ears-reverb-dataset
收藏Hugging Face2025-08-25 更新2025-08-26 收录
下载链接:
https://huggingface.co/datasets/Amayas/ears-reverb-dataset
下载链接
链接失效反馈官方服务:
资源简介:
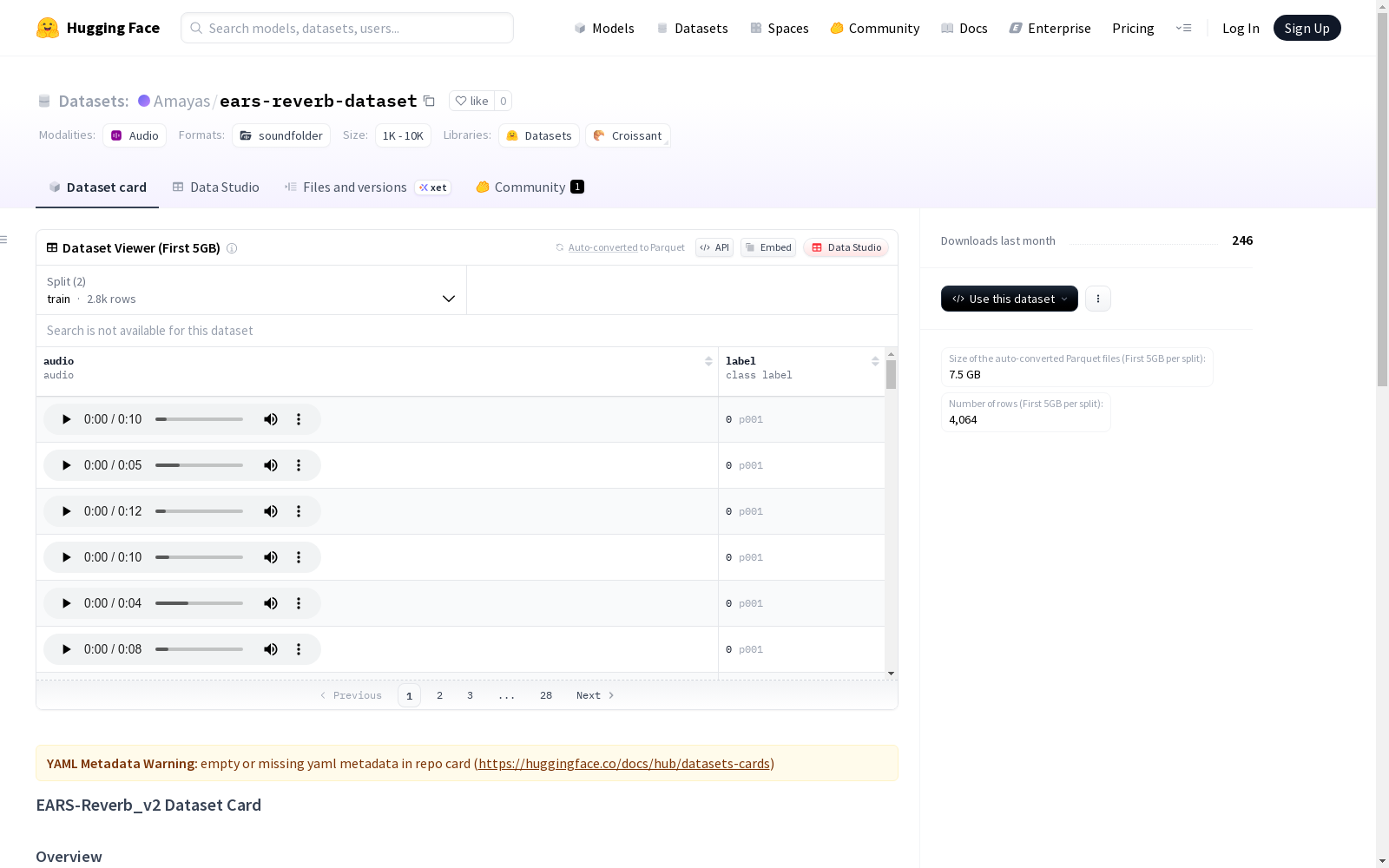
EARS-Reverb_v2是一个大规模的数据集,专为语音增强和去混响研究设计。该数据集包含了由ears_benchmark仓库代码生成的混响语音数据,用于训练和验证目的,并未提供测试集。
EARS-Reverb_v2 is a large-scale dataset specifically designed for speech enhancement and dereverberation research. It contains reverberant speech data generated by the code from the ears_benchmark repository, intended for training and validation purposes, and no test set is provided.
创建时间:
2025-08-25
原始信息汇总
EARS-Reverb_v2 数据集概述
数据集简介
EARS-Reverb_v2 是一个大规模数据集,专为语音增强和去混响研究设计。该数据集包含混响语音数据,由 ears_benchmark 代码库生成,适用于训练和验证目的,不包含测试集。
数据集结构
- 训练数据:位于 train/ 目录
- 验证数据:位于 valid/ 目录
- 训练元数据:train.csv 文件
- 验证元数据:valid.csv 文件
注:本版本未提供测试集。
数据生成
数据集使用以下代码库生成: https://github.com/sp-uhh/ears_benchmark
如需复现或扩展数据集,请参考该代码库的说明和代码。
参考文献
使用本数据集时请引用:
@inproceedings{richter2024ears, title={{EARS}: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation}, author={Richter, Julius and Wu, Yi-Chiao and Krenn, Steven and Welker, Simon and Lay, Bunlong and Watanabe, Shinjii and Richard, Alexander and Gerkmann, Timo}, booktitle={ISCA Interspeech}, year={2024} }
注意事项
- 仅提供训练和验证分割
- 更多信息请访问:https://github.com/sp-uhh/ears_benchmark
搜集汇总
数据集介绍
构建方式
在语音增强与去混响研究领域,数据质量对模型性能具有决定性影响。EARS-Reverb_v2数据集通过开源代码库ears_benchmark生成,采用算法模拟真实环境中的声学反射效应,构建大规模混浊语音样本。其训练集与验证集均经过严格的声学参数控制,确保混响时间与房间脉冲响应的多样性,为模型提供丰富的学习素材。
特点
该数据集突出表现为全波段语音覆盖与高保真混响模拟,所有样本均源自专业声学仿真算法,具备物理意义上的真实性。数据划分为训练集与验证集,配套元数据文件详细记录每条语音的声学属性和生成参数,支持精细化实验设计。值得注意的是,数据集专注于训练与验证场景,未包含独立测试集,研究者需自行划分评估数据。
使用方法
使用者可通过加载标准CSV元数据文件快速访问语音样本与对应标签,集成至主流深度学习框架进行端到端训练。建议遵循原论文中的数据预处理流程,包括采样率统一与幅度归一化操作。由于数据集本身不包含测试集,需采用交叉验证或额外收集真实数据以评估模型泛化能力,具体实现可参考关联GitHub仓库的代码规范。
背景与挑战
背景概述
语音增强与去混响研究领域长期受限于高质量数据资源的匮乏,EARS-Reverb_v2数据集由汉堡大学学术团队于2024年构建,旨在为全频段语音信号处理提供基准支持。该数据集基于开源算法框架生成混响语音样本,通过严谨的声学仿真技术模拟真实环境中的声波反射特性,其核心价值在于为深度学习模型提供大规模训练验证数据,推动鲁棒性语音处理系统的发展。
当前挑战
该数据集致力于解决真实环境中语音信号因混响效应导致的清晰度下降问题,其构建挑战主要体现在声学仿真参数的精确控制与语音质量一致性的平衡。具体而言,需要模拟不同空间几何形态下的声波传播物理特性,同时确保生成数据与原始纯净语音的时频特征对齐。此外,数据规模与计算资源之间的优化配置也是关键挑战,需在保持声学合理性的前提下实现高效批量生成。
常用场景
经典使用场景
在语音信号处理领域,EARS-Reverb_v2数据集主要应用于语音增强和去混响算法的训练与验证。该数据集通过模拟真实环境中的混响效应,为研究人员提供了大量高质量的带混响语音样本,用于开发和优化深度学习模型,以提升语音信号的清晰度和可懂度。
衍生相关工作
基于EARS-Reverb_v2数据集,衍生出了一系列经典研究工作,包括基于深度学习的去混响网络架构、端到端的语音增强模型以及多模态语音处理系统。这些工作不仅推动了数据集本身的完善,还为语音处理领域的算法创新提供了重要支撑,促进了学术与工业界的合作。
数据集最近研究
最新研究方向
在语音信号处理领域,混响消除一直是提升语音清晰度的核心挑战。EARS-Reverb_v2数据集凭借其大规模全频带混响语音数据,为深度学习方法在语音增强方向的研究提供了重要支撑。当前研究聚焦于结合神经网络的端到端去混响模型,利用该数据集模拟真实声学环境中的复杂反射特性,显著提升了模型在嘈杂环境下的泛化能力。随着智能助手和远程会议系统的普及,去混响技术已成为人机交互系统的关键技术之一,该数据集的推出不仅加速了去混响算法的迭代,更为语音前端处理技术的实际落地提供了可靠的数据基础。
以上内容由遇见数据集搜集并总结生成


