MM-EQA Benchmark
收藏arXiv2026-02-06 更新2026-02-07 收录
下载链接:
https://comm-cp.github.io
下载链接
链接失效反馈官方服务:
资源简介:
MM-EQA Benchmark是由加州大学河滨分校可信自主系统实验室构建的多智能体多任务具身问答基准数据集,基于真实场景的Habitat-Matterport 3D数据集开发。该数据集包含丰富的照片级真实家庭环境场景,用于评估智能体在自然语言指令下的协作探索与问答能力。数据集的创建过程涉及对3D场景的语义标注和任务设计,旨在解决多异构机器人协同完成复杂家庭任务时的信息共享与决策优化问题,推动具身智能在真实环境中的实际应用。
The MM-EQA Benchmark is a multi-agent, multi-task embodied question answering benchmark dataset constructed by the Trusted Autonomous Systems Laboratory at the University of California, Riverside. It is developed based on the real-scene-oriented Habitat-Matterport 3D dataset. This dataset includes abundant photorealistic home environment scenes, and is used to evaluate the collaborative exploration and question answering capabilities of agents under natural language instructions. The creation process of the dataset involves semantic annotation of 3D scenes and task design, aiming to solve the problems of information sharing and decision optimization when multiple heterogeneous robots collaborate to complete complex household tasks, so as to promote the practical application of embodied intelligence in real-world environments.
提供机构:
加州大学河滨分校·可信自主系统实验室
创建时间:
2026-02-06
搜集汇总
数据集介绍
构建方式
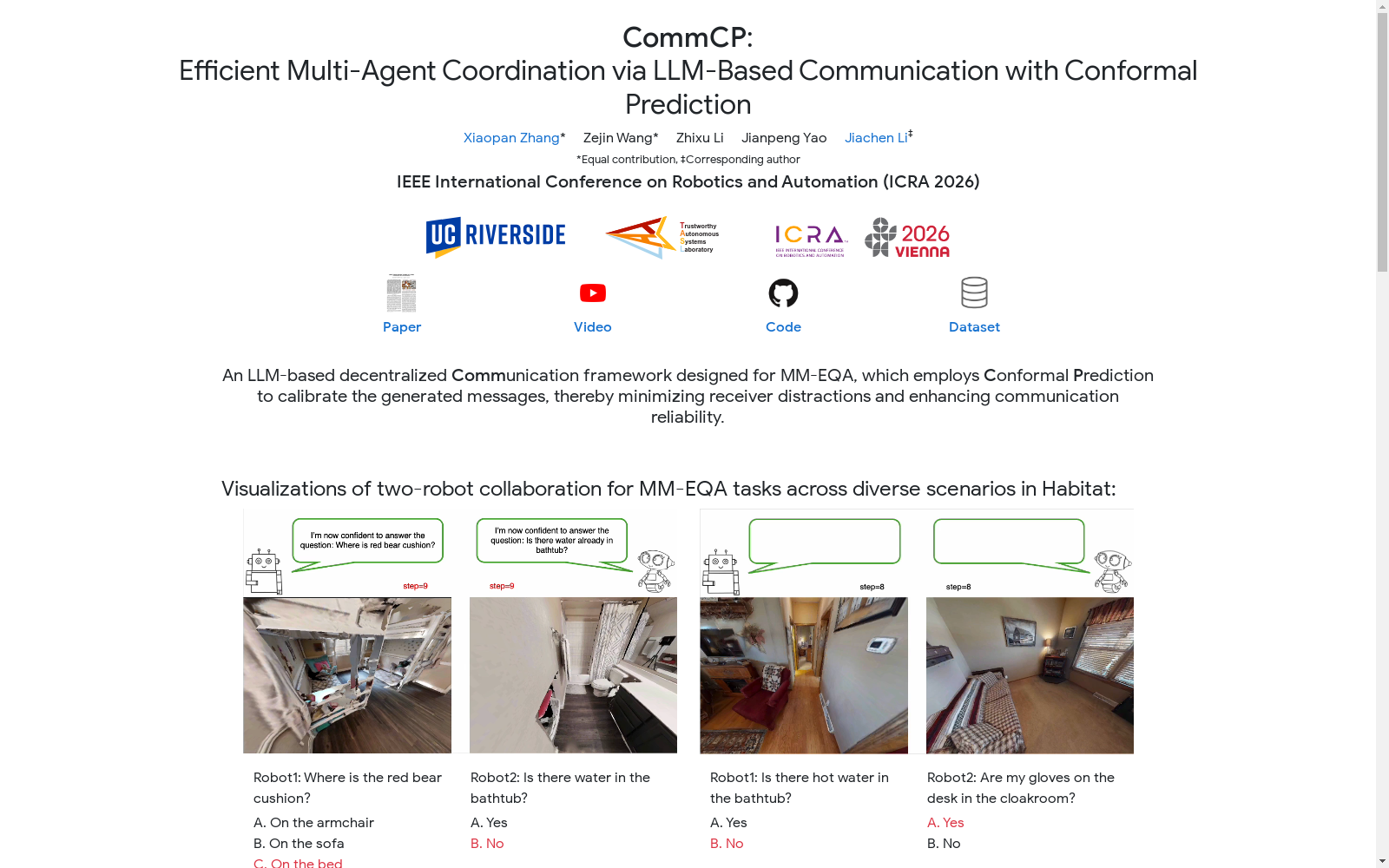
在具身人工智能领域,多机器人协作的信息获取效率是核心挑战之一。MM-EQA基准的构建依托于高度逼真的Habitat-Matterport 3D(HM3D)室内场景数据集,通过精心设计的流程生成多样化的具身问答任务。研究团队利用GPT-4V等先进模型,在70个不同的三维家居场景中,为每个场景生成了六个需要语义推理的多选题,涵盖物体定位、属性识别、数量统计、存在性判断及状态查询五种类型。为确保任务的真实性与挑战性,生成过程辅以人工审核与精炼,最终形成了包含420个任务的评估基准,并额外使用20个场景构建了用于置信度校准的数据集。
使用方法
该数据集主要用于评估和推进多智能体具身问答系统的研究。使用者可通过Habitat仿真平台加载三维场景与任务定义,部署具有不同通信策略的智能体模型。典型的使用流程包括:初始化智能体于随机位姿,使其在共享环境中根据分配的问题进行探索;智能体可基于自身观测生成语义地图,并通过通信模块交换经校准的相关物体信息或答案;评估时,系统会记录智能体在最大时间限制内正确回答问题的情况,并计算其探索路径的时间成本。研究者可基于此基准比较不同通信算法在提升任务成功率和减少探索耗时方面的性能,尤其适用于验证去中心化、基于大语言模型的协作框架的有效性。
背景与挑战
背景概述
MM-EQA Benchmark 由加州大学河滨分校可信自主系统实验室的研究团队于2026年提出,旨在解决多智能体协作场景下的具身问答问题。该基准将经典的具身问答任务扩展至多智能体多任务环境,聚焦于异构机器人在共享三维空间内通过自然语言交流协同完成信息搜集任务。其核心研究问题在于如何设计高效可靠的通信机制,以协调多个智能体的探索行为,避免冗余操作并提升整体任务成功率。该数据集的建立推动了具身人工智能在复杂家居场景下的协同决策研究,为多机器人系统的自然语言交互与协作提供了标准化评估框架。
当前挑战
MM-EQA Benchmark 所针对的领域挑战在于多智能体具身问答中高效协同探索与可靠通信的难题。具体而言,智能体需在未知环境中动态理解同伴的任务需求,并交换精准相关的观察信息以引导探索路径,避免因信息冗余或误导而降低效率。在构建过程中,挑战主要体现于如何基于光真实感三维家居场景生成多样化的具身问答任务,并确保问题涵盖位置识别、物体属性、数量统计、存在性及状态判断等多种语义推理类型。同时,构建校准数据集以支持基于保形预测的通信置信度校准,亦需解决场景采样与语义标注的复杂性问题。
常用场景
经典使用场景
在具身人工智能领域,多机器人协同完成自然语言指令任务已成为前沿研究方向。MM-EQA Benchmark作为该领域首个多智能体多任务具身问答基准,其经典使用场景聚焦于模拟真实家庭环境中多个异构机器人协同进行信息探索与问答。该场景中,每个机器人被分配不同的具身问答任务,例如定位特定物品或判断物体状态,它们需要在共享的三维环境中自主导航、感知环境,并通过自然语言通信交换观测信息,以协作方式高效完成所有问题解答。这一场景深刻体现了从单智能体到多智能体协同的范式转变,为研究去中心化通信与协作探索提供了标准化的实验平台。
解决学术问题
MM-EQA Benchmark的提出,系统性地解决了具身人工智能中几个关键的学术研究问题。它首次将经典的单智能体具身问答问题扩展至多智能体多任务协同场景,从而能够研究在共享环境下去中心化通信对探索效率的影响。该数据集通过构建多样化的家庭场景与复杂的语义推理问题,为评估多智能体通信策略的效能提供了量化基准。其核心意义在于推动了协同具身智能的发展,使得研究重心从个体能力转向群体协作,为解决现实世界中多机器人系统面临的信息冗余、通信效率与任务分配等挑战奠定了实证基础。
实际应用
超越学术研究,MM-EQA Benchmark所模拟的场景具有明确的现实应用指向。其直接对应于未来智能家居、仓储物流及灾难救援等领域中多机器人协同作业的需求。例如,在大型家庭环境中,多个服务机器人可分别执行‘检查厨房炉灶是否关闭’与‘寻找客厅的遥控器’等任务,通过高效通信共享各自观测到的‘炉灶’或‘电视柜’位置信息,避免重复探索,从而快速协同完成用户指令。该数据集通过提供逼真的三维家庭环境与任务,使得在此基准上开发的通信与规划算法能够更平滑地迁移至实际机器人部署,提升多机器人系统在复杂动态环境中的作业鲁棒性与整体效率。
数据集最近研究
最新研究方向
在具身人工智能领域,多智能体协作的通信效率与可靠性成为前沿探索的核心议题。MM-EQA基准的提出,将经典具身问答任务扩展至多智能体多任务场景,聚焦于异构机器人在共享环境中通过自然语言交流协同完成信息搜集任务。当前研究热点集中于利用大语言模型生成通信内容,并通过集成保形预测等不确定性校准技术,以克服模型幻觉与过度自信带来的信息干扰,从而提升多智能体系统的探索效率与任务成功率。这一方向不仅推动了具身智能在复杂家庭环境中的实际部署,也为去中心化多机器人系统的可靠通信奠定了新的方法论基础,具有重要的理论价值与应用前景。
相关研究论文
- 1CommCP: Efficient Multi-Agent Coordination via LLM-Based Communication with Conformal Prediction加州大学河滨分校·可信自主系统实验室 · 2026年
以上内容由遇见数据集搜集并总结生成


