Urdu-Instruct
收藏arXiv2025-10-10 更新2025-11-19 收录
下载链接:
https://hf-mirror.com/datasets/large-traversaal/urdu-instruct
下载链接
链接失效反馈官方服务:
资源简介:
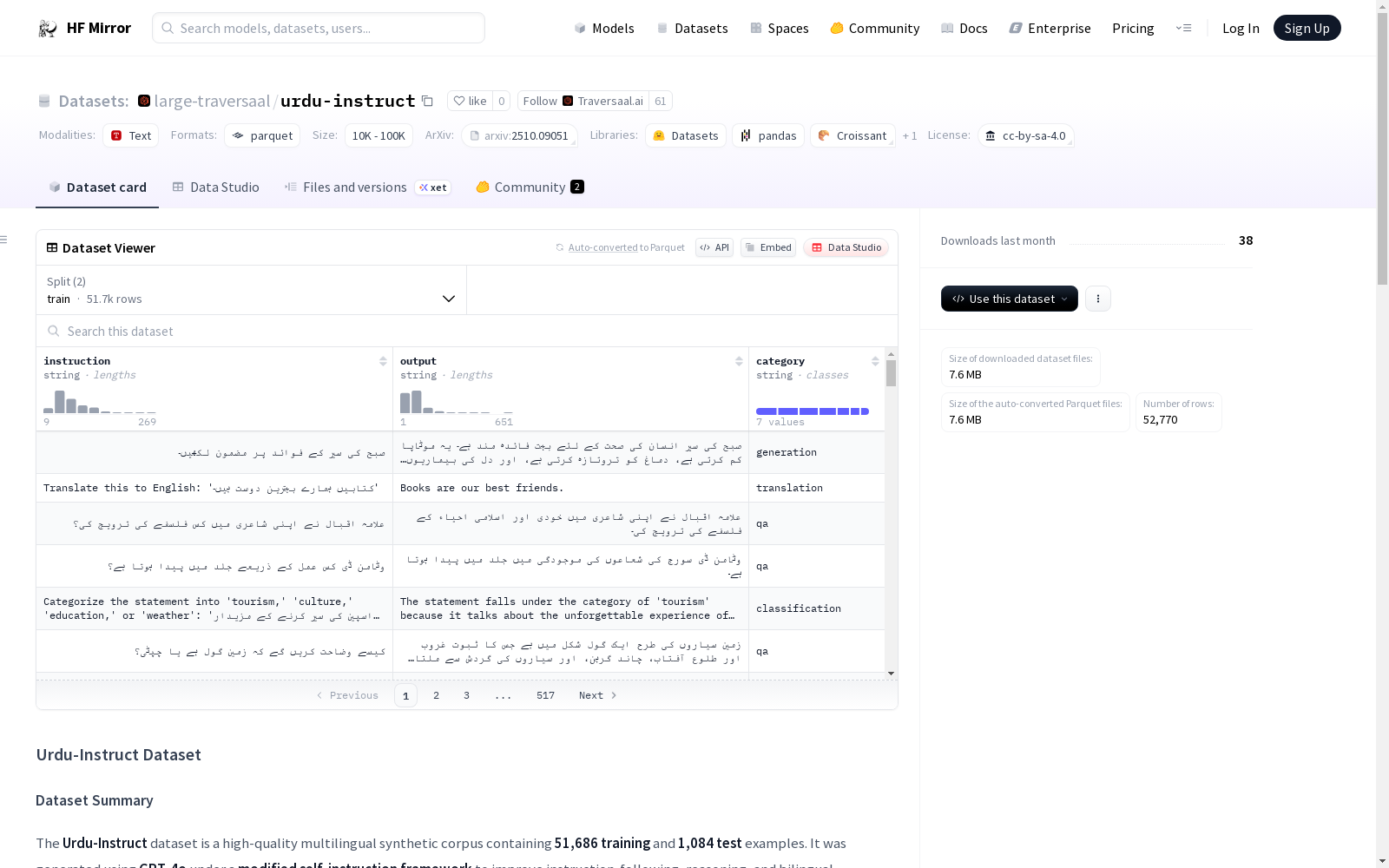
Urdu-Instruct数据集是一个高质量的多语言合成数据集,包含51686个示例,用于提高Alif-1.0-8B-Instruct模型在乌尔都语任务上的性能。该数据集使用改进的self-instruct技术生成,涵盖了文本生成、伦理和安全考虑、事实问答、逻辑推理、双语翻译、分类和情感分析等多个领域。每个任务都设计了独特的提示和种子值,以确保生成的指令具有文化多样性和任务特定性。此外,该数据集还引入了基于乌尔都语思维链的推理任务,以提高模型的逻辑推理能力。
The Urdu-Instruct dataset is a high-quality multilingual synthetic dataset containing 51,686 examples, designed to enhance the performance of the Alif-1.0-8B-Instruct model on Urdu-language tasks. This dataset is generated using an improved self-instruct technique, covering multiple domains including text generation, ethical and safety considerations, factual question answering, logical reasoning, bilingual translation, classification, and sentiment analysis. Each task is equipped with unique prompts and seed values to ensure the generated instructions possess cultural diversity and task specificity. Additionally, this dataset introduces Urdu-language Chain-of-Thought based reasoning tasks to further improve the model's logical reasoning capabilities.
提供机构:
Traversaal.ai, University of British Columbia, Texas Tech University, Institute for the Future of Education, Tecnológico de Monterrey
创建时间:
2025-10-10
搜集汇总
数据集介绍
构建方式
在低资源语言模型开发领域,Urdu-Instruct数据集通过改进的自指导技术构建而成。该方法为每类任务分配独特的提示模板和种子值,确保生成内容的多样性与文化适应性。利用GPT-4o模型批量生成指令与对应输出,通过全局任务池机制避免重复,并采用ROUGE相似度阈值进行去重过滤。最后经过人工精修环节,对乌尔都语语法、事实准确性和伦理合规性进行多维度校验,形成包含51,686个样本的高质量多语言合成数据集。
特点
该数据集涵盖文本生成、伦理安全、问答推理等七类核心任务,其特色在于融合乌尔都语本土思维链推理机制,通过结构化推理任务增强模型逻辑能力。双语翻译模块设计四种指令-输入-输出配置模式,强化乌尔都语与英语的语义关联。伦理对齐模块结合南亚文化规范进行价值观校准,生成与问答任务则采用开放式与封闭式相结合的架构,有效提升模型在低资源语言环境下的语境理解与生成连贯性。
使用方法
该数据集适用于多阶段模型训练流程,在持续预训练阶段可结合维基百科语料构建语言基础,在指令微调阶段采用斯坦福Alpaca模板进行格式化处理。实际部署时需注意采用因果语言建模损失函数,仅对输出部分计算损失值以优化训练效率。为缓解灾难性遗忘,建议配合英语重放数据集共同训练,并可通过LoRA适配器进行参数高效微调,在A100显卡环境下可实现39小时内完成全流程训练,总成本控制在百美元以内。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的模型开发长期面临资源匮乏的困境。Urdu-Instruct数据集由Traversaal.ai联合多所高校研究团队于2025年提出,旨在解决乌尔都语大语言模型训练数据稀缺的核心问题。该数据集通过改进的自指令生成技术,构建了包含5.1万余条双语指令的高质量语料,覆盖文本生成、伦理推理、知识问答等七类任务,显著提升了乌尔都语模型在文化适配性与逻辑推理方面的表现,为南亚低资源语言的包容性人工智能发展奠定了重要基础。
当前挑战
该数据集着力应对乌尔都语自然语言处理的双重挑战:在领域问题层面,需克服乌尔都语独特文字系统与复杂语法结构导致的语义理解困难,以及翻译数据中文化隐晦表达流失的问题;在构建过程中,面临高质量种子数据稀缺、多语言任务一致性维护、伦理内容过滤机制设计等难题,特别需要通过人工标注与自动过滤相结合的方式确保语言地道性与文化敏感性。
常用场景
经典使用场景
在低资源语言建模研究领域,Urdu-Instruct数据集作为乌尔都语大语言模型训练的核心资源,主要应用于多语言自然语言处理任务的指令微调环节。该数据集通过涵盖文本生成、伦理安全、问答推理、双语翻译等七大类任务,为模型提供了丰富的语言理解与生成训练样本。其独特的乌尔都语本土思维链设计,显著提升了模型在复杂语境下的逻辑推理能力,成为构建高质量乌尔都语AI系统不可或缺的基础设施。
解决学术问题
该数据集有效解决了低资源语言建模中的三大核心难题:首先突破了乌尔都语高质量训练数据稀缺的瓶颈,通过改进的自指令技术生成5万余条文化适配的样本;其次克服了传统翻译方法导致的语义失真问题,保留了语言的文化特质与表达习惯;最后通过伦理对齐机制,建立了符合区域文化规范的安全屏障。这些突破为低资源语言的包容性AI发展提供了可复现的技术路径。
衍生相关工作
该数据集的创新方法论催生了系列延伸研究,其改进的自指令技术被拓展至印地语、孟加拉语等南亚低资源语言建模。基于文化适配的数据生成框架启发了跨语言伦理对齐标准的设计,而构建的乌尔都语评估集则为多语言模型能力测评建立了新基准。这些衍生工作共同推动了包容性人工智能在语言学多样性方面的实践探索。
以上内容由遇见数据集搜集并总结生成


