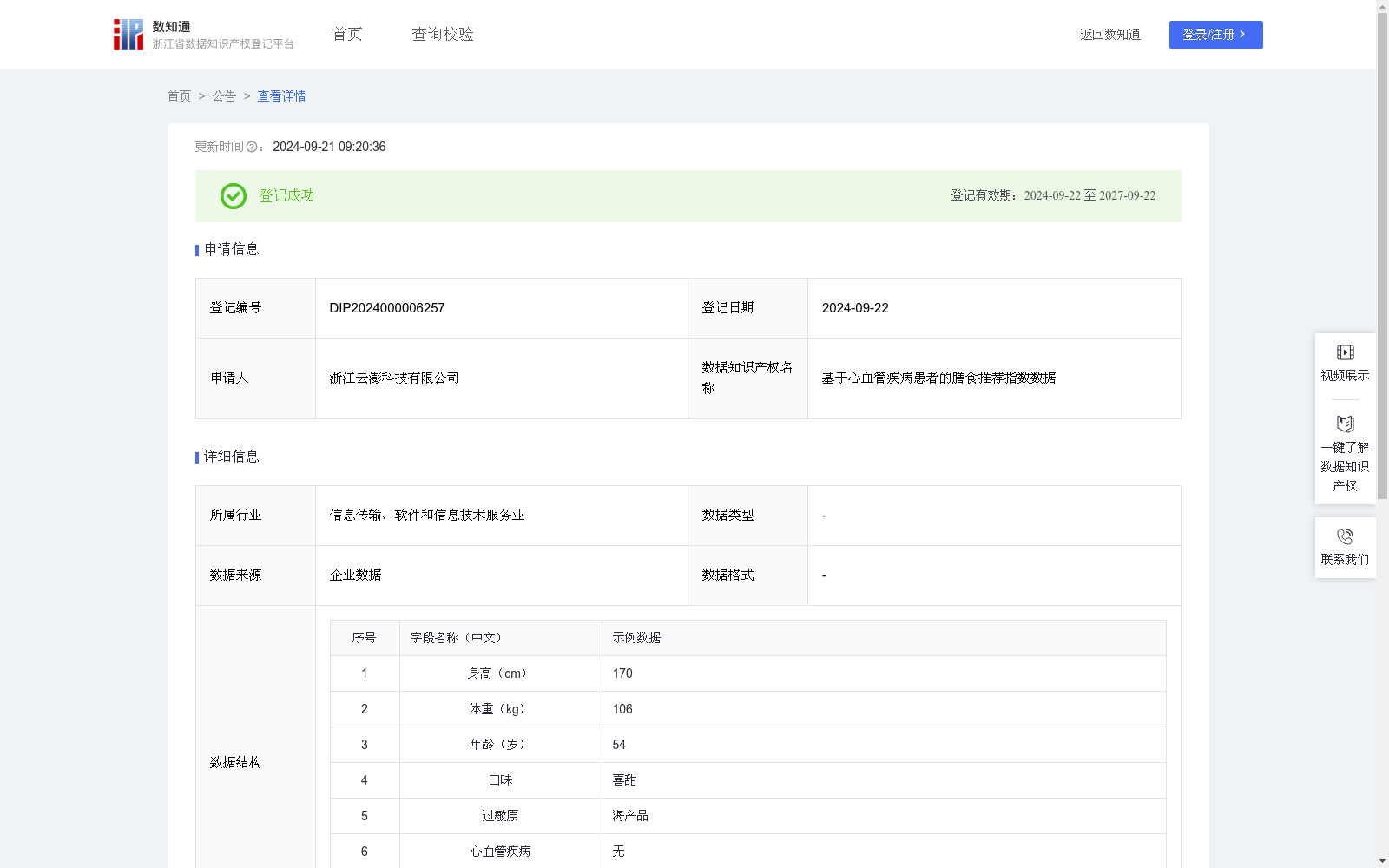
基于心血管疾病患者的膳食推荐指数数据
收藏浙江省数据知识产权登记平台2024-09-21 更新2024-09-22 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/63597
下载链接
链接失效反馈官方服务:
资源简介:
通过综合分析个人的基础数据,以及对心血管疾病的评测分析,利用专有算法计算出个性化的膳食推荐指数,为心血管疾病患者提供科学的饮食建议。
根据该指数了解患者的饮食需求,从而为患者制定出适合的健康饮食计划。通过对指数的长期观察,洞察患者饮食习惯的变化,并据此适时为患者调整饮食方案。
本数据适用于:
养老机构:根据患者的身体状况和健康需求,提供定制化的饮食建议。
研究机构:大学、研究所等科研机构可以利用这些数据知识产权进行营养学研究或临床试验。通过本公司健康管理产品,完成对心血管疾病的健康评测,将数据预处理后,输入到随机森林模型中,得出膳食推荐指数。
随机森林模型是通过构建多棵决策树并综合其预测结果。每棵决策树会根据身体指标特征重要性和分裂规则,对数据进行逐步的节点分裂,直至达到叶节点。
1.节点分裂:在每个内部节点,决策树根据某个身体指标特征向量及其阈值对数据进行分裂,选择信息增益最大的身体指标特征点和阈值。计算公式为:
Information Gain = H(S) - Σ (v ∈ Values(A)) |S_v| / |S| * H(S_v)
其中,H(S)是样本集 S 的熵,A 是特征,是特征 A 取值为时的样本子集。
2.综合多棵决策树的预测结果,最终的膳食推荐指数公式为:
(1/T) * ∑(从 t=1 到 T) y_t^(X)
其中,T是决策树的数量,y是第t棵决策树的预测值。X是输入的身体指标特征向量(身高、体重、年龄、口味偏好、过敏原、心血管疾病)。
By comprehensively analyzing an individual's basic data and cardiovascular disease (CVD) assessment results, this framework calculates a personalized dietary recommendation index via proprietary algorithms, delivering scientific dietary guidance for CVD patients.
The index helps identify the patient's dietary requirements, enabling the development of tailored healthy diet plans. Through long-term monitoring of the index, changes in the patient's eating habits can be detected, allowing timely adjustments to the diet plan.
This dataset is applicable to:
1. Elderly care institutions: Provide customized dietary advice based on the patient's physical condition and health needs.
2. Research institutions: Universities, research institutes and other scientific research organizations can leverage the dataset and its intellectual property rights to conduct nutritional research or clinical trials.
Using the company's health management products, the cardiovascular disease health assessment can be completed. After preprocessing the collected data, it is input into the random forest model to derive the dietary recommendation index.
The random forest model is constructed by building multiple decision trees and aggregating their predictive outputs. Each decision tree performs stepwise node splitting on the data based on the feature importance of physical indicators and splitting rules until reaching a leaf node.
1. Node Splitting: At each internal node, the decision tree splits the dataset based on a physical indicator feature vector and its corresponding threshold, selecting the feature and threshold that maximize the information gain. The calculation formula is:
Information Gain = H(S) - Σ (v ∈ Values(A)) |S_v| / |S| * H(S_v)
Where H(S) denotes the entropy of the sample set S, A represents the feature, and S_v is the sample subset where feature A takes the value v.
2. Aggregation of Decision Tree Predictions: The final formula for the dietary recommendation index is:
(1/T) * ∑(t=1 to T) y_t^(X)
Where T is the total number of decision trees, y_t is the predicted value of the t-th decision tree, and X is the input physical indicator feature vector including height, weight, age, taste preferences, allergens, and cardiovascular disease status.
提供机构:
浙江云澎科技有限公司
创建时间:
2024-08-20
搜集汇总
数据集介绍
特点
该数据集为基于心血管疾病患者的膳食推荐指数数据,包含1001条记录,每日更新,适用于养老机构和研究机构,用于提供定制化的饮食建议和进行营养学研究。算法基于随机森林模型,通过多棵决策树的预测结果综合得出膳食推荐指数。
以上内容由遇见数据集搜集并总结生成


