agentsea/wave-ui-25k
收藏Hugging Face2024-07-03 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/agentsea/wave-ui-25k
下载链接
链接失效反馈官方服务:
资源简介:
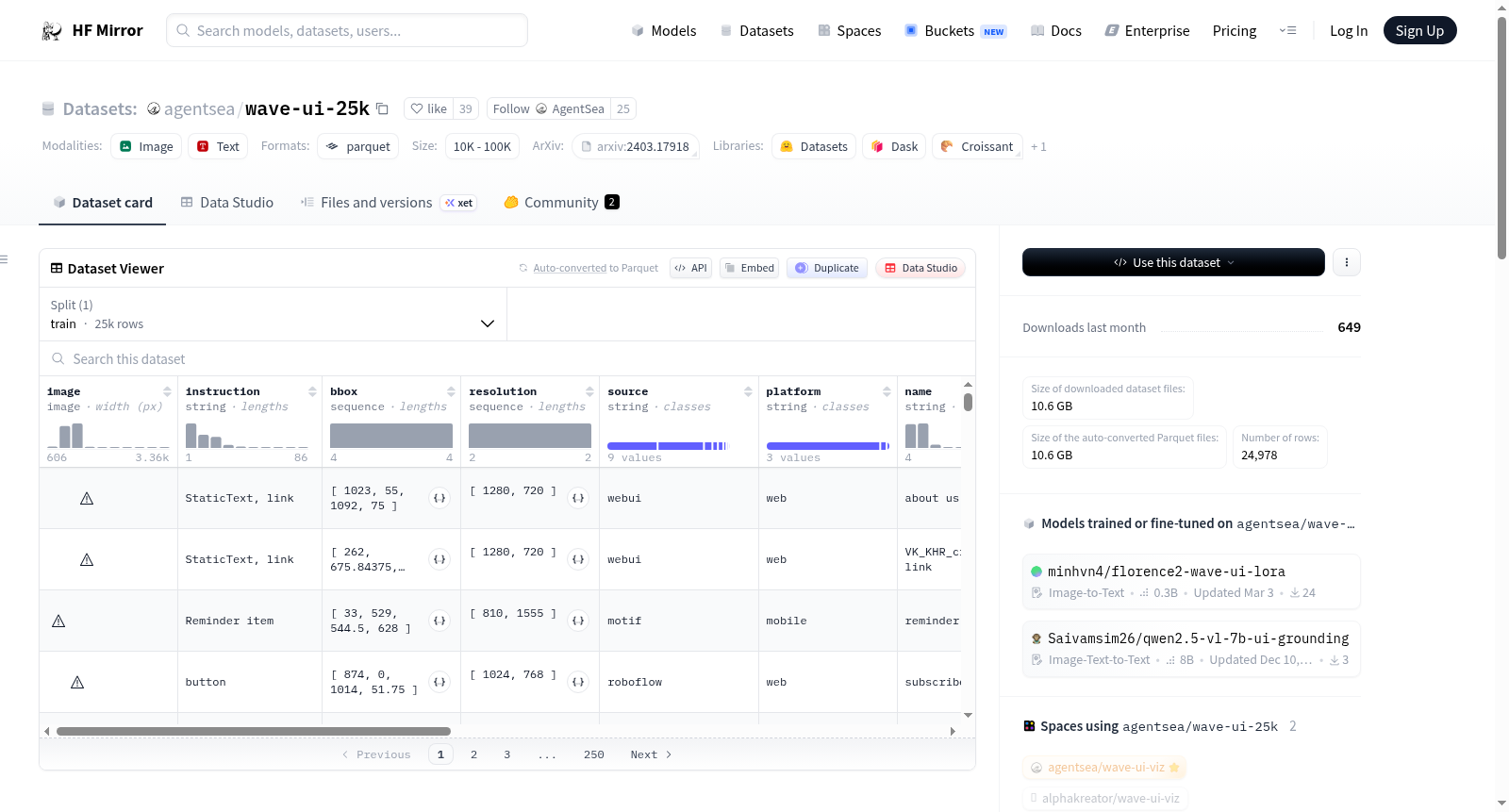
WaveUI-25k数据集包含25,000个标记的UI元素示例,这些示例是从WebUI、RoboFlow和GroundUI-18K三个来源预处理和筛选得到的。数据集不仅保留了原始数据集的字段,还通过注释过程添加了多个新字段,如元素名称、描述、类型、OCR文本、语言、目的和预期行为等。数据集的总下载大小为10,577,935,056字节,总数据集大小为10,884,587,492.75字节,训练集包含24,978个示例。
The WaveUI-25k dataset contains 25k examples of labeled UI elements, which is a subset of a collection of approximately 80k preprocessed examples assembled from the sources of WebUI, RoboFlow, and GroundUI-18K. The dataset has been preprocessed to match schemas and filter out unwanted examples such as duplicates, overlaps, and low-quality data points. Additionally, many text elements that were not within the main scope of this work were also filtered out. The dataset includes the original fields from the source datasets as well as additional fields obtained from the annotation process, such as name, description, type, OCR, language, purpose, and expectation.
提供机构:
agentsea
搜集汇总
数据集介绍
构建方式
在用户界面理解的研究领域,构建高质量标注数据集是推动模型性能提升的关键。WaveUI-25k数据集通过整合多个权威来源构建而成,其原始素材取自WebUI、RoboFlow的网站截图以及GroundUI-18K等公开数据集。构建过程中,研究团队对约八万个初始样本进行了严格的预处理与模式对齐,旨在统一数据模式并剔除冗余及低质量数据点,例如重复、重叠的界面元素。同时,为聚焦核心研究目标,数据集中过滤了大量非核心的文本元素,最终精炼出两万四千余个标注样本,确保了数据的一致性与纯净度。
使用方法
对于致力于视觉语言模型或智能体交互的研究者而言,WaveUI-25k数据集提供了直接的应用路径。用户可通过Hugging Face平台便捷加载该数据集,利用其标准化的特征字段进行模型训练与评估。数据集适用于界面元素检测、功能描述生成、交互意图预测等多种下游任务。为辅助分析与可视化,官方提供了专用的演示空间,便于研究者直观审视数据样本。在实际使用中,建议结合原始论文引用的学术背景,深入理解各数据源的特质,以充分发挥该数据集在提升模型界面语义理解能力方面的潜力。
背景与挑战
背景概述
在人工智能与交互设计交叉领域,用户界面(UI)的视觉理解已成为推动智能体与数字环境无缝交互的核心研究议题。WaveUI-25k数据集由agentsea团队于近期构建,其整合了WebUI、RoboFlow及GroundUI-18K等多个来源的标注数据,旨在为UI元素的精细化识别与语义理解提供高质量基准。该数据集聚焦于解析界面元素的视觉特征、功能属性及交互意图,其诞生响应了自动化UI测试、无障碍访问以及通用虚拟代理开发等前沿需求,为计算机视觉与人机交互的融合研究注入了新的数据动力。
当前挑战
WaveUI-25k数据集致力于解决UI元素的多模态理解问题,其核心挑战在于如何准确捕捉界面中视觉元素与功能语义之间的复杂映射关系,例如从图像中推断按钮的点击预期或识别图标的具体用途。在构建过程中,研究团队面临数据异构性整合的难题,需将不同来源的标注模式统一为一致的模式,并有效过滤重复、重叠及低质量样本。此外,如何平衡文本与非文本元素的代表性,避免因过度筛选而损失界面结构的完整性,亦是数据集构建中的关键挑战。
常用场景
经典使用场景
在人机交互与界面设计领域,WaveUI-25k数据集为视觉界面理解任务提供了丰富的标注资源。该数据集整合了来自多个来源的界面元素,通过精细的预处理流程确保了数据质量。其经典使用场景集中在训练和评估视觉界面理解模型,特别是针对用户界面元素的检测、分类与语义解析。研究者可利用该数据集构建能够自动识别按钮、输入框、导航栏等界面组件的模型,从而推动界面自动化分析技术的发展。
解决学术问题
该数据集有效解决了界面理解研究中数据稀缺与标注不一致的学术难题。通过融合WebUI、RoboFlow和GroundUI-18K等异构数据源,并统一其模式与质量标准,它为界面元素的细粒度识别与功能理解提供了可靠基准。其意义在于促进了跨平台界面语义解析的研究,使得模型能够更准确地理解界面元素的视觉特征、文本内容及交互意图,为构建智能界面代理奠定了数据基础。
实际应用
在实际应用层面,WaveUI-25k数据集支撑了自动化界面测试与无障碍访问技术的开发。基于该数据集训练的模型可应用于网页与移动应用的界面自动化遍历,辅助进行功能测试与兼容性检查。同时,这些模型能够识别界面元素的目的与预期行为,为视障用户提供更精准的屏幕阅读支持,提升数字产品的可访问性,体现了人机交互研究向普惠性设计延伸的价值。
数据集最近研究
最新研究方向
在用户界面智能理解领域,WaveUI-25k数据集正推动着多模态界面元素解析的前沿探索。该数据集整合了丰富的UI元素视觉与语义标注,为构建能够深度理解界面功能与交互意图的智能体提供了关键训练资源。当前研究热点聚焦于利用此类结构化数据,训练端到端的视觉语言模型,以实现对UI元素的精准定位、功能推理与操作预测,从而赋能自动化测试、无障碍访问及智能助手等实际应用场景。其高质量的多源标注信息,特别是对元素目的与交互期望的描述,正成为提升模型在开放环境下的泛化与推理能力的重要基石,对推动人机交互向更自然、高效的方向演进具有显著意义。
以上内容由遇见数据集搜集并总结生成


