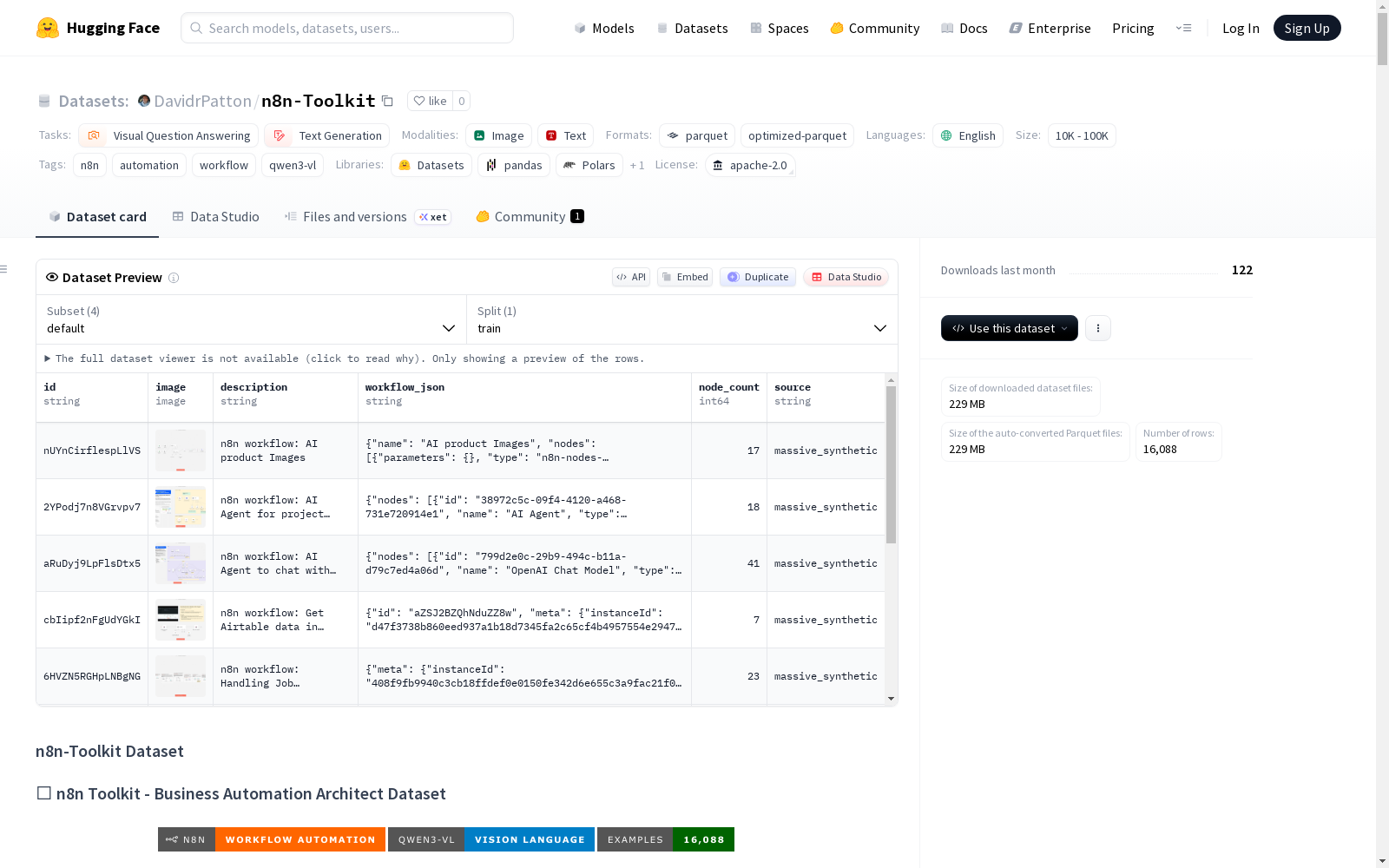
n8n-Toolkit
收藏n8n-Toolkit 数据集概述
基本信息
- 数据集名称: n8n-Toolkit
- 创建者: DavidrPatton
- 许可证: Apache 2.0
- 主要任务类别: 视觉问答、文本生成
- 语言: 英语
- 标签: n8n、自动化、工作流、qwen3-vl
- 规模: 10K<n<100K
- 总数据量: 16,088 个示例,约 229 MB
数据集配置
数据集包含三个独立的配置:
| 配置名称 | 示例数量 | 数据大小 | 格式 | 描述 |
|---|---|---|---|---|
| vision | 2,274 | 194 MB | 包含嵌入图像的 Parquet 文件 | 工作流截图与描述 |
| sharegpt | 10,827 | 25 MB | Parquet 文件 | 多轮对话格式 |
| thinking | 2,987 | 10 MB | Parquet 文件 | 思维链推理三元组 |
| default | 2,274 | 194 MB | Parquet 文件 | 默认配置,指向 vision 数据 |
设计目的
该数据集旨在将 Qwen3-VL-4B 或类似的视觉语言模型微调为 业务自动化架构师,使其具备以下能力:
- 根据自然语言描述设计 n8n 工作流。
- 理解工作流截图并解释其功能。
- 对复杂的自动化任务进行思维链推理。
- 围绕工作流优化和调试进行多轮对话。
数据内容覆盖范围
数据集涵盖 50+ 个平台和集成 的训练数据。
核心自动化技术
- n8n: 超过 21,400 次提及,完整的工作流自动化平台覆盖。
- 工作流设计: 超过 20,200 次提及。
- 自动化模式: 超过 12,400 次提及。
- API 集成: 超过 11,200 次提及。
- Webhooks: 超过 7,300 次提及。
AI 与 LLM 平台
包括 OpenAI/GPT、LangChain、AI Agents、Qwen、Gemini、Anthropic/Claude、LLaMA、Mistral、Dify、CrewAI、AutoGen、LlamaIndex、LangGraph 等。
RAG 与向量数据库
包括 RAG 管道、Embeddings、Pinecone、Qdrant、Weaviate 等。
业务平台
包括 Google Workspace、HubSpot、Salesforce、Pipedrive、Odoo、GoHighLevel 等。
通信与消息平台
包括 Slack、Discord、Telegram、WhatsApp、Email、Mattermost、Twilio 等。
社交媒体平台
包括 Twitter/X、LinkedIn、Facebook、Instagram、YouTube 等。
数据库与存储
包括 PostgreSQL、MySQL、MongoDB、Redis、Supabase、Firebase、Airtable、Notion 等。
浏览器自动化与测试
包括 Puppeteer、Playwright、Selenium、Cypress、Web Scraping 等。
开发者工具
包括 GitHub、Docker、AWS、React、HTTP/REST、OAuth、JSON Processing 等。
电子商务与支付
包括 Stripe、Shopify、WooCommerce、WordPress 等。
数据格式与处理
包括 JSON、Excel、HTML、PDF、CSV、XML、Markdown 等。
媒体与多模态
包括 Vision/Images、Video、Audio、Multimodal AI 等。
配置详情
Vision 配置(默认)
包含带有嵌入图像的工作流截图,用于视觉语言训练。
字段:
id: 字符串,唯一工作流标识符。image: 图像,n8n 工作流的嵌入式 PNG 截图。description: 字符串,工作流的自然语言描述。workflow_json: 字符串,n8n 工作流的完整 JSON 表示。node_count: 整数,工作流中的节点数量。source: 字符串,数据来源。
图像来源: 所有 2,274 个示例均包含高分辨率 n8n 工作流编辑器截图,显示完整的工作流画布、节点和连接。
ShareGPT 配置
包含标准 ShareGPT 格式的多轮对话,用于指令微调。
字段:
conversations: 字符串(JSON),{from, value}对话轮次数组。category: 字符串,工作流类别。domain: 字符串,业务领域。complexity: 字符串,难度级别。instruction: 字符串,任务指令。input: 字符串,用户输入/上下文。output: 字符串,预期响应。
类别分布: 主要类别包括 General Automation (25.2%)、Automation Framework (27.3%)、Data Processing (2.1%)、Code Implementation (1.4%)、UI Documentation (1.2%) 等。
Thinking 配置
包含思维链推理三元组,用于训练审慎推理能力。
字段:
prompt: 字符串,任务描述或用户请求。json: 字符串,生成的 n8n 工作流 JSON。thinking: 字符串,逐步推理过程。
思维过程结构: 包括问题分析、节点选择、配置推理、连接逻辑和边缘情况考虑。
使用方式
加载数据集
python from datasets import load_dataset vision_ds = load_dataset("DavidrPatton/n8n-Toolkit", "vision") sharegpt_ds = load_dataset("DavidrPatton/n8n-Toolkit", "sharegpt") thinking_ds = load_dataset("DavidrPatton/n8n-Toolkit", "thinking")
访问 Vision 数据
python ds = load_dataset("DavidrPatton/n8n-Toolkit", "vision", split="train") example = ds[0]
解析 ShareGPT 对话
python import json ds = load_dataset("DavidrPatton/n8n-Toolkit", "sharegpt", split="train") example = ds[0] conversations = json.loads(example[conversations])
训练指导
推荐用例
| 用例 | 配置 | 说明 |
|---|---|---|
| 视觉语言微调 | vision |
训练模型理解工作流截图 |
| 指令微调 | sharegpt |
通用 n8n 知识和对话能力 |
| 推理增强 | thinking |
复杂工作流设计的思维链 |
| 完整业务架构师 | 全部三个 | 完整能力覆盖 |
兼容的训练框架
- Unsloth
- Axolotl
- LLaMA-Factory
- Hugging Face TRL
数据格式与结构
文件结构
n8n-Toolkit/ ├── vision/ │ └── train-00000-of-00001.parquet ├── sharegpt/ │ └── train-00000-of-00001.parquet └── thinking/ └── train-00000-of-00001.parquet
n8n 工作流 JSON 模式
遵循官方 n8n 工作流格式,包含 name、nodes、connections、active 等字段。
相关资源
- n8n 文档: https://docs.n8n.io
- n8n GitHub: https://github.com/n8n-io/n8n
- Qwen3-VL: https://huggingface.co/Qwen/Qwen3-VL-4B
统一版本
如需一次性训练所有数据,可使用预合并和格式化的统一版本:DavidrPatton/n8n-toolkit-combined (https://huggingface.co/datasets/DavidrPatton/n8n-toolkit-combined)。