blimp-single-error
收藏Hugging Face2025-12-12 更新2025-12-13 收录
下载链接:
https://huggingface.co/datasets/liu-nlp/blimp-single-error
下载链接
链接失效反馈官方服务:
资源简介:
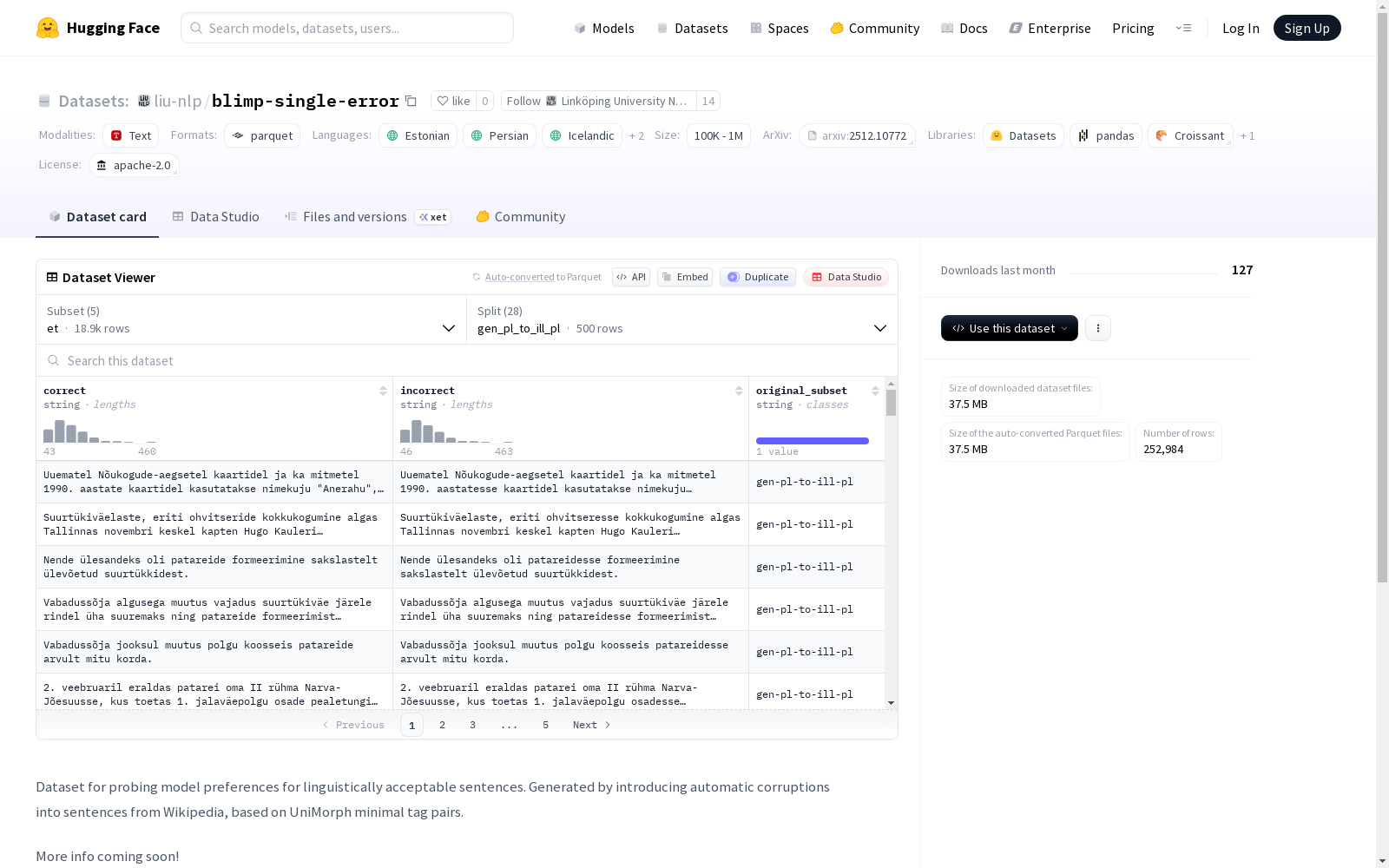
提供的README内容没有直接描述数据集。然而,根据配置名称(et、fa、fo、is、sv)和分割名称,可以推断该数据集包含多种语言(爱沙尼亚语、波斯语、法罗语、冰岛语、瑞典语)的语言学数据,重点关注语法转换,如格变化、动词人称变化以及名词和形容词的数变化。数据集包括这些转换的正确和错误形式,可能用于评估或训练语言模型的语法准确性。
The provided README does not directly describe the dataset. However, based on the configuration names (et, fa, fo, is, sv) and split names, it can be inferred that this dataset contains linguistic data in multiple languages (Estonian, Persian, Faroese, Icelandic, Swedish), focusing on grammatical transformations such as case inflection, verbal person conjugation, and number inflection of nouns and adjectives. The dataset includes both correct and incorrect forms of these transformations, which may be used for evaluating or training language models to improve their grammatical accuracy.
创建时间:
2025-12-04
原始信息汇总
数据集概述
基本信息
- 数据集名称: blimp-single-error
- 托管地址: https://huggingface.co/datasets/liu-nlp/blimp-single-error
- 配置数量: 5个
- 语言覆盖: 爱沙尼亚语 (et)、波斯语 (fa)、法罗语 (fo)、冰岛语 (is)、瑞典语 (sv)
数据结构
通用特征
所有配置均包含以下字段:
correct: 字符串类型,表示正确的句子。incorrect: 字符串类型,表示包含单一语法错误的句子。original_subset: 字符串类型,表示原始子集来源。
特定特征
- 法罗语 (fo) 和冰岛语 (is) 配置额外包含:
original_split: 字符串类型,表示原始分割信息。
配置详情
1. 爱沙尼亚语 (et)
- 下载大小: 3,677,743 字节
- 数据集大小: 5,715,074 字节
- 分割数量: 27个
- 示例总数: 12,462个
- 主要分割类型:
- 格转换:属格、部分格、向格、主格之间的相互转换。
- 动词人称转换:现在时和过去时下第三人称与第一、二人称的转换。
- 数转换:单复数名词的格转换。
2. 波斯语 (fa)
- 下载大小: 7,147,530 字节
- 数据集大小: 15,331,797 字节
- 分割数量: 8个
- 示例总数: 23,993个
- 主要分割类型:
- 动词人称转换:第一、二、三人称之间的相互转换。
- 动词数转换:单复数动词形式之间的转换。
3. 法罗语 (fo)
- 下载大小: 9,950,183 字节
- 数据集大小: 26,392,819 字节
- 分割数量: 38个
- 示例总数: 67,428个
- 主要分割类型:
- 名词转换:涉及格(宾格、与格、属格、主格)、定指性、数的转换。
- 动词转换:涉及人称和数的转换。
- 形容词转换:涉及格、性(阴性、阳性)、数的转换。
4. 冰岛语 (is)
- 下载大小: 11,472,547 字节
- 数据集大小: 33,033,963 字节
- 分割数量: 24个
- 示例总数: 62,919个
- 主要分割类型:
- 名词转换:涉及格(宾格、与格、属格、主格)、定指性、数的转换。
- 动词转换:涉及人称、数、语气(直陈式、虚拟式)的转换。
5. 瑞典语 (sv)
- 下载大小: 5,237,235 字节
- 数据集大小: 15,082,330 字节
- 分割数量: 10个
- 示例总数: 36,154个
- 主要分割类型:
- 动词形式转换:非限定形式与限定形式之间的转换。
- 语态转换:主动语态与被动语态之间的转换。
- 形容词转换:涉及性(中性、阳阴通用)和数的转换。
- 名词定指性转换:定指与不定指之间的转换。
数据文件组织
每个配置的数据文件均按分割名称组织在对应的语言目录下,路径模式为:{config_name}/{split_name}-*。
搜集汇总
数据集介绍
构建方式
在语言学评估领域,blimp-single-error数据集通过系统化地引入语法变异来构建。该数据集涵盖爱沙尼亚语、波斯语、法罗语、冰岛语和瑞典语五种语言,每个语言配置下均包含大量语法转换对。构建过程基于语言学规则,针对名词格、动词人称、数等语法范畴,生成正确与错误句子的配对,从而形成精细的语法错误检测基准。
使用方法
使用该数据集时,研究人员可通过HuggingFace数据集库直接加载特定语言配置,如`load_dataset('blimp-single-error', 'et')`。每个子集可独立用于评估模型对特定语法错误的敏感性,通过对比正确与错误句子的模型输出,量化语法理解能力。该数据集适用于多语言语法评估、模型对比分析及错误类型诊断等研究场景。
背景与挑战
背景概述
在自然语言处理领域,语法判断任务对于评估语言模型的语言能力至关重要。blimp-single-error数据集作为BLIMP基准的扩展,由研究人员于2020年左右构建,旨在系统性地评估模型对多种语言中特定语法错误的敏感性。该数据集覆盖爱沙尼亚语、波斯语、法罗语、冰岛语和瑞典语等语言,通过对比正确与错误的句子对,深入探究模型在形态句法层面的理解能力。其核心研究问题聚焦于跨语言语法一致性的建模,为多语言NLP研究提供了宝贵的评估资源,推动了语言模型在低资源语言上的性能分析。
当前挑战
该数据集致力于解决跨语言语法错误检测的挑战,其核心问题在于模型能否准确识别细微的形态句法偏差,如格、数、人称等语法范畴的错误。构建过程中的挑战包括:首先,为低资源语言设计系统性的错误模式需要深厚的语言学专业知识,确保错误类型的代表性与自然性;其次,数据收集需平衡不同语言变体的覆盖范围,避免因语料稀缺导致的数据偏差;最后,标注一致性在多语言环境下难以维持,需克服语言特异性带来的标注歧义。
常用场景
经典使用场景
在计算语言学领域,BLIMP-single-error数据集被广泛用于评估语言模型对形态句法知识的掌握程度。该数据集精心构建了多种语言中名词、动词和形容词的形态变化对,例如格、数、人称等单一错误对比,为研究者提供了一个系统性的基准测试平台。通过让模型区分正确与错误的句子,能够深入探究模型是否真正理解语言的细微语法规则,而非仅仅依赖统计模式。
解决学术问题
该数据集有效解决了语言模型评估中形态句法知识量化不足的学术难题。传统评估往往侧重于整体性能,难以精准诊断模型在特定语法范畴上的缺陷。BLIMP-single-error通过控制变量,隔离出单一的形态错误,使得研究者能够精确测量模型对格标记、一致关系等核心语法概念的敏感性。其意义在于推动了模型诊断从黑箱走向透明,为理解神经网络的内部语言表征提供了关键数据支撑。
实际应用
在实际应用中,BLIMP-single-error数据集为多语言语法检查器和智能写作辅助工具的研发提供了重要基准。通过利用该数据集训练或评估模型,可以显著提升系统在爱沙尼亚语、波斯语、法罗语等语言中检测和纠正形态错误的能力。这对于构建高质量的机器翻译系统、语言学习应用以及面向低资源语言的自动化文本处理工具具有直接的应用价值,促进了语言技术的包容性发展。
数据集最近研究
最新研究方向
在自然语言处理领域,语法评估数据集对于模型的语言理解能力至关重要。blimp-single-error数据集聚焦于多语言语法错误检测,涵盖爱沙尼亚语、波斯语、法罗语、冰岛语和瑞典语等低资源语言,其最新研究方向正围绕跨语言语法泛化能力展开。随着多语言大模型的兴起,该数据集被广泛用于探究模型在形态句法层面的迁移学习效果,特别是在名词格变、动词人称和数的一致性等复杂语法现象上的表现。近期研究热点包括利用该数据集评估模型在低资源语言上的零样本或少样本学习能力,以及探索语法错误纠正任务中的跨语言知识迁移机制。这些工作不仅推动了多语言模型的语法敏感性提升,也为构建更具包容性的语言技术提供了实证基础,对促进语言多样性保护具有深远意义。
以上内容由遇见数据集搜集并总结生成


