KorT
收藏github2025-04-20 更新2025-04-21 收录
下载链接:
https://github.com/deveworld/KorT
下载链接
链接失效反馈官方服务:
资源简介:
KorT是一个利用大规模语言模型(LLM)定量评估翻译质量的基准数据集。它包含多种难以翻译的句子,涵盖多个领域和语言现象(如歧义、惯用表达、文化引用等)。该数据集旨在建立一个比传统自动评估指标更可靠、可扩展且精细的评估体系,以促进高质量多语言机器翻译技术的发展。
KorT is a benchmark dataset for quantitatively evaluating translation quality using Large Language Models (LLMs). It includes a range of hard-to-translate sentences, covering multiple domains and linguistic phenomena such as ambiguity, idiomatic expressions, cultural references, etc. This dataset aims to establish a more reliable, scalable, and fine-grained evaluation framework than traditional automatic evaluation metrics, thereby advancing the development of high-quality multilingual machine translation technologies.
创建时间:
2025-04-18
原始信息汇总
KorT数据集概述
数据集简介
- 名称:Korean Translation Benchmark (KorT)
- 类型:机器翻译评估基准
- 核心方法:采用LLM-as-a-judge范式进行翻译质量评估
核心特点
-
评估体系:
- 针对韩国语-多语言翻译能力设计
- 覆盖多种语言现象(歧义、惯用语、文化参照等)
- 包含多个领域的难翻译句子
-
技术优势:
- 相比BLEU等传统指标更能捕捉语言细微差异
- 比人工评估更高效
- 追求与人类判断高度相关的评估结果
技术实现
- 评估模型:claude-3-7-sonnet-20250219 (Reasoning)
- 功能组件:
- 翻译生成模块
- 批量评估模块
- 排行榜系统
使用方式
-
安装: bash git clone https://github.com/deveworld/kort cd kort pip install .
-
主要功能:
- 翻译生成:支持多种翻译引擎
- 质量评估:支持单次和批量评估模式
- 排行榜查看:支持Web和文本两种展示方式
相关资源
- 在线排行榜:https://kort.worldsw.dev
- 问题反馈:通过GitHub Issue提交
- 贡献方式:接受Pull Request
搜集汇总
数据集介绍
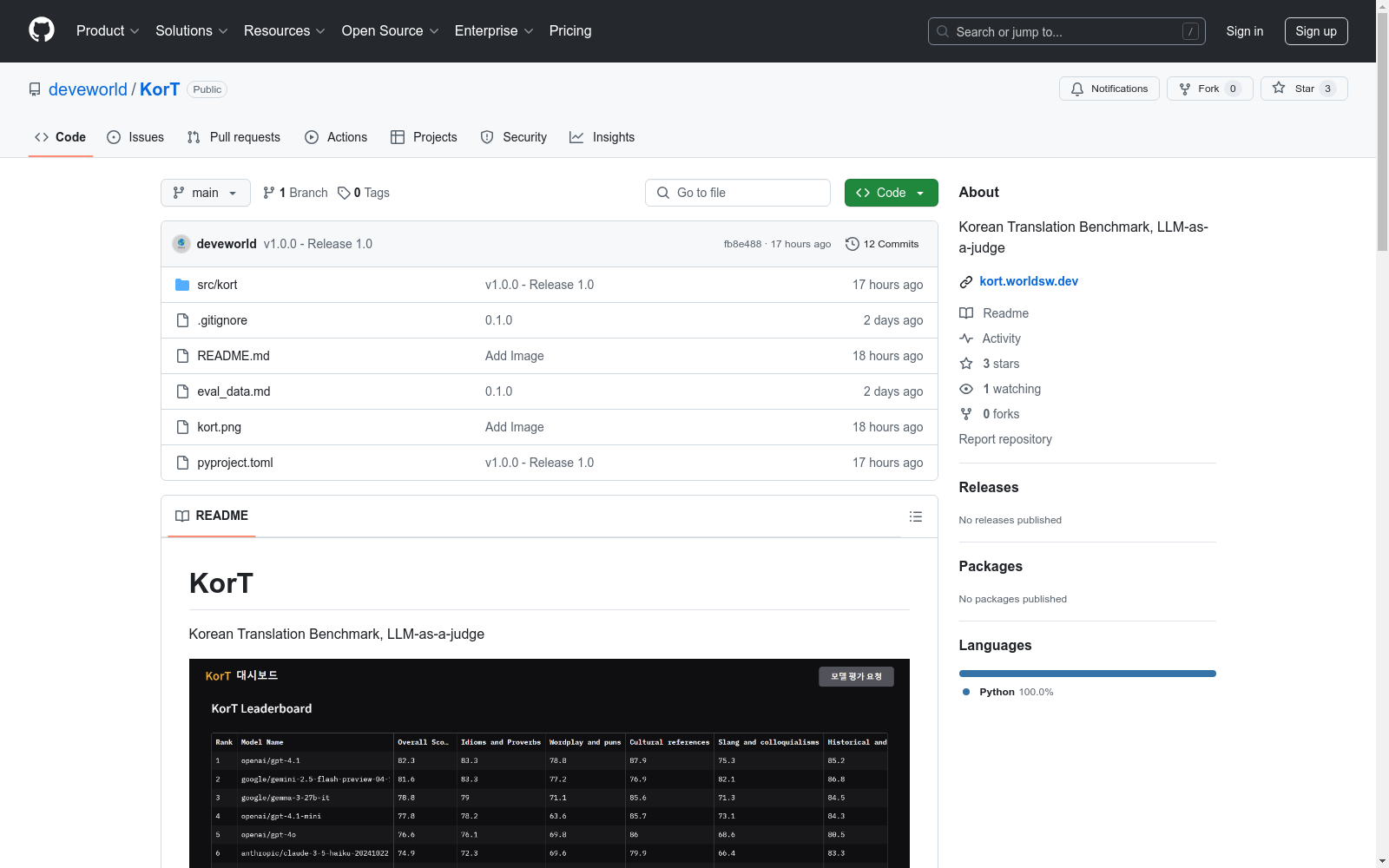
构建方式
在机器翻译评估领域,KorT数据集采用创新性的构建方法,通过精心设计涵盖多领域和复杂语言现象的语料库。该数据集包含具有挑战性的韩语-多语言翻译例句,特别关注歧义表达、文化特定术语和惯用短语等难点。构建过程中严格筛选源文本,确保覆盖不同文体和语境,并采用大语言模型作为评判工具,建立了一套量化评估体系。
特点
KorT数据集展现出显著的专业特性,其核心优势在于将传统自动评估指标与LLM-as-a-judge范式相结合。该数据集特别注重韩语特有的语言结构和文化内涵,包含丰富的语言现象测试案例。通过标准化评估流程和公开排行榜机制,为研究者提供了可比较、可复现的评估基准,同时解决了人工评估成本高昂的问题。
使用方法
该数据集提供完整的工具链支持,用户可通过命令行接口完成安装、翻译生成和质量评估全流程。系统支持多种主流翻译API的集成,并允许用户自定义评估参数。批量评估功能显著提升了大规模测试效率,而内置的排行榜系统则便于研究者直观比较不同模型的性能表现。所有操作均通过模块化脚本实现,确保了使用过程的灵活性和可扩展性。
背景与挑战
背景概述
KorT数据集是由开发者worldsw.dev团队构建的韩国语-多语言翻译评估基准,旨在解决机器翻译领域长期存在的评估难题。该数据集创新性地采用大语言模型作为评判员(LLM-as-a-judge)的范式,通过构建包含复杂语言现象的测试集,包括歧义表达、文化特定引用和惯用语等挑战性样本,为韩国语翻译质量评估提供了新的方法论框架。其核心价值在于突破传统BLEU等自动化指标的局限性,建立与人类判断高度相关且可扩展的评估体系,对推动韩语相关的多语言机器翻译技术发展具有重要意义。
当前挑战
KorT面临双重技术挑战:在领域问题层面,需要精准捕捉韩语特有的文化负载词、敬语体系和高语境依赖特性,这些要素在传统基于n-gram匹配的评估指标中难以量化;在构建过程中,既要确保测试集涵盖语法复杂性、语义模糊性等维度,又需解决大语言模型评估时存在的偏见放大、提示词敏感性等新兴问题。此外,建立跨语言对齐的评估标准,平衡评估效率与结果可靠性之间的张力,也是该数据集持续优化的关键方向。
常用场景
经典使用场景
在机器翻译领域,KorT数据集作为一项创新的评估基准,主要用于衡量大语言模型在韩语-多语种翻译任务中的表现。该数据集通过精心设计的评估框架,覆盖了包括歧义解析、文化特定表达和惯用语处理等复杂语言现象,为研究者提供了一个标准化的测试平台。其独特之处在于采用LLM-as-a-judge范式,利用先进语言模型的深层语义理解能力,对翻译质量进行更接近人类专家水平的自动化评估。
衍生相关工作
围绕KorT数据集已衍生出多项重要研究。部分学者基于其评估框架开发了针对东亚语言的扩展版本,如日语和中文的翻译基准。另有研究团队受其启发,提出了融合文化适应性的新型评估指标。在方法论层面,KorT的LLM-as-a-judge范式被广泛应用于语音识别、文本摘要等自然语言处理任务的评估体系构建,推动了自动化评估技术的整体发展。
数据集最近研究
最新研究方向
在机器翻译领域,KorT数据集的推出标志着基于大语言模型(LLM)的翻译质量评估进入新阶段。该数据集聚焦于韩语-多语种翻译场景,通过构建涵盖歧义表达、文化专有项等复杂语言现象的测试集,创新性地采用LLM-as-a-judge范式进行自动化评估。当前研究热点集中在如何优化评估提示词工程以提升LLM评判与人类评价的相关性,以及探索多模态大模型在跨文化翻译评估中的应用潜力。该基准测试通过公开排行榜机制,为比较不同MT系统和LLM的韩语处理能力提供了标准化平台,特别在解决文化负载词和语境依赖性翻译等传统难题方面具有重要参考价值。
以上内容由遇见数据集搜集并总结生成


