CG-Bench
收藏arXiv2024-12-17 更新2024-12-18 收录
下载链接:
https://cg-bench.github.io/leaderboard/
下载链接
链接失效反馈官方服务:
资源简介:
CG-Bench是一个专门为长视频理解设计的线索导向问答基准数据集,由南京大学、上海人工智能实验室等机构创建。该数据集包含1219个精心筛选的长视频,分为14个主要类别、171个次级类别和638个三级类别,共有12,129个问答对,涵盖感知、推理和幻觉三种主要问题类型。数据集的创建过程包括视频收集、问答线索标注和质量审查迭代,确保了数据集的高质量和多样性。CG-Bench旨在评估多模态大语言模型在长视频理解中的表现,特别是模型是否能够基于视频中的线索生成正确答案,从而推动更可靠和高效的多模态模型的发展。
CG-Bench is a clue-oriented question answering benchmark dataset specifically designed for long-form video understanding, developed by institutions including Nanjing University and Shanghai AI Laboratory. This dataset comprises 1219 carefully curated long videos, which are classified into 14 primary categories, 171 secondary categories and 638 tertiary categories, with a total of 12,129 question-answer pairs covering three main question types: perception, reasoning and hallucination. The dataset construction process includes video collection, question-answering clue annotation and iterative quality review, which ensures the high quality and diversity of the dataset. CG-Bench aims to evaluate the performance of multimodal large language models in long-form video understanding, particularly whether the models can generate accurate answers based on the clues in the videos, thereby advancing the development of more reliable and efficient multimodal models.
提供机构:
南京大学, 上海人工智能实验室, 复旦大学, 浙江大学
创建时间:
2024-12-17
搜集汇总
数据集介绍
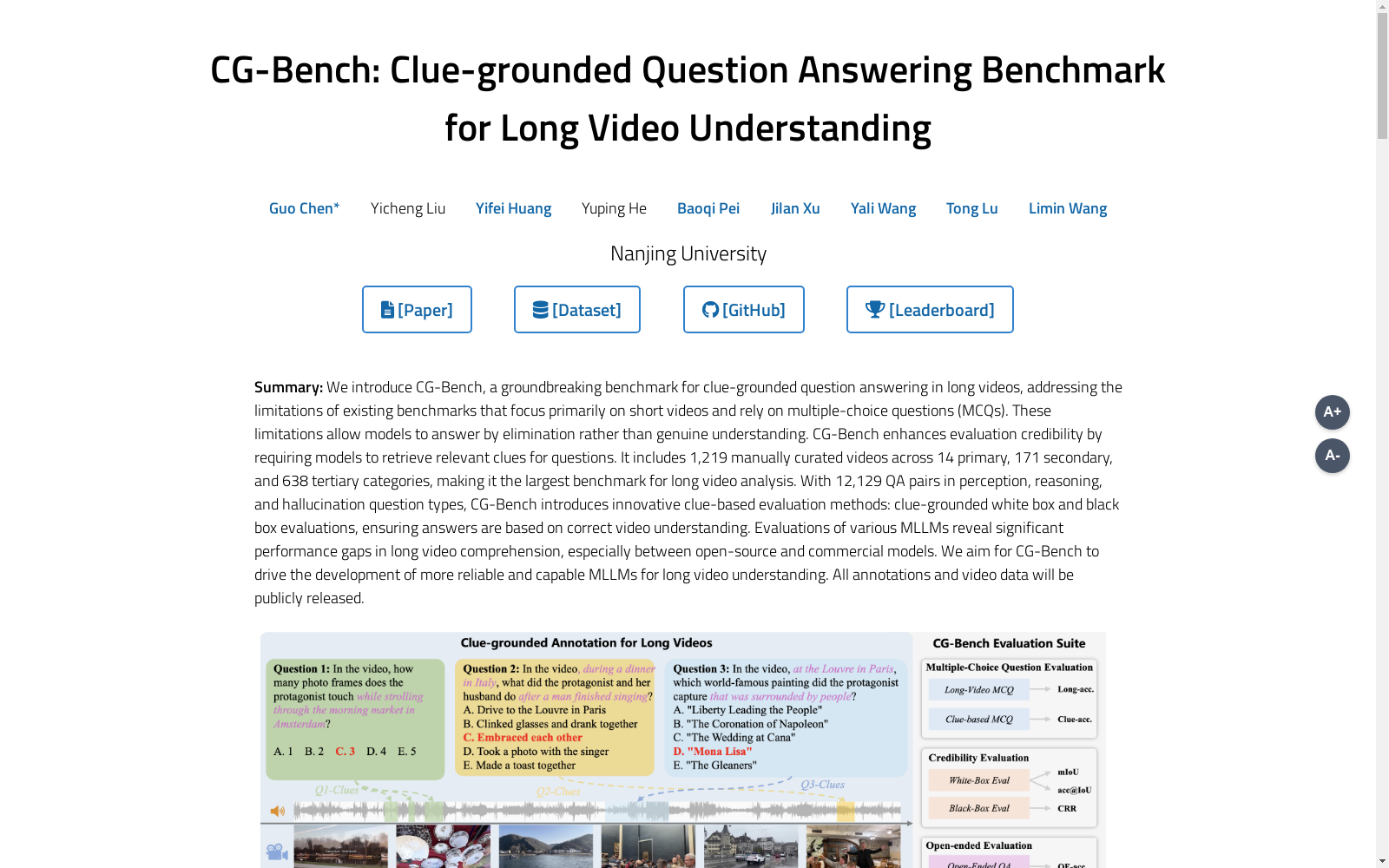
构建方式
CG-Bench数据集的构建过程包括三个主要步骤:视频收集、问题-答案-线索(QAC)标注和质量审查迭代。首先,通过手动从互联网收集视频,确保这些视频未被现有多模态大语言模型(MLLMs)用于预训练,并对其进行新的标注。视频收集过程中,定义了14个根域,并为每个视频分配简短的标签以确保多样性。其次,对收集到的视频进行高质量的QAC三元组标注,确保问题多样性,并建立了一个包含感知、推理和幻觉三大类问题的分类体系。最后,通过多轮质量审查迭代,确保标注的合理性和视频依赖性,过滤掉不符合质量标准的标注。
特点
CG-Bench数据集具有显著的特点,包括1,219个精心挑选的长视频,涵盖14个主要类别、171个次级类别和638个三级类别,使其成为最大的长视频分析基准。该数据集包含12,129个QA对,分为感知、推理和幻觉三大类问题,并设计了两种新颖的线索评估方法:线索导向的白盒评估和黑盒评估,以确保模型基于视频内容的正确理解生成答案。此外,CG-Bench还支持开放式问题评估,进一步提升了评估的全面性和可靠性。
使用方法
CG-Bench数据集的使用方法主要包括多选题评估、可信度评估和开放式问题评估。在多选题评估中,模型需要根据视频内容选择正确答案,分为长视频多选题和线索导向的多选题两种设置。可信度评估则通过白盒和黑盒评估方法,检验模型是否基于正确的视频线索生成答案。开放式问题评估则通过低幻觉的多模态大语言模型(如GPT-4o)进行,结合预标注的时间间隔和视觉线索,减少幻觉错误并降低评估成本。这些评估方法共同构成了对模型在长视频理解能力上的全面检验。
背景与挑战
背景概述
CG-Bench是由南京大学、上海人工智能实验室等机构的研究人员共同开发的一个专注于长视频理解的多模态大语言模型(MLLM)基准数据集。该数据集于2024年发布,旨在填补现有视频理解基准集中对长视频(≥10分钟)理解的不足。CG-Bench通过引入线索导向的问题回答机制,强调模型在回答问题时必须基于视频中的相关线索,从而提升评估的可信度。数据集包含了1,219个精心挑选的长视频,分为14个主类别、171个次类别和638个三级类别,涵盖了12,129个问题-答案-线索(QAC)三元组,涉及感知、推理和幻觉三种主要问题类型。CG-Bench的推出为长视频理解领域提供了新的评估标准,推动了多模态大语言模型在长视频理解中的应用和发展。
当前挑战
CG-Bench面临的主要挑战包括:首先,长视频理解相较于短视频理解更具复杂性,模型需要在长视频中准确提取相关线索,而非依赖于简单的排除法或常识推理。其次,构建过程中,研究人员需要手动标注大量的视频内容,确保问题、答案和线索之间的关联性,这不仅耗时且成本高昂。此外,现有的多模态大语言模型在长视频理解任务中表现不佳,尤其是在线索导向的评估中,模型的准确性和可信度显著下降。最后,长视频的复杂性和多样性使得模型在处理不同类型的视频内容时面临较大的挑战,尤其是在处理长尾视频时,模型的表现往往不尽如人意。
常用场景
经典使用场景
CG-Bench 数据集的经典使用场景主要集中在长视频理解任务中,特别是针对多模态大语言模型(MLLMs)的评估。该数据集通过提供1,219个精心挑选的长视频和12,129个问答对,涵盖了感知、推理和幻觉三种主要问题类型,帮助模型在长视频中进行线索检索和问题回答。通过设计线索基础的白盒和黑盒评估方法,CG-Bench 能够有效评估模型是否基于视频中的正确线索生成答案,从而提升评估的可信度。
实际应用
CG-Bench 数据集在实际应用中具有广泛的应用场景。首先,它在视频内容分析领域中具有重要价值,特别是在需要对长视频进行深入理解的场景,如电影分析、纪录片研究等。其次,该数据集可用于开发智能视频推荐系统,通过理解长视频中的复杂内容,为用户提供更精准的推荐。此外,CG-Bench 还可应用于教育领域,帮助开发基于长视频的智能教学工具,提升学生的学习体验。
衍生相关工作
CG-Bench 数据集的发布催生了一系列相关研究工作。首先,许多研究者基于该数据集开发了新的多模态大语言模型,旨在提升长视频理解能力。其次,CG-Bench 的线索基础评估方法启发了其他研究者在视频理解任务中引入类似的评估机制,推动了视频理解评估方法的创新。此外,该数据集还促进了长视频内容分析工具的开发,为视频内容的自动化分析提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


