bilingual-tokenizer-training-data
收藏Hugging Face2026-02-10 更新2026-02-11 收录
下载链接:
https://huggingface.co/datasets/catherinearnett/bilingual-tokenizer-training-data
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个多语言文本集合,包含多种语言和文字组合的配置(如拉丁字母书写的南非荷兰语、埃塞俄比亚字母书写的阿姆哈拉语等)。每个配置包含一个字符串类型的'text'字段,所有数据均为'train'分割。数据集提供了每个语言子集(通常每个语言有3个子集)的精确字节大小、样本数量、下载大小和数据集大小。技术规格完整,但未说明数据收集目的、方法或内容特征。
This dataset is a multilingual text corpus comprising configurations with diverse language and writing system combinations, such as Afrikaans written in Latin script and Amharic written in Ethiopian script, among others. Each configuration contains a 'text' field of string type, and all data belongs to the 'train' split. The dataset provides precise byte size, sample count, download size, and dataset size for each language subset (typically 3 subsets per language). While its technical specifications are complete, it does not specify the data collection purpose, methods, or content characteristics.
创建时间:
2026-02-10
原始信息汇总
数据集概述
基本信息
- 数据集名称:bilingual-tokenizer-training-data
- 托管地址:https://huggingface.co/datasets/catherinearnett/bilingual-tokenizer-training-data
数据集结构
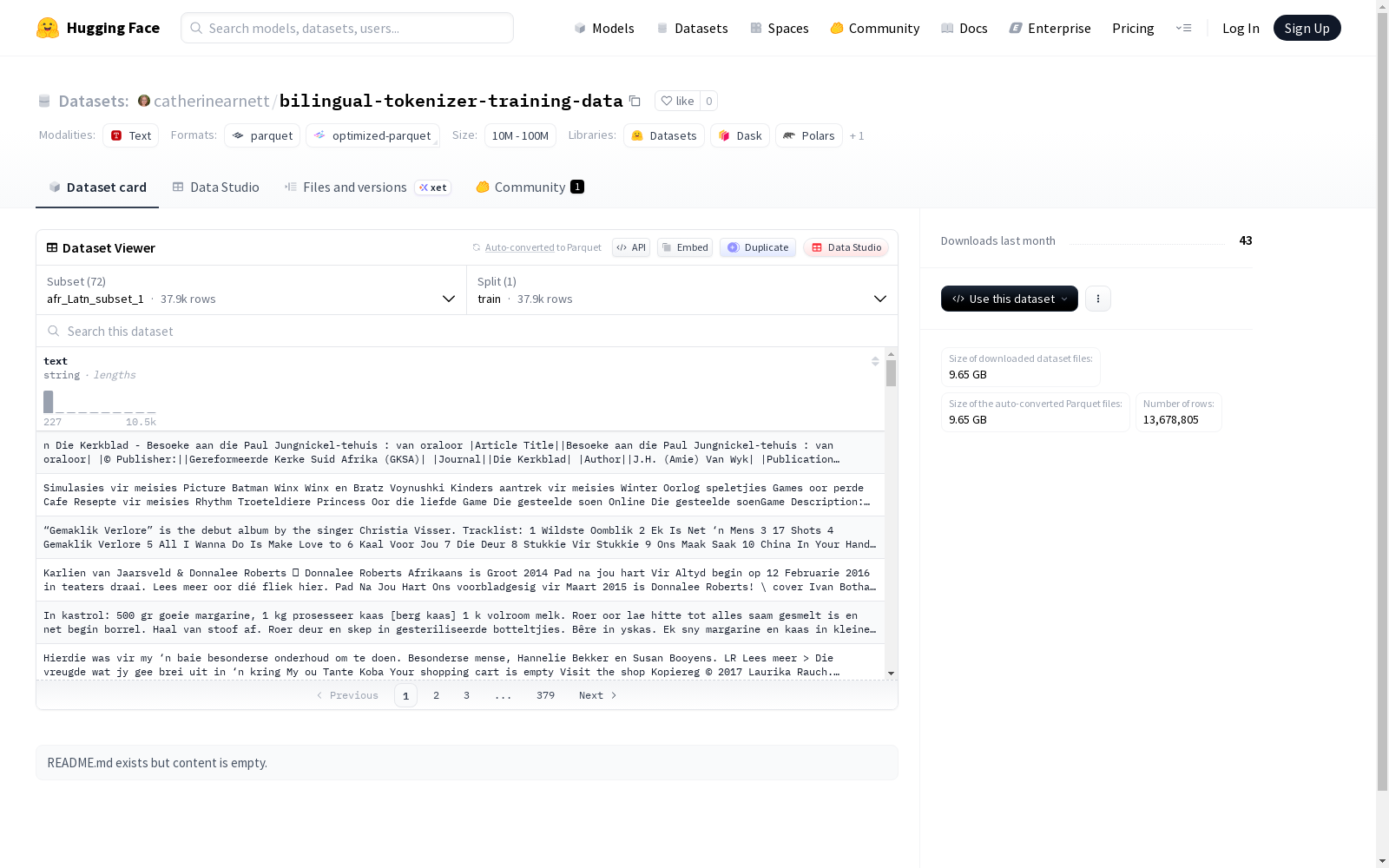
该数据集包含多个配置(config),每个配置对应一种特定的语言和文字组合,并进一步划分为多个子集。所有配置均仅包含训练集(train split)。
配置列表与数据概览
每个配置的名称遵循“语言代码_文字代码_subset_编号”的格式。以下为部分配置的详细信息:
| 配置名称 | 特征 | 训练集样本数 | 训练集大小(字节) | 下载大小(字节) | 数据集大小(字节) |
|---|---|---|---|---|---|
| afr_Latn_subset_1 | text (string) | 37,879 | 21,728,800 | 15,182,645 | 21,728,800 |
| afr_Latn_subset_2 | text (string) | 37,879 | 21,728,800 | 15,165,029 | 21,728,800 |
| afr_Latn_subset_3 | text (string) | 37,879 | 21,728,800 | 15,207,266 | 21,728,800 |
| als_Latn_subset_1 | text (string) | 137,358 | 95,303,572 | 65,785,087 | 95,303,572 |
| als_Latn_subset_2 | text (string) | 137,358 | 95,303,572 | 65,785,013 | 95,303,572 |
| als_Latn_subset_3 | text (string) | 137,358 | 95,303,572 | 65,790,996 | 95,303,572 |
| amh_Ethi_subset_1 | text (string) | 136,170 | 524,702,448 | 258,345,245 | 524,702,448 |
| amh_Ethi_subset_2 | text (string) | 136,054 | 524,700,994 | 258,271,490 | 524,700,994 |
| amh_Ethi_subset_3 | text (string) | 136,274 | 524,698,614 | 258,327,435 | 524,698,614 |
| arb_Arab_subset_1 | text (string) | 281,456 | 525,132,987 | 266,095,936 | 525,132,987 |
| arb_Arab_subset_2 | text (string) | 282,461 | 525,135,888 | 266,204,808 | 525,135,888 |
| arb_Arab_subset_3 | text (string) | 284,375 | 525,143,702 | 266,651,753 | 525,143,702 |
| ars_Arab_subset_1 | text (string) | 44,276 | 132,099,192 | 68,294,504 | 132,099,192 |
| ars_Arab_subset_2 | text (string) | 44,276 | 132,099,192 | 68,284,010 | 132,099,192 |
| ars_Arab_subset_3 | text (string) | 44,276 | 132,099,192 | 68,281,443 | 132,099,192 |
| ary_Arab_subset_1 | text (string) | 240,727 | 391,503,999 | 198,879,611 | 391,503,999 |
| ary_Arab_subset_2 | text (string) | 240,727 | 391,503,999 | 198,884,712 | 391,503,999 |
| ary_Arab_subset_3 | text (string) | 240,727 | 391,503,999 | 198,900,799 | 391,503,999 |
| arz_Arab_subset_1 | text (string) | 52,893 | 119,379,319 | 61,943,643 | 119,379,319 |
| arz_Arab_subset_2 | text (string) | 52,893 | 119,379,319 | 61,951,556 | 119,379,319 |
| arz_Arab_subset_3 | text (string) | 52,893 | 119,379,319 | 61,946,508 | 119,379,319 |
| asm_Beng_subset_1 | text (string) | 11,694 | 25,063,726 | 10,100,413 | 25,063,726 |
| asm_Beng_subset_2 | text (string) | 11,694 | 25,063,726 | 10,099,669 | 25,063,726 |
| asm_Beng_subset_3 | text (string) | 11,694 | 25,063,726 | 10,098,749 | 25,063,726 |
| azj_Latn_subset_1 | text (string) | 40,802 | 33,980,534 | 22,333,006 | 33,980,534 |
| azj_Latn_subset_2 | text (string) | 40,802 | 33,980,534 | 22,309,017 | 33,980,534 |
| azj_Latn_subset_3 | text (string) | 40,802 | 33,980,534 | 22,320,385 | 33,980,534 |
| bel_Cyrl_subset_1 | text (string) | 47,085 | 62,667,440 | 35,153,120 | 62,667,440 |
| bel_Cyrl_subset_2 | text (string) | 47,085 | 62,667,440 | 35,150,134 | 62,667,440 |
| bel_Cyrl_subset_3 | text (string) | 47,085 | 62,667,440 | 35,151,604 | 62,667,440 |
| ben_Beng_subset_1 | text (string) | 227,996 | 524,972,642 | 206,313,646 | 524,972,642 |
| ben_Beng_subset_2 | text (string) | 227,663 | 524,971,696 | 206,244,476 | 524,971,696 |
| ben_Beng_subset_3 | text (string) | 227,458 | 524,972,806 | 206,253,888 | 524,972,806 |
| bod_Tibt_subset_1 | text (string) | 2,972 | 8,617,539 | 2,940,370 | 8,617,539 |
| bod_Tibt_subset_2 | text (string) | 2,972 | 8,617,539 | 2,941,826 | 8,617,539 |
| bod_Tibt_subset_3 | text (string) | 2,972 | 8,617,539 | 2,940,393 | 8,617,539 |
| bos_Latn_subset_1 | text (string) | 104,003 | 62,777,730 | 43,723,433 | 62,777,730 |
| bos_Latn_subset_2 | text (string) | 104,003 | 62,777,730 | 43,664,311 | 62,777,730 |
| bos_Latn_subset_3 | text (string) | 104,003 | 62,777,730 | 43,701,689 | 62,777,730 |
| bul_Cyrl_subset_1 | text (string) | 379,052 | 360,852,190 | 195,352,287 | 360,852,190 |
| bul_Cyrl_subset_2 | text (string) | 379,052 | 360,852,190 | 195,328,660 | 360,852,190 |
| bul_Cyrl_subset_3 | text (string) | 379,052 | 360,852,190 | 195,353,831 | 360,852,190 |
| cat_Latn_subset_1 | text (string) | 126,052 | 55,326,034 | 39,083,607 | 55,326,034 |
| cat_Latn_subset_2 | text (string) | 126,052 | 55,326,034 | 39,084,943 | 55,326,034 |
| cat_Latn_subset_3 | text (string) | 126,052 | 55,326,034 | 39,112,003 | 55,326,034 |
| ces_Latn_subset_1 | text (string) | 683,566 | 526,339,120 | 374,509,392 | 526,339,120 |
| ces_Latn_subset_2 | text (string) | 684,527 | 526,341,980 | 374,986,019 | 526,341,980 |
| ces_Latn_subset_3 | text (string) | 684,352 | 526,342,324 | 375,070,972 | 526,342,324 |
| ckb_Arab_subset_1 | text (string) | 104,704 | 304,468,900 | 143,965,792 | 304,468,900 |
| ckb_Arab_subset_2 | text (string) | 104,704 | 304,468,900 | 143,977,298 | 304,468,900 |
| ckb_Arab_subset_3 | text (string) | 104,704 | 304,468,900 | 143,962,234 | 304,468,900 |
| cym_Latn_subset_1 | text (string) | 7,029 | 3,670,647 | 2,653,159 | 3,670,647 |
| cym_Latn_subset_2 | text (string) | 7,029 | 3,670,647 | 2,654,991 | 3,670,647 |
| cym_Latn_subset_3 | text (string) | 7,029 | 3,670,647 | 2,653,936 | 3,670,647 |
| dan_Latn_subset_1 | text (string) | 878,305 | 526,923,491 | 361,711,615 | 526,923,491 |
| dan_Latn_subset_2 | text (string) | 878,659 | 526,924,316 | 361,706,965 | 526,924,316 |
| dan_Latn_subset_3 | text (string) | 878,584 | 526,923,972 | 361,717,198 | 526,923,972 |
| fin_Latn_subset_1 | text (string) | 334,783 | 525,292,683 | 327,029,549 | 525,292,683 |
| fin_Latn_subset_2 | text (string) | 334,467 | 525,303,524 | 327,164,399 | 525,303,524 |
| fin_Latn_subset_3 | text (string) | 333,918 | 525,299,537 | 327,052,121 | 525,299,537 |
| heb_Hebr_subset_1 | text (string) | 248,742 | 525,036,517 | 274,530,009 | 525,036,517 |
| heb_Hebr_subset_2 | text (string) | 249,158 | 525,035,813 | 274,838,231 | 525,035,813 |
| heb_Hebr_subset_3 | text (string) | 248,486 | 525,034,448 | 274,763,651 | 525,034,448 |
| hin_Deva_subset_1 | text (string) | 275,630 | 406,721,991 | 169,710,457 | 406,721,991 |
| hin_Deva_subset_2 | text (string) | 275,630 | 406,721,991 | 169,708,314 | 406,721,991 |
| hin_Deva_subset_3 | text (string) | 275,630 | 406,721,991 | 169,716,740 | 406,721,991 |
| hrv_Latn_subset_1 | text (string) | 39,492 | 27,918,976 | 19,676,113 | 27,918,976 |
| hrv_Latn_subset_2 | text (string) | 39,492 | 27,918,976 | 19,770,877 | 27,918,976 |
| hrv_Latn_subset_3 | text (string) | 39,492 | 27,918,976 | 19,745,976 | 27,918,976 |
| isl_Latn_subset_1 | text (string) | 115,469 | 74,066,640 | 51,306,859 | 74,066,640 |
| isl_Latn_subset_2 | text (string) | 115,469 | 74,066,640 | 51,323,440 | 74,066,640 |
| isl_Latn_subset_3 | text (string) | 115,469 | 74,066,640 | 51,321,989 | 74,066,640 |
数据特征
- 核心特征:所有配置均包含一个名为“text”的字段,其数据类型为字符串(string)。
- 数据格式:数据文件路径格式为
{config_name}/train-*,例如afr_Latn_subset_1/train-*。
语言与文字覆盖
数据集涵盖多种语言及其对应的文字系统,例如:
- 拉丁文字:afr(南非荷兰语)、als(阿勒曼尼语)、bos(波斯尼亚语)、cat(加泰罗尼亚语)、ces(捷克语)、cym(威尔士语)、dan(丹麦语)、fin(芬兰语)、hrv(克罗地亚语)、isl(冰岛语)等。
- 阿拉伯文字:arb(标准阿拉伯语)、ars(纳吉迪阿拉伯语)、ary(摩洛哥阿拉伯语)、arz(埃及阿拉伯语)、ckb(中库尔德语)等。
- 其他文字:amh_Ethi(阿姆哈拉语-埃塞俄比亚文字)、ben_Beng(孟加拉语-孟加拉文字)、hin_Deva(印地语-天城文)、bod_Tibt(藏语-藏文)等。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建高质量的双语分词器训练数据是提升模型跨语言理解能力的关键。该数据集通过系统化地收集多语言文本,涵盖了从南非荷兰语到威尔士语等多种语言,每种语言均以特定脚本标注,并细分为多个子集以优化数据管理。数据集的构建过程注重原始文本的多样性与代表性,确保覆盖不同语言的实际使用场景,为分词器的训练提供了丰富的语言样本。
特点
该数据集以其广泛的语言覆盖和精细的结构化设计而著称,囊括了拉丁字母、阿拉伯字母、梵文字母等多种书写系统,体现了语言多样性。每个语言配置均包含三个独立的子集,不仅便于数据的分块处理与验证,还能有效支持模型训练的稳定性与泛化能力。数据规模从数万到数十万条文本不等,确保了训练资源的充足性与平衡性。
使用方法
使用该数据集时,研究人员可通过HuggingFace平台直接加载特定语言配置,例如选择'afr_Latn_subset_1'来获取南非荷兰语的训练文本。数据集以标准化的文本字段呈现,适用于训练双语或多语言分词器,用户可结合机器学习框架进行预处理与模型训练。其模块化结构允许灵活的数据选择与整合,支持跨语言自然语言处理任务的实验与优化。
背景与挑战
背景概述
在自然语言处理领域,多语言预训练模型的兴起催生了对于高质量双语分词器训练数据的迫切需求。bilingual-tokenizer-training-data数据集应运而生,旨在为涵盖拉丁、阿拉伯、西里尔、埃塞俄比亚等多种文字体系的数十种语言提供大规模文本语料。该数据集由研究社区在近年构建,其核心研究问题聚焦于解决低资源语言在分词任务中数据稀缺的困境,通过整合多语言平行或可比语料,为开发跨语言分词模型奠定数据基础。这一资源对于推动语言技术在全球范围内的普惠应用具有显著影响力,尤其有助于提升机器翻译、信息检索等任务在非主流语言上的性能。
当前挑战
该数据集致力于应对多语言分词模型开发中的核心挑战,即如何为形态丰富或书写系统复杂的语言设计高效的分词策略。例如,阿拉伯语和希伯来语的连字现象、藏文和埃塞俄比亚文的独特字符分割,均对分词算法提出了严峻考验。在构建过程中,挑战同样突出:原始语料的收集需克服低资源语言数据稀缺与分布不均的障碍;文本清洗与标准化须处理不同编码体系与噪音干扰;数据划分与子集生成则需确保语言覆盖的平衡性与代表性,避免因数据偏差导致模型泛化能力下降。
常用场景
经典使用场景
在自然语言处理领域,多语言文本数据的处理一直是构建跨语言模型的核心挑战。该数据集通过整合涵盖拉丁、阿拉伯、西里尔等多种文字体系的数十种语言文本,为双语或多语言分词器的训练提供了标准化语料。其经典使用场景在于为研究者提供大规模、多样化的语言样本,用以训练能够同时处理多种语言的分词器,从而优化模型在跨语言任务中的词汇表示能力。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在多语言分词算法的创新与评估框架的构建。例如,研究者利用该数据集训练了支持数百种语言的分词器,如基于BPE和Unigram的混合模型,这些模型在跨语言基准测试中表现出色。同时,该数据集也催生了针对低资源语言分词效率的优化研究,以及多语言词表压缩技术的探索,为后续大规模多语言预训练模型的开发奠定了基础。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言模型的构建已成为推动全球语言技术普及的关键。bilingual-tokenizer-training-data数据集以其涵盖的丰富语言变体和文字系统,为跨语言分词器的训练提供了重要资源。当前研究聚焦于利用此类数据优化分词算法,以提升低资源语言的处理效能,尤其是在神经机器翻译和多语言预训练模型中实现更精准的语义对齐。随着全球数字包容性倡议的兴起,该数据集支持了语言技术民主化的前沿探索,助力消除语言障碍,促进文化多样性的技术融合。
以上内容由遇见数据集搜集并总结生成


