SlimPajama-Meta-rater
收藏Hugging Face2025-06-11 更新2025-06-12 收录
下载链接:
https://huggingface.co/datasets/opendatalab/SlimPajama-Meta-rater
下载链接
链接失效反馈官方服务:
资源简介:
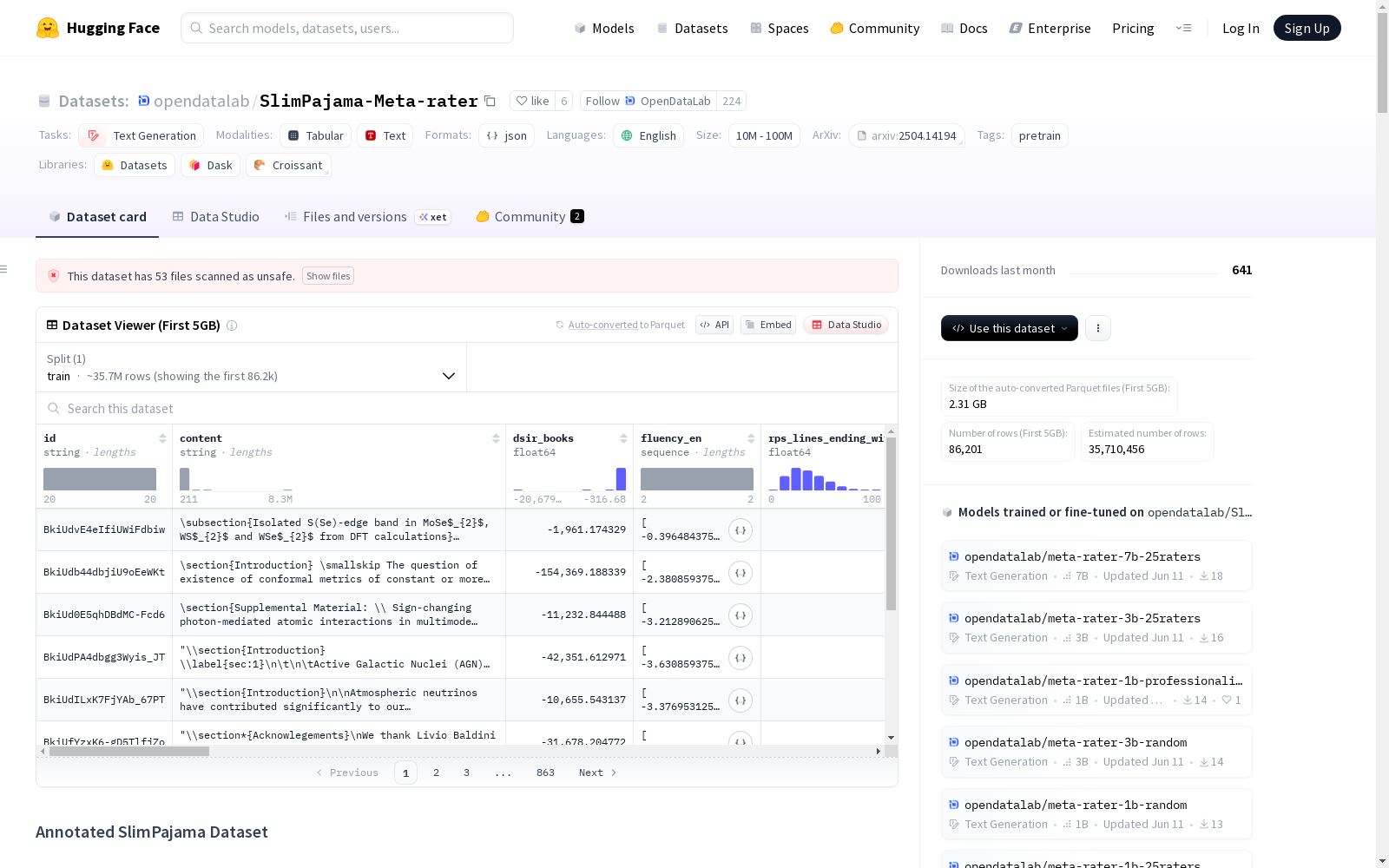
SlimPajama-627B-Annotated数据集是一个包含全面质量指标的大规模语言模型研究数据集。该数据集包含约5800亿个token,覆盖了25个不同的质量维度,包括自然语言质量信号、数据重要性评分和基于模型的评分。数据集来自7个领域,包括CommonCrawl、C4、GitHub、Books、ArXiv、Wikipedia和StackExchange。此外,数据集还引入了PRRC框架,从专业度、可读性、推理能力和清洁度四个维度对数据进行全面评估。数据集结构清晰,易于使用,并提供了多种应用场景。
The SlimPajama-627B-Annotated dataset is a large-scale language model research dataset equipped with comprehensive quality metrics. It contains approximately 580 billion tokens and covers 25 distinct quality dimensions, including natural language quality signals, data importance scores, and model-based scores. The dataset is sourced from 7 domains, namely CommonCrawl, C4, GitHub, Books, ArXiv, Wikipedia, and StackExchange. Additionally, the PRRC framework is introduced to comprehensively evaluate data across four dimensions: professionalism, readability, reasoning capability, and cleanliness. With a clear structure that enables easy usage, the dataset supports a variety of application scenarios.
创建时间:
2025-06-10
搜集汇总
数据集介绍
构建方式
在数据驱动的语言模型研究领域,SlimPajama-Meta-rater数据集通过多维度标注体系构建而成。该数据集基于原始SlimPajama训练集的5800亿个token,采用三层质量评估框架:首先运用RedPajama的11项规则化自然语言质量指标,包括词汇特征统计和文本结构分析;其次整合DSIR数据重要性评分,衡量文本与高质量领域(书籍、维基百科、数学文本)的相似度;最后引入创新的PRRC模型评分体系,通过现代BERT模型对专业性、可读性、推理性和清洁度四个维度进行六等级精细评估。
特点
该数据集最显著的特征在于其全面的质量评估维度,涵盖25个精心设计的质量指标。PRRC框架作为核心创新,通过专业性指标评估文本所需的专业知识深度,可读性指标衡量文本清晰度与连贯性,推理性指标分析逻辑思维复杂度,清洁度指标考察文本格式规范与噪声控制。这些指标不仅覆盖传统语言质量特征,更深入语义层面,为研究者提供前所未有的细粒度质量洞察。跨七个领域(CommonCrawl、C4、GitHub等)的全面标注确保了数据集的代表性和实用性。
使用方法
研究者可通过HuggingFace数据集库直接加载该数据集,利用提供的Python代码示例进行多维度质量分析。数据处理时需将模型输出的logits通过argmax函数转换为具体评分,如将modernbert_professionalism的六个logits值转换为0-5分的专业度评级。数据集支持基于元评分器权重的质量加权计算,用户可依据研究需求调整各维度权重,实现精准的数据筛选。该数据集特别适用于构建高质量训练子集、分析质量指标相关性以及开发数据选择基准,为语言模型预训练提供科学的数据质量保障。
背景与挑战
背景概述
SlimPajama-Meta-rater数据集由OpenDataLab团队于2025年推出,作为首个全面标注的大规模语言模型预训练数据集,承载着推动数据为中心的人工智能研究的重要使命。该数据集基于Cerebras的SlimPajama训练集构建,涵盖约5800亿个标记,通过25个质量维度对来自CommonCrawl、C4、GitHub等七大领域的文本进行精细化标注。研究团队创新性地提出了PRRC评估框架,从专业性、可读性、推理性和清洁度四个维度对文本质量进行多角度量化,为大规模语言模型的训练数据筛选提供了前所未有的细粒度标准。
当前挑战
该数据集致力于解决大规模文本数据质量评估的核心难题,包括如何定义和量化文本的多元质量属性,以及如何建立可靠的质量评估体系。在构建过程中,研究团队面临多重技术挑战:需要整合规则基础的自然语言质量信号、基于DSIR的数据重要性评分以及多种预训练模型的质量评级;需要设计高效的标注流程来处理海量数据,确保标注的一致性和准确性;还需要开发新颖的PRRC评估框架,通过现代BERT模型实现专业化、可读性、推理复杂度和清洁度的自动化评分,这些挑战的克服为数据驱动的语言模型研究奠定了坚实基础。
常用场景
经典使用场景
在自然语言处理领域,SlimPajama-Meta-rater数据集为大规模语言模型预训练提供了多维质量评估框架。该数据集通过整合25个质量维度的标注信息,包括语言自然度指标、数据重要性评分和模型驱动的质量评级,使研究者能够精确识别和筛选高质量训练语料。其经典应用场景体现在构建优质数据子集,通过元评分器加权算法实现智能数据选择,显著提升模型训练效率与性能表现。
实际应用
在实际应用层面,该数据集支撑了高效预训练系统的构建,使机构能够基于质量评分动态优化训练数据配置。企业可利用其多维评分系统快速筛选符合特定领域需求的高价值文本,如教育机构侧重教育价值评分,科技公司关注专业性与推理能力评分。该数据集还赋能跨领域质量对比分析,支持Wikipedia、ArXiv、GitHub等不同来源数据的质量分布研究,为行业级数据治理提供了标准化评估工具。
衍生相关工作
该数据集催生了多项创新性研究工作,特别是在数据选择算法和质量评估基准领域。基于其标注体系发展的元评分器加权算法成为数据选择的新范式,启发了后续基于学习的数据采样方法研究。其PRRC评估框架被扩展应用于多语言文本质量评估,衍生出跨语言质量迁移学习方案。该数据集还促进了质量维度相关性分析的研究,推动了基于图神经网络的质量指标关系建模等前沿工作的诞生。
以上内容由遇见数据集搜集并总结生成


