)生成的新颖、困难且实用的数学问题和答案的数据集。该数据集由AMD公司的研究团队创建,旨在解决LLM在数学推理方面的训练数据稀缺问题。数据集通过一个自动化的流程生成,首先从零开始生成高质量的问题,然后通过一个名为Difficulty Hiking的步骤系统地提高问题的复杂性。该数据集包含8842个新颖的问题,每个问题都经过正确性、新颖性和难度的严格筛选。数据集的创建过程包括问题生成、答案生成、正确性过滤、去重和去污染、难度过滤和评分、新颖性过滤以及难度提升等步骤。SAND-Math数据集适用于构建更强大、更高效的数学推理LLM,旨在解决数学问题解决和推理领域的问题。
The SAND-Math dataset is a novel, challenging and practical collection of mathematical problems and their corresponding answers generated using large language models (LLMs). Developed by a research team at AMD, this dataset was created to mitigate the scarcity of high-quality training data for LLMs in mathematical reasoning tasks. The dataset generation follows an automated workflow: initially, high-quality problems are generated from scratch, then their complexity is systematically elevated through a stepwise process named Difficulty Hiking. The dataset comprises 8,842 novel problems, each of which has undergone strict filtering across three criteria: correctness, novelty and difficulty level. The complete dataset creation pipeline includes multiple stages: problem generation, answer generation, correctness filtering, deduplication and decontamination, difficulty filtering and scoring, novelty filtering, and difficulty enhancement. The SAND-Math dataset is designed for building more powerful and efficient mathematical reasoning LLMs, with the goal of addressing core challenges in the field of mathematical problem-solving and reasoning.
提供机构:
先进微设备公司(AMD)
创建时间:
2025-07-28
原始信息汇总
SAND-MATH 数据集概述
数据集基本信息
- 名称: SAND-MATH (Synthetic Augmented Novel and Difficult Mathematics)
- 语言: 英文 (en)
- 许可证: 其他 (other)
- 任务类别: 问答 (question-answering)、文本生成 (text-generation)
- 标签: 数学 (mathematics)、合成数据 (synthetic-data)、问答 (question-answering)、推理 (reasoning)、大语言模型 (llm)
数据集特点
- 新颖问题生成: 通过最小约束提示从零生成问题,利用SOTA大语言模型的潜在元认知能力。
- 系统性难度提升: 通过合成新约束、高级定理和跨领域概念增加问题复杂性。
- 严格质量控制: 多阶段过滤管道确保解决方案的正确性、内部多样性、去污和网络数据的新颖性。
- 最先进性能: 在AIME、AMC和MATH等具有挑战性的基准测试中取得顶级结果。
数据集结构
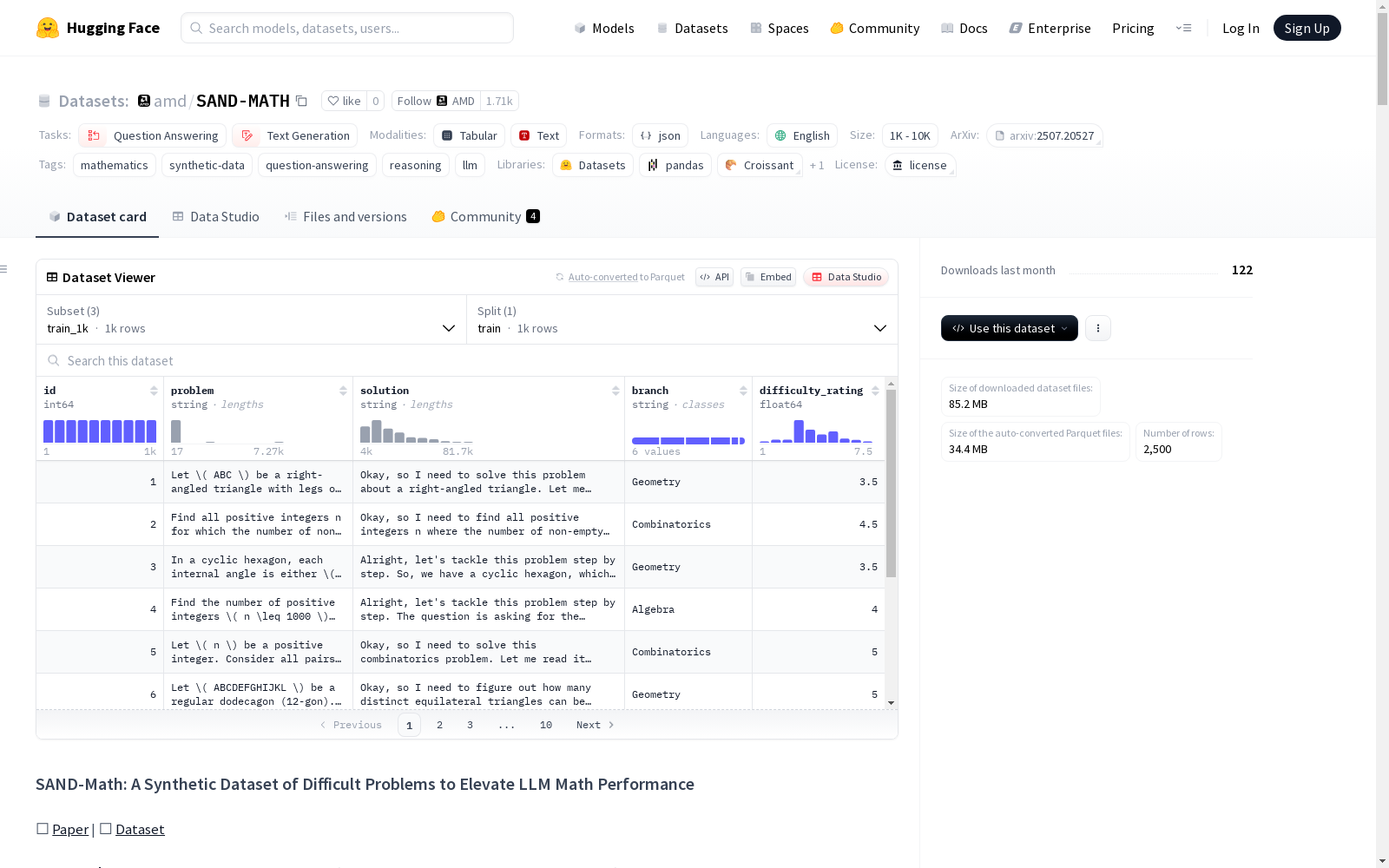
数据分割
- train_500: 500样本子集,用于独立微调比较。
- train_1k: 1000样本的基础SAND-Math数据。
- train_dh_1k: 1000样本的难度提升数据。
数据字段
id: 问题IDproblem: 数学问题文本solution: 详细的分步解决方案difficulty_rating: 1-10的难度评分branch: 主要数学分支version: 问题版本(stage1: 原始问题,stage2: 难度提升问题)
使用方法
python from datasets import load_dataset dataset = load_dataset("amd/SAND-MATH", name="train_1k")
训练细节
超参数
| 超参数 | 值 |
|---|---|
| 学习率 | 5.0e-6 |
| LR调度器类型 | cosine |
| 预热比例 | 0.0 |
| 训练周期数 | 10 |
| 梯度累积步数 | 1 |
| 截断长度 | 32,768 |
| Flash Attention实现 | fa2 |
| DeepSpeed策略 | ZeRO-3 |
评估结果
性能比较
| 训练数据配置 | 数据样本大小 | AIME25 | AIME24 | AMC | MATH-500 | 平均 |
|---|---|---|---|---|---|---|
| LIMO + SAND-Math | 817+500 | 48.89 | 57.92 | 92.50 | 94.00 | 73.32 |
难度提升效果
| 数据集 | 数据大小 | AIME25 | AIME24 | AMC24 | MATH500 | 平均 |
|---|---|---|---|---|---|---|
| LIMO + SAND-Math (DH) | 817 + 1500 | 49.23 | 60.55 | 93.17 | 94.60 | 74.39 |
许可证
- 类型: ResearchRAIL许可证
- 用途: 学术和研究目的
引用
bibtex @misc{manem2025sandmathusingllmsgenerate, title={SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers}, author={Chaitanya Manem and Pratik Prabhanjan Brahma and Prakamya Mishra and Zicheng Liu and Emad Barsoum}, year={2025}, eprint={2507.20527}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2507.20527}, }
搜集汇总
数据集介绍
构建方式
SAND-Math数据集通过多阶段合成管道构建,旨在生成高质量、高难度的数学问题及其解答。首先,利用大型语言模型(LLM)生成初始问题池,随后通过自一致性验证确保解答正确性。其次,采用去重和去污染过滤步骤保证问题的新颖性。最后,通过独特的难度提升模块(Difficulty Hiking)系统性地增加问题复杂度,该模块通过引入高级定理和跨领域数学概念重新构造问题。整个流程结合了严格的质量控制,包括正确性、新颖性和难度评估,最终生成的数据集在难度上超越了现有合成数据集,并与人工精选的真实问题相媲美。
特点
SAND-Math数据集的核心特点在于其高难度和高质量。数据集的问题平均难度评分显著高于其他合成数据集,且覆盖了广泛的数学分支,包括代数、数论、组合数学等。通过难度提升模块,问题复杂度得到系统性增强,使得数据集中的问题更具挑战性。此外,数据集具有极低的污染率(0.2%)和高自一致性(85%),确保了问题的独特性和正确性。这些特点使得SAND-Math成为训练和评估数学推理能力的理想资源。
使用方法
SAND-Math数据集可用于增强大型语言模型的数学推理能力。用户可以通过微调现有模型(如Qwen2.5-32B-Instruct)在数据集上进行训练,以提升模型在复杂数学问题上的表现。此外,数据集还可作为补充数据,与其他数学数据集(如LIMO)结合使用,以进一步提升模型性能。评估时,建议使用AIME、AMC等数学竞赛基准测试模型表现。数据集的全流程生成代码和训练配置已公开,便于复现和扩展。
背景与挑战
背景概述
SAND-Math是由AMD研究院的Chaitanya Manem等研究人员于2025年提出的创新型数学问题生成数据集,旨在解决大语言模型(LLMs)在复杂数学推理任务中高质量训练数据稀缺的核心瓶颈。该数据集通过独创的'难度爬升'(Difficulty Hiking)技术,利用LLMs的元认知能力从零生成具有奥赛级难度的数学问题,其生成的问题平均难度评分达5.98(10分制),显著超越MetaMathQA等现有合成数据集。作为首个不依赖种子数据的自主生成框架,SAND-Math在AIME25基准测试中使基线模型性能提升17.85个绝对百分点,为量化金融、科学计算等需高阶数学推理的领域提供了可扩展的数据解决方案。
当前挑战
SAND-Math面临双重挑战:在领域层面,现有数学数据集(如MATH、GSM8K)受限于人类编撰的复杂度天花板,难以满足LLMs对超线性增长的高难度问题的需求;而合成方法(如WizardMath)通常仅能复现种子数据的难度特征。在构建层面,需克服问题新颖性验证(通过语义哈希实现0.2%的污染率)、解的正确性检验(采用三重自洽验证机制)以及难度动态提升(通过定理-概念交叉注入实现47.2%→76.8%的高难度问题转化率)等关键技术难题,其多级过滤管道最终仅保留初始生成问题的35%,体现了质量与规模间的显著权衡。
常用场景
经典使用场景
SAND-Math数据集专为提升大型语言模型(LLM)的数学推理能力而设计,其核心应用场景包括生成高难度数学问题以增强模型训练。通过独特的难度提升(Difficulty Hiking)流程,该数据集能够系统性地构造奥林匹克竞赛级别的题目,例如数论、代数与组合数学中的复杂问题。其生成的问题具有严格的正确性验证机制,确保题目与解法的逻辑严密性,适用于需要高阶数学推理的模型微调任务。
衍生相关工作
SAND-Math的生成方法启发了多项后续研究,例如结合元认知提示的MetaMathQA和采用强化学习的WizardMath。其难度提升模块被OpenMathInstruct2等工作扩展用于跨学科问题生成。数据集本身也被整合进HuggingFace生态,成为AMD开源的LLM数学推理工具链核心组件,支持Qwen2.5等模型的微调。相关技术还推动了LIMO框架在数据效率优化方面的改进。
数据集最近研究
最新研究方向
随着大型语言模型(LLM)在数学推理领域的快速发展,高质量数学问题数据集的稀缺成为制约模型性能提升的关键瓶颈。SAND-Math数据集通过创新的合成数据生成管道,首次实现了从零生成高难度数学问题并系统提升其复杂度的技术突破。该数据集采用独特的'难度提升'(Difficulty Hiking)机制,通过整合高级定理和跨领域数学概念,将平均问题难度从5.02提升至5.98(10分制),在AIME25基准测试中使模型性能绝对提升17.85分。当前研究聚焦于三个前沿方向:一是探索LLM元认知能力在数学问题生成中的深层应用机制;二是开发可扩展的自动难度评估体系,实现问题复杂度的量化控制;三是研究合成数据与真实竞赛题目的协同效应,如在LIMo基线模型上增强SAND-Math数据可使平均得分从71.50提升至74.39。该数据集为构建高效数学推理模型提供了可扩展的新范式,其技术路径已被验证可推广至数论、代数、组合数学等多个数学分支。
相关研究论文
- 1SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers先进微设备公司(AMD) · 2025年
以上内容由遇见数据集搜集并总结生成


