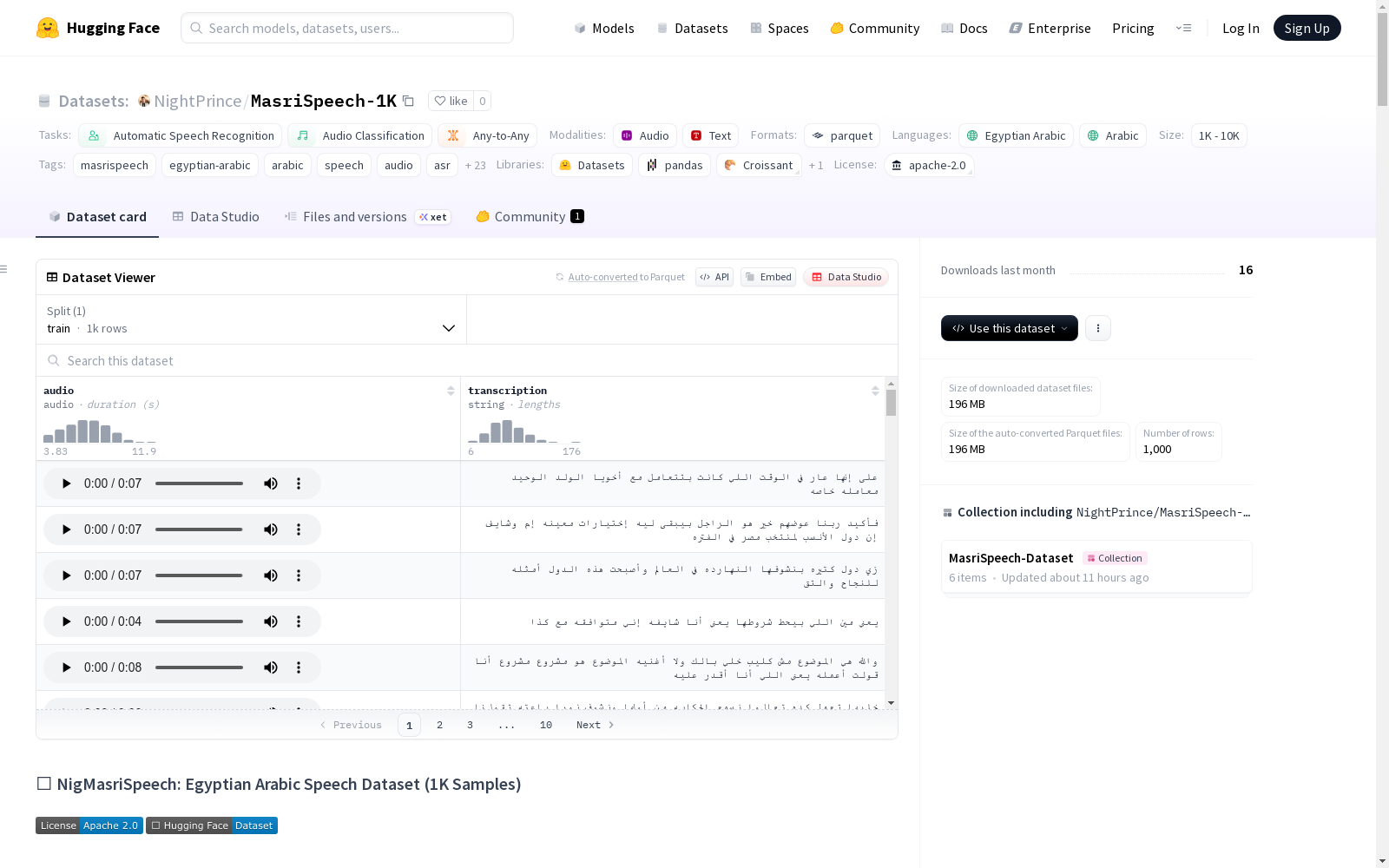
MasriSpeech-1K
收藏NigMasriSpeech: Egyptian Arabic Speech Dataset (1K Samples) 数据集概述
数据集基本信息
- 名称: NigMasriSpeech
- 类型: 语音数据集
- 语言: 阿拉伯语 (ar)、埃及阿拉伯语 (arz)
- 许可证: Apache 2.0
- 大小类别: 1K<n<10K
- 任务类别: 自动语音识别、音频分类、任意到任意转换
数据集内容
- 总样本数: 1,000
- 采样率: 16 kHz
- 总时长: ~10小时
- 格式: Parquet
- 数据集大小: 220 MB
- 下载大小: 195 MB
- 注释: 转录文本
数据集结构
- 特征:
audio: 音频特征对象,包含原始语音波形、相对音频路径和采样率 (16,000 Hz)transcription: 埃及阿拉伯语转录文本
- 分割:
train: 1,000个样本
数据统计
- 分割分布:
- Train: 1,000个样本,220 MB,平均单词数13.34,无空文本,无非阿拉伯语文本
- 语言分析:
- Top Words: في (202), و (169)
- Top Bigrams: (إن, أنا) (13)
- 词汇量: 384
- 独特说话者: 10
使用示例
-
加载数据集: python from datasets import load_dataset ds = load_dataset(NightPrince/MasriSpeech-1K, split=train, streaming=True)
-
预处理: python def prepare_dataset(batch): audio = batch["audio"] inputs = processor.feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt") batch["input_values"] = inputs.input_values[0] labels = processor.tokenizer(batch["transcription"], return_tensors="pt") batch["labels"] = labels["input_ids"][0] return batch
-
微调ASR模型: python training_args = TrainingArguments( output_dir="./results", learning_rate=2e-5, per_device_train_batch_size=16, num_train_epochs=3, ) trainer = Trainer(model=model, args=training_args, train_dataset=dataset) trainer.train()
引用
bibtex @dataset{nigmasrispeech, author = {Yahya Muhammad Alnwsany}, title = {NigMasriSpeech: Egyptian Arabic Speech Dataset (1K Samples)}, year = {2025}, publisher = {Hugging Face}, url = {https://huggingface.co/collections/NightPrince/masrispeech-dataset-68594e59e46fd12c723f1544} }
使用案例
- 埃及阿拉伯语的自动语音识别 (ASR) 模型微调
- 方言阿拉伯语语言学研究
- 语音合成和语音克隆
- 低资源语言的机器学习和基准测试