Liberty-Violence
收藏Hugging Face2026-01-09 更新2026-01-10 收录
下载链接:
https://huggingface.co/datasets/GilatToker/Liberty-Violence
下载链接
链接失效反馈官方服务:
资源简介:
LIBERTy-工作场所暴力数据集是LIBERTy基准测试的一部分,旨在评估NLP中基于概念的解释方法,采用因果和反事实框架。该数据集专注于通过护士风格的工作场所叙述的多类文本分类来预测工作场所暴力风险。输入为自由文本对话,预测目标是根据对话内容识别护士暴露于的工作场所暴力风险级别(无暴力、言语暴力、身体暴力)。数据集包含多个核心概念(如性别、年龄、种族等),这些概念之间存在结构化依赖关系,可用于解释忠实度的定量评估。数据集分为训练、测试、基线和反事实评估文件,适用于评估解释方法、研究因果效应以及在受控干预下比较方法。数据为合成数据,属性值为编码形式,反事实样本为生成数据。
The LIBERTy-Workplace Violence Dataset is part of the LIBERTy benchmark, which aims to evaluate concept-based explanation methods in natural language processing (NLP) using causal and counterfactual frameworks. This dataset focuses on predicting workplace violence risk through multi-class text classification of nurse-style workplace narratives. Its inputs are free-text conversations, and the prediction target is to identify the level of workplace violence risk (no violence, verbal violence, physical violence) that nurses are exposed to based on the conversation content. The dataset includes multiple core concepts (e.g., gender, age, race, etc.) that have structured dependencies between them, which can be used for quantitative evaluation of explanation faithfulness. The dataset is divided into training, test, baseline, and counterfactual evaluation files, which are suitable for evaluating explanation methods, studying causal effects, and comparing methods under controlled interventions. The data is synthetic, with attribute values in encoded form, and counterfactual samples are generated data.
创建时间:
2026-01-06
原始信息汇总
LIBERTy: Workplace Violence Dataset 概述
数据集基本信息
- 数据集名称:LIBERTy: Workplace Violence Dataset
- 任务类型:文本分类、特征提取
- 语言:英语
- 标签:可解释性、基准测试、因果推断、反事实
- 数据规模:1K < n < 10K
- 文件格式:CSV
数据集背景
LIBERTy-Workplace Violence 数据集是 LIBERTy (LLM-based Interventional Benchmark for Explainability with Real Targets) 基准测试中发布的三个数据集之一。该基准旨在 因果与反事实框架下 评估 NLP 中的 基于概念的解释方法。每个数据集揭示了 高层语义概念 与模型预测之间的结构化依赖关系,支持使用真实干预对解释的忠实度进行 定量评估。
完整的 LIBERTy 基准包含:
- 简历筛选
- 工作场所暴力预测(本数据集)
- 疾病诊断预测
任务描述
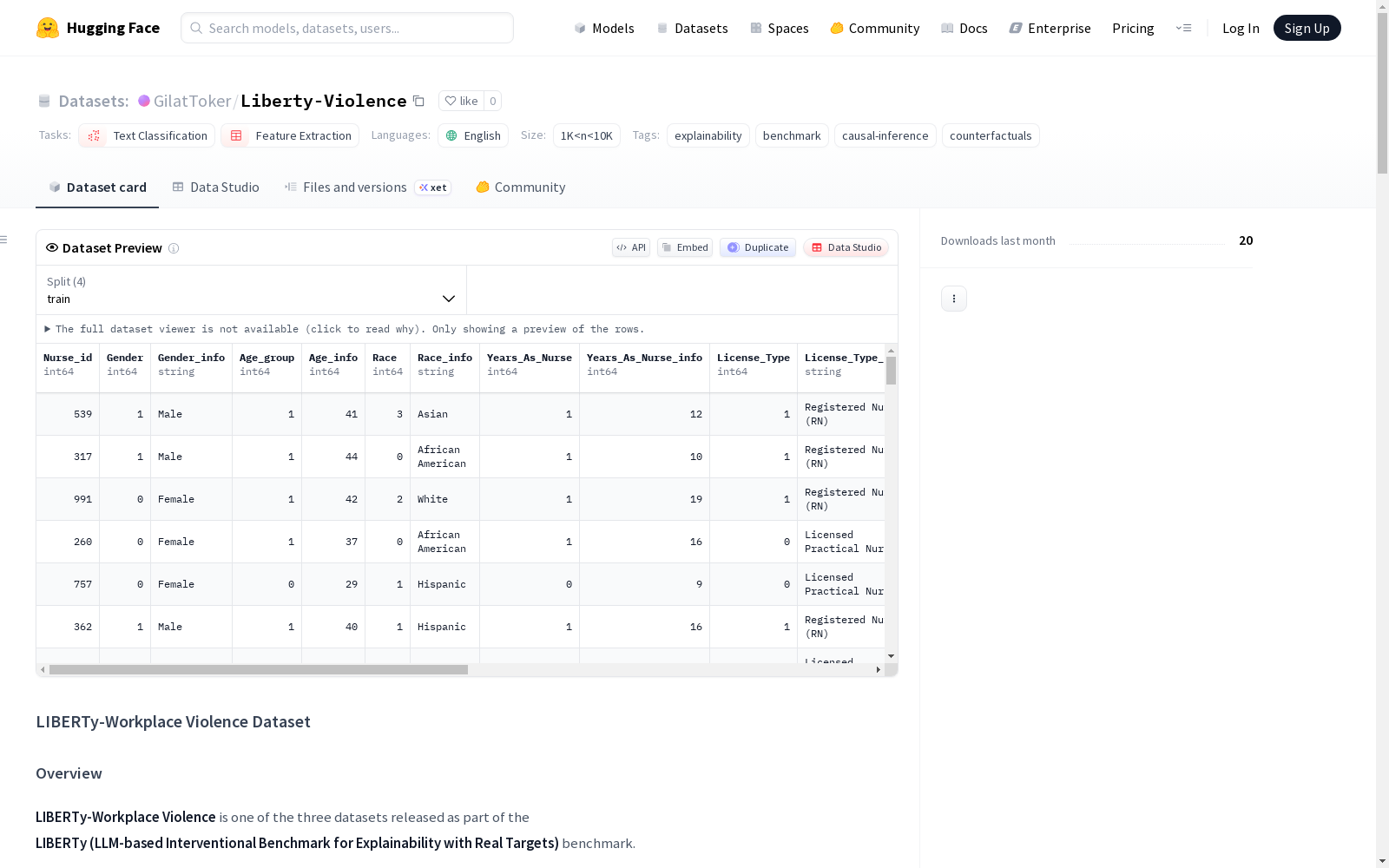
该任务是一个基于护士风格工作场所叙述的 多类别文本分类问题。
- 输入:一段自由文本对话,记录了护士与人力资源部门之间的互动,其中护士描述了其工作条件、角色、背景和经历。
- 预测目标:根据对话内容,识别护士所面临的 工作场所暴力风险等级。
- 目标标签 (
Violence_Experience):0– 无暴力1– 言语暴力2– 身体暴力
核心概念与列
数据集定义了一系列结构化概念及其编码关系:
Gender (G):{0: 女性, 1: 男性}。子概念:License,Department。Age (A):{0: 24–32, 1: 34–44, 2: 46–55}。子概念:Tenure,License。Race (R):{0: 非裔美国人, 1: 西班牙裔, 2: 白人, 3: 亚裔}。子概念:License,Department,Seniority,Violence_Experience。Tenure (T):{0: 4–9, 1: 10–19, 2: 20–25}。父概念:Age。子概念:Seniority,Violence_Experience。License (L):{0: LPN, 1: RN, 2: APRN}。父概念:Gender,Race,Age。子概念:Seniority,Violence_Experience。Department (D):{0: 家庭医疗, 1: ICU, 2: 精神/心理健康, 3: 急诊科}。父概念:Gender,Race。子概念:Violence_Experience。Seniority (S):{0: 普通员工, 1: 经验丰富的员工, 2: 中层管理, 3: 高级管理}。父概念:Age,Gender,Race,Tenure,License。子概念:Violence_Experience。
关键特性:
- 这些概念 不直接提供给预测模型。
- 可以从文本中 恢复。
- 可以通过反事实生成进行 独立干预。
数据集结构
数据集以 CSV 格式 提供,并根据其在训练和评估中的角色分为多个文件。
文件说明
-
Final_Violence_model_train-4o - Copy.csv- 用途:用于 学习预测模型 的训练集。
- 内容:仅包含原始(非反事实)陈述,保留了概念与目标标签之间的自然相关性。
- 注意:解释方法 不在此分割上训练。
-
Final_Violence_model_test-4o - Copy.csv- 用途:用于 评估预测模型 的测试集。
- 内容:包含从与训练集相同的数据生成过程中采样的未见过的原始示例。
-
Final_Violence_wo_f_baseline-4o - Copy.csv- 用途:用于 校准和拟合解释方法 的基线集。
- 内容:仅包含原始(非反事实)示例。
- 注意:不用于训练预测模型,但作为某些解释技术所需的辅助数据。
-
Final_Violence_w_cf-4o - Copy.csv- 用途:用于 评估解释方法 的反事实评估集。
- 内容:包含测试示例的反事实版本,其中对单个概念进行了干预,同时最大限度地保留了所有其他内容。
- 目的:通过将解释方法估计的概念影响与数据集中结构因果模型编码的真实因果效应进行比较,来评估解释方法。
预期用途
本数据集适用于:
- 评估 基于概念的解释方法。
- 研究 NLP 模型中 概念的因果效应。
- 在 受控干预 下比较解释方法。
典型的评估协议包括:
- 反事实预测比较
- 概念重要性排序
- 忠实度指标,如基于 ICaCE 的误差
注意事项与限制
- 所有数据均为合成数据,不对应真实个体。
- 属性值已编码;用户应避免推断真实的人口统计分布。
- 反事实样本的生成旨在保持文本连贯性,但可能无法捕捉所有现实世界的细微差别。
相关论文
本数据集附随论文 “LIBERTy: A Causal Framework for Benchmarking Concept-Based Explanations of LLMs with Structural Counterfactuals”,该论文已提交,并将在不久的将来在 arXiv 上公开发布。
搜集汇总
数据集介绍
构建方式
在医疗叙事文本分类领域,LIBERTy-Workplace Violence数据集采用结构化因果模型框架构建。其核心在于通过合成生成护士与人力资源部门之间的对话文本,模拟真实职场环境中的互动场景。数据生成过程严格遵循预设的概念层级关系,包括性别、年龄、种族等人口统计学变量,以及任期、执照类型、部门与资历等职业属性。这些概念以隐式方式嵌入叙事文本,形成自然语言表达,同时确保每个概念可独立干预,为后续反事实样本的生成奠定基础。数据划分依据不同实验目的,分别提供训练、测试、基线校准及反事实评估四个子集,以支持模型训练与解释性方法的系统评估。
特点
该数据集最显著的特点在于其内置的结构化因果依赖关系,将高级语义概念与预测目标通过明确的父子节点网络相连。每个叙事文本均隐含了人口属性与职业变量之间的复杂关联,这些概念虽未直接作为特征输入模型,却可从文本中自动推断。数据集特别设计了反事实评估子集,通过对单一概念进行干预而保持其余内容不变,生成语义连贯的对比样本。这种设计使得研究者能够定量衡量解释方法的忠实度,将概念重要性排序与真实因果效应进行比对。数据集专注于职场暴力风险的多分类任务,涵盖无暴力、言语暴力与身体暴力三个等级,为可解释性研究提供了高度可控的基准环境。
使用方法
使用该数据集时,研究者首先利用训练子集构建预测模型,学习从护士叙事文本中识别职场暴力风险等级。测试子集用于评估模型的标准分类性能,确保其具备可靠的预测能力。基线子集则专为解释方法服务,供其学习概念表示或估计投影空间,而不参与预测模型的训练。最关键的反事实子集用于评估解释方法的因果忠实性:通过对比模型在原始样本与概念干预后样本上的预测变化,计算解释方法所估计的概念影响与真实干预效果之间的误差。典型评估指标包括反事实预测比较、概念重要性排序以及基于ICaCE的忠实度度量,从而在受控干预环境下系统比较不同解释方法的优劣。
背景与挑战
背景概述
LIBERTy-Workplace Violence 数据集作为 LIBERTy 基准测试的关键组成部分,于近期由研究团队提出,旨在推动自然语言处理领域中对可解释性方法的因果评估。该数据集聚焦于职场暴力风险预测,通过模拟护士与人力资源部门的对话叙事,构建了一个多类别文本分类任务,以识别言语或身体暴力的风险等级。其核心创新在于引入了结构化因果模型,明确设定了性别、年龄、种族等高层次语义概念与预测目标之间的依赖关系,从而为基于概念的解释方法提供了具有地面真实干预的量化评估框架。这一工作标志着可解释人工智能研究从相关性分析向因果推断的重要转变,为理解复杂语言模型内部决策机制开辟了新路径。
当前挑战
该数据集致力于解决自然语言处理中概念可解释性评估的挑战,即在缺乏真实因果干预数据的情况下,如何客观衡量解释方法的忠实性。具体而言,构建过程面临双重困难:一是需设计并生成既保持文本连贯性,又能精确反映单一概念干预的对抗样本,这要求合成数据在语义合理性与因果隔离性之间取得平衡;二是必须建立清晰的概念层次结构与数据生成机制,确保每个概念既能从文本中恢复,又可独立进行干预,从而为评估提供可靠的基础真值。这些挑战共同指向了合成数据生成的质量控制与因果框架的严谨实现问题。
常用场景
经典使用场景
在自然语言处理领域,概念解释方法的评估常因缺乏结构化因果基准而受限。Liberty-Violence数据集通过构建护士职场叙事文本,系统化地嵌入了人口统计学与职业属性等高层语义概念,为研究者提供了一个标准化的多分类任务平台。该数据集最经典的使用场景在于,利用其反事实干预样本,量化评估模型解释方法在识别职场暴力风险时的忠实度与因果推断能力,从而推动可解释人工智能在文本分类中的严谨发展。
实际应用
在医疗健康与人力资源管理领域,职场暴力风险预测具有重要的现实意义。该数据集虽为合成数据,但其构建逻辑模拟了护士与人力资源部门的真实对话场景,能够支持开发更透明、公平的风险评估模型。通过分析叙事文本中隐含的人口与职业因素,此类模型可辅助机构识别高风险情境,制定预防性干预策略,从而在保护医护人员福祉、提升职场安全方面提供数据驱动的决策支持。
衍生相关工作
围绕Liberty-Violence数据集,已衍生出一系列专注于因果可解释性的经典研究工作。其核心框架LIBERTy催生了针对概念干预的评估协议,如反事实预测比较与ICaCE误差度量。相关研究进一步探索了如何从文本中稳健恢复结构化概念,并开发了基于该基准的模型解释技术对比分析。这些工作共同推动了自然语言处理中因果解释范式的形成,为后续构建更复杂的语义干预基准提供了方法论基础。
以上内容由遇见数据集搜集并总结生成


