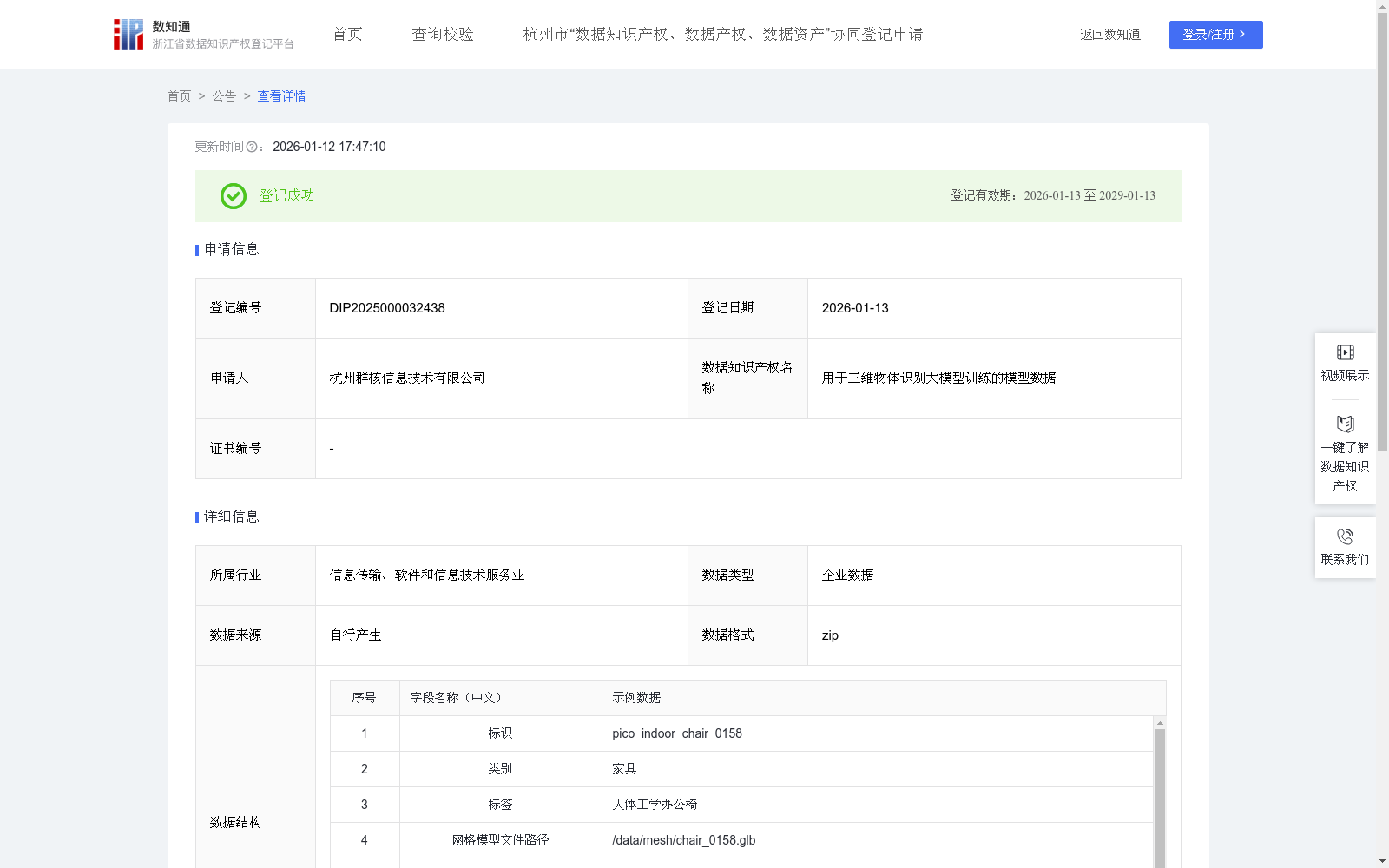
用于三维物体识别大模型训练的模型数据
收藏浙江省数据知识产权登记平台2026-01-12 更新2026-01-13 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8423276
下载链接
链接失效反馈官方服务:
资源简介:
本数据集旨在为三维物体识别大模型提供大规模、高质量、多类别的预训练数据,以构建强大的视觉感知基础能力。可专项用于其VR/AR产品。数据集精心选取了与个人生活及消费电子场景高度相关的四大核心类别:人物、汽车、宠物、日用品。模型不局限于单一背景,而是覆盖了室内(如客厅、卧室)、室外(如街道、停车场)、及纯色背景等多种情境,以确保模型的泛化能力。数据集特别注重模型的细节质量、几何准确性及纹理真实感,以满足客户在VR/AR应用中对高保真视觉和精准交互的严格要求。本算法旨在处理三维模型,通过一系列步骤实现模型的分割、实例重组及格式转换,以生成新的实例模型,用于场景渲染和机器人训练等应用。
1.模型分割:本步骤接收任意初始三维模型作为输入,三维模型包括位置、尺寸、材质、顶点信息、法相信息、面片信息字段,运用拓扑连通性聚类算法将该组合模型拆分为多个面片组(face group),获取模型类型字段。此步骤有效提取模型的结构特征,有助于后续的实例重组。
2.模型实例重组:在此步骤中,对三维模型的位置、尺寸、材质、顶点信息、法相信息、面片信息字段进行分割,再利用Qwen-VL-Max和GroundingDino算法对分割后的部件进行组合,形成独立的模型实例,并获取其中的标签字段。标签字段能够使每个模型实例能够基于原模型的结构和信息进行识别和应用。
3.模型格式转换:本步骤将拆分获得的实例模型及其对应的材质信息转换为OpenUSD格式,并获取其中的碰撞体设置信息字段和动画约束信息字段,以使模型能够在场景中动起来。
通过以上步骤,将原本数据库中的模型进行重组,生成新的实例模型,并被组装成一个完整的场景,以满足场景渲染、机器人训练等多个应用需求。
This dataset aims to provide large-scale, high-quality, multi-category pre-training data for 3D object recognition large models, to build robust foundational visual perception capabilities, and can be specially applied to VR/AR products. The dataset carefully selects four core categories highly relevant to everyday personal life and consumer electronics scenarios: humans, automobiles, pets, and daily necessities. The 3D models in the dataset are not limited to a single background, but cover various scenarios including indoor spaces (e.g., living rooms, bedrooms), outdoor spaces (e.g., streets, parking lots), and solid-color backgrounds, to ensure the generalization capability of the trained model. The dataset places special emphasis on the detail quality, geometric accuracy, and texture realism of the 3D models, to meet the strict requirements of customers for high-fidelity vision and precise interaction in VR/AR applications.
The supporting processing algorithm is designed to handle 3D models, and generates new instance models through a series of steps including model segmentation, instance recombination, and format conversion, which can be used for applications such as scene rendering and robot training.
1. Model Segmentation: This step takes any initial 3D model as input. The 3D model includes fields such as position, size, material, vertex information, normal information, and face information. A topological connectivity clustering algorithm is used to split the combined model into multiple face groups, and the model type field is obtained. This step effectively extracts the structural features of the model, which facilitates subsequent instance recombination.
2. Model Instance Recombination: For this step, the fields including position, size, material, vertex information, normal information, and face information of the 3D model are first segmented, then the Qwen-VL-Max and GroundingDino algorithms are used to combine the segmented components into independent model instances, and the label field is obtained. The label field enables each model instance to be identified and applied based on the structure and information of the original model.
3. Model Format Conversion: This step converts the split instance models and their corresponding material information into the OpenUSD format, and obtains the collision body setting information field and animation constraint information field therein, so that the models can be animated in the scene.
Through the above steps, the models originally stored in the database are recombined to generate new instance models, which are then assembled into a complete scene to meet multiple application requirements such as scene rendering and robot training.
提供机构:
杭州群核信息技术有限公司
创建时间:
2025-11-13
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个专门用于三维物体识别大模型训练的高质量预训练数据集合,由杭州群核信息技术有限公司提供。它包含465.74条数据,覆盖人物、汽车、宠物和日用品四大核心类别,数据结构详细,包括网格模型、纹理贴图、坐标、部件分割和语义标签等字段,旨在提升模型的视觉感知和泛化能力。数据集特别注重几何准确性、纹理真实感和多场景覆盖(如室内、室外和纯色背景),适用于VR/AR产品开发,支持场景渲染和机器人训练等应用。
以上内容由遇见数据集搜集并总结生成


