open-index/open-wikipedia-markdown
收藏Hugging Face2026-05-09 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/open-index/open-wikipedia-markdown
下载链接
链接失效反馈官方服务:
资源简介:
这是一个多语言的维基百科数据集,采用Markdown格式,涵盖了大量语言和方言。数据集适用于多种自然语言处理任务,包括文本生成、特征提取、文本分类、问答、摘要和翻译。数据集遵循知识共享署名-相同方式共享4.0许可协议(CC-BY-SA-4.0),属于开放数据,旨在促进知识的共享和传播。数据规模介于1000万到1亿条记录之间,按语言分类存储为parquet文件格式。
This is a multilingual Wikipedia dataset in Markdown format, covering a wide range of languages and dialects. The dataset is suitable for various natural language processing tasks, including text generation, feature extraction, text classification, question answering, summarization, and translation. It is licensed under the Creative Commons Attribution-ShareAlike 4.0 license (CC-BY-SA-4.0), intended as open data to promote the sharing and dissemination of knowledge. The dataset size ranges between 10 million and 100 million records, organized by language and stored in parquet file format.
提供机构:
open-index
搜集汇总
数据集介绍
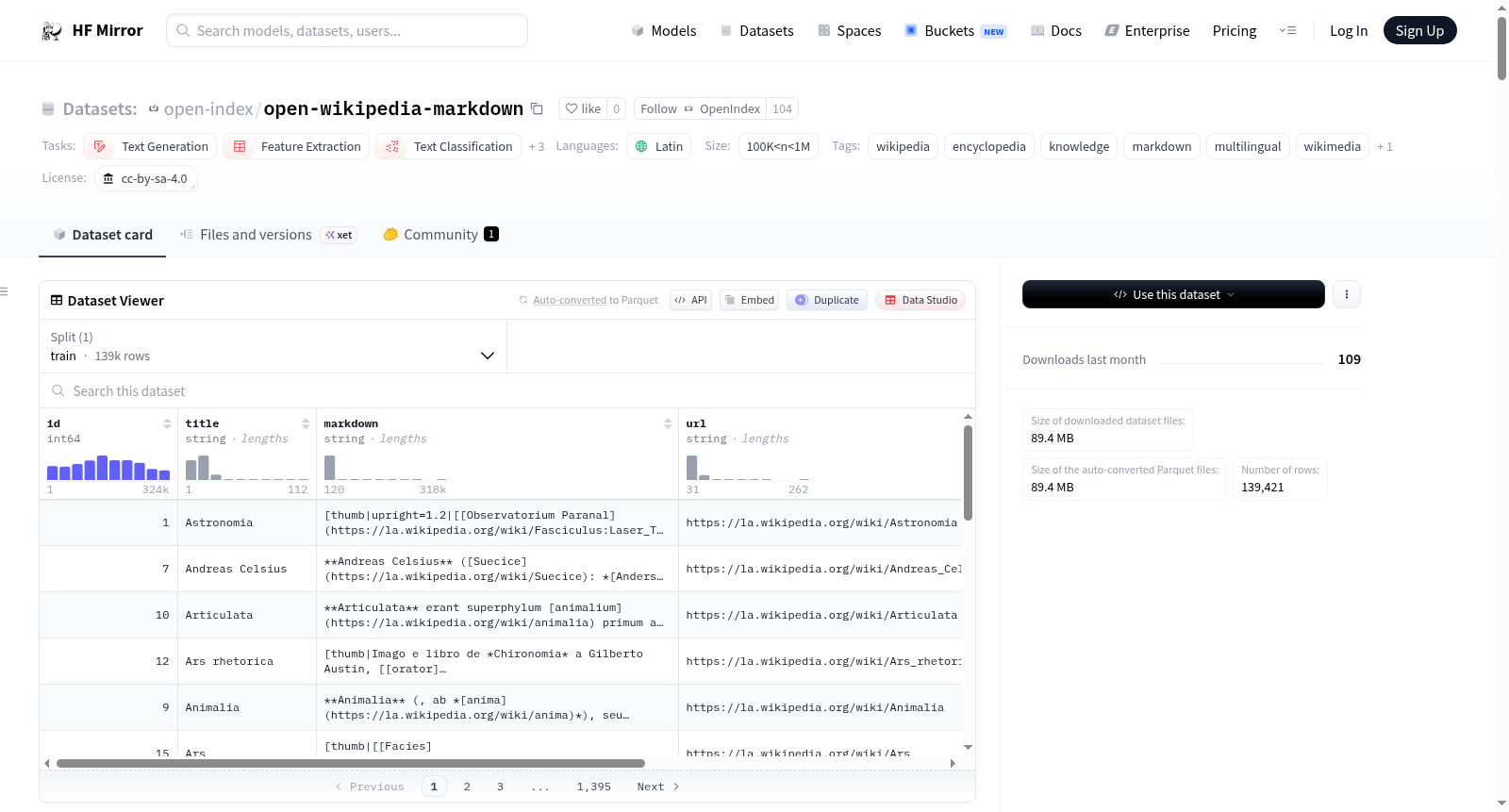
构建方式
在知识图谱构建与自然语言处理领域,大规模、结构化的文本语料库是模型训练与评估的基石。Open Wikipedia (Markdown) 数据集的构建遵循一套严谨的自动化流程,其核心是从维基媒体基金会提供的官方数据库转储中提取并转换内容。具体而言,该流程首先流式下载各语言版本的XML文章转储文件,随后通过流式XML解析器筛选出命名空间为0的正式文章,并舍弃重定向页、讨论页等非核心内容。每篇文章的原始Wiki标记文本会经过一系列基于正则表达式的转换,将标题、粗体、斜体、代码块及内部链接等元素映射为标准Markdown语法,同时彻底移除信息框、导航模板、参考文献、表格等仅适用于MediaWiki渲染引擎的复杂结构。最终,经过转换且长度超过100字节的文章被分批写入采用Zstandard压缩的Parquet文件,每个分片约包含50万条记录,并按语言目录进行组织。
特点
作为多语言百科全书知识的结构化表示,该数据集最显著的特征在于其内容的纯净性与格式的统一性。它并非简单地提供原始Wiki文本,而是通过精心设计的转换规则,将纷繁复杂的MediaWiki语法提炼为清晰、可读的Markdown文档,完整保留了文章的层级标题、强调样式和超链接结构。这种处理使得数据既适用于需要理解文档结构的语言模型预训练,也能为基于检索增强生成(RAG)的系统提供易于按语义分块的语料。此外,数据集采用高效的列式存储格式Parquet并辅以压缩,在保证数据可访问性的同时优化了存储与查询性能。其设计还体现了高度的可扩展性,支持以语言为单位进行增量更新与独立加载。
使用方法
为便利研究人员与开发者高效利用这一知识库,数据集提供了多种灵活的访问途径。用户可通过Hugging Face `datasets` 库直接加载特定语言的全部或流式数据,便于在Python生态中进行快速原型开发与实验。对于需要执行复杂查询或聚合分析的任务,推荐使用DuckDB,它能够直接远程读取Parquet文件,无需预先下载整个数据集,即可执行跨语言的文章统计、内容搜索与长度分布分析等操作。此外,利用`huggingface_hub`工具或命令行接口,用户可以仅下载感兴趣的语言分片到本地。数据集统一的Schema——包含文章ID、标题、Markdown内容、URL、语言代码、文本长度和时间戳——确保了不同使用方式下数据接口的一致性,为下游的文本生成、特征提取、分类、问答等多种NLP任务提供了坚实基础。
背景与挑战
背景概述
在数字知识库与自然语言处理领域,大规模、结构化的文本数据是驱动模型进步的核心燃料。Open Wikipedia (Markdown) 数据集由 Open Index 团队于2026年前后构建并持续更新,旨在将维基百科全语种的原始文章从复杂的 MediaWiki 标记语言,系统性地转换为清晰、可读的 Markdown 格式。该数据集聚焦于解决多语言知识文本的结构化表示问题,通过保留标题、强调、链接等语义结构,同时剔除模板、信息框等渲染噪声,为语言模型训练、检索增强生成及知识图谱构建提供了高质量、标准化的语料基础。其覆盖多种任务类别,并遵循开放许可,对推动多语言理解与生成研究具有显著影响力。
当前挑战
该数据集致力于解决多语言百科全书内容的结构化转换与知识表示挑战,其核心在于如何从异构且复杂的原始维基文本中,精准提取并保留人类可读的语义内容与文档逻辑结构,同时过滤非内容元素。在构建过程中,面临多重技术挑战:首先,基于正则表达式的转换方法难以完美处理深度嵌套的模板、解析函数或Lua模块输出等复杂结构,可能导致边缘案例的转换瑕疵;其次,为保持格式清洁而彻底剥离模板(如信息框、导航框),虽提升了可读性,却也损失了部分结构化数据,影响了内容的完整性。此外,处理数百种语言、海量文章所需的流式解析、并行计算与持续更新,对数据管道的鲁棒性与效率提出了极高要求。
常用场景
经典使用场景
在自然语言处理领域,大规模、高质量文本语料是模型训练与评估的基石。Open Wikipedia (Markdown) 数据集通过将维基百科文章转换为结构化的Markdown格式,为语言模型预训练提供了理想的语料来源。其保留了标题、加粗、斜体、代码块及内部链接等语义结构,使得模型能够学习文档的层次化组织与格式化信息,从而提升对复杂文本的理解与生成能力。
解决学术问题
该数据集有效解决了学术研究中获取大规模、多语言、结构清晰文本数据的难题。传统维基百科原始数据包含大量模板、表格等噪声,不利于直接用于模型训练。本数据集通过清洗转换,剥离无关元素,保留了核心可读内容与文档结构,为语言模型理解、知识图谱构建、跨语言信息检索等研究提供了标准化、高质量的数据基础,推动了知识密集型自然语言处理任务的发展。
衍生相关工作
基于此类结构化维基百科数据,衍生出众多经典研究工作。例如,在语言模型预训练领域,它常被用于构建训练语料以提升模型的世界知识容量。在检索增强生成领域,相关研究利用其结构化信息优化文档检索与答案生成。此外,该数据集也支撑了多语言知识对齐、开放域问答系统评估基准构建等一系列重要学术探索。
以上内容由遇见数据集搜集并总结生成


