WHODUNIT
收藏arXiv2025-02-12 更新2025-02-13 收录
下载链接:
https://huggingface.co/datasets/kjgpta/WhoDunIt
下载链接
链接失效反馈官方服务:
资源简介:
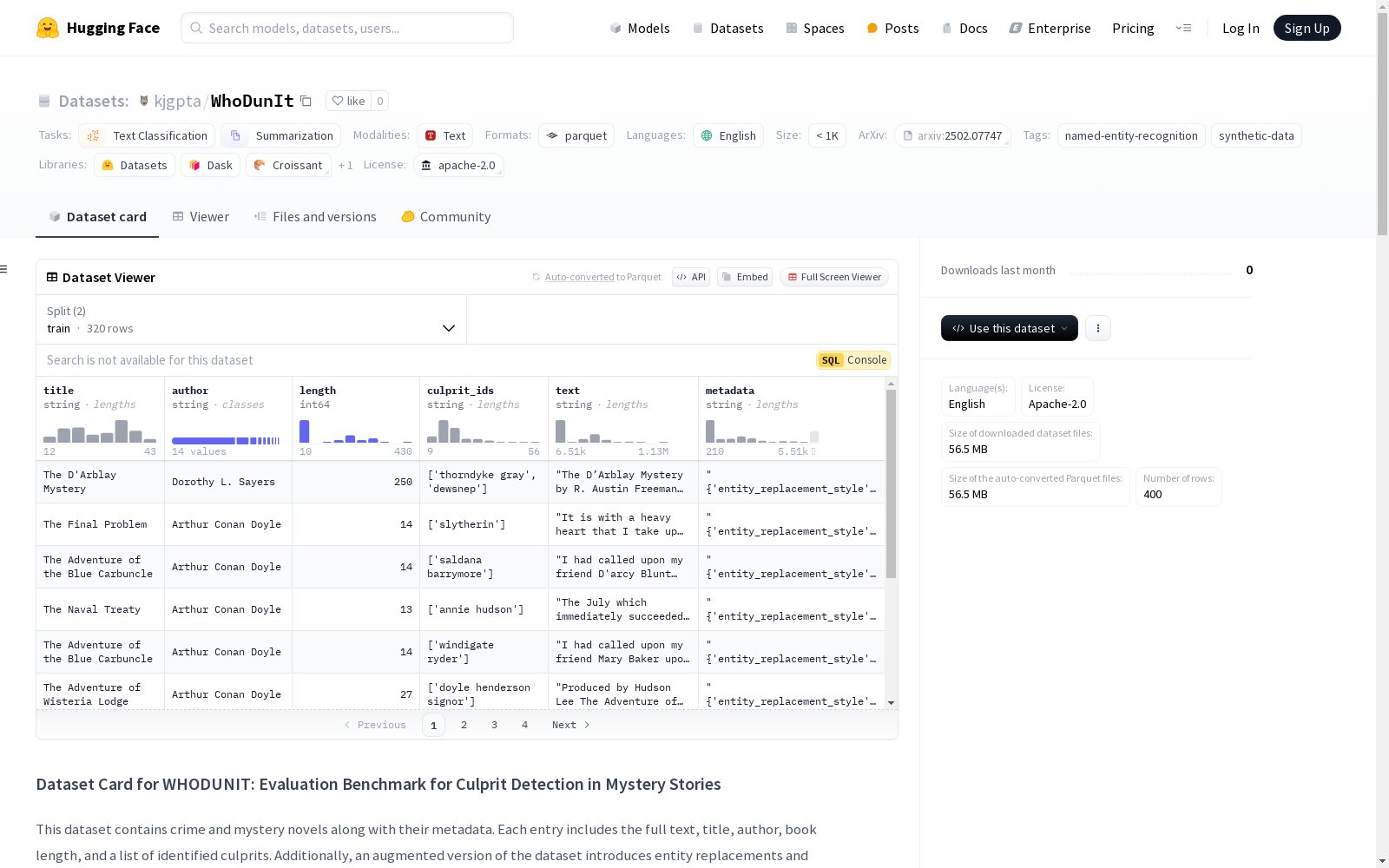
WHODUNIT数据集由BITS Pilani的研究人员构建,旨在评估大型语言模型在叙事背景下的推理能力。该数据集由公开领域的侦探和悬疑小说组成,挑战模型在阅读故事后识别犯罪者。数据集通过不同的角色命名增广,如原名、名字交换、以及替换为知名实体等,来评估模型的鲁棒性。数据集涵盖了不同作者和叙事风格的作品,保证了叙事结构和推理风格的多样性,适用于推理和长篇叙事理解的任务。
The WHODUNIT dataset was constructed by researchers from BITS Pilani, with the aim of evaluating the reasoning capabilities of large language models in narrative contexts. This dataset consists of detective and mystery novels from the public domain, challenging models to identify the perpetrator after reading the full story. The dataset is augmented via multiple character naming strategies, including original names, name swaps, and replacement with well-known entities, to assess model robustness. It covers works from different authors with diverse narrative styles, ensuring variety in narrative structures and reasoning patterns, making it applicable to tasks related to reasoning and long-form narrative comprehension.
提供机构:
BITS Pilani
创建时间:
2025-02-12
搜集汇总
数据集介绍
构建方式
WHODUNIT数据集的构建主要基于公共领域的侦探小说和短篇故事,包括经典的作品如阿加莎·克里斯蒂的侦探小说。数据集涵盖了不同长度和风格的作品,确保了模型的叙事理解和推理能力的评估具有广泛性。通过从故事中提取犯罪嫌疑人的身份作为标签,并采用不同的人物名称替换方法来增加推理难度,数据集旨在挑战大型语言模型在叙事背景下的演绎推理能力。
特点
WHODUNIT数据集的特点在于其丰富的叙事背景和推理难度。它包含了不同作者和叙事风格的作品,提供了多样化的推理场景。数据集中的故事长度不一,从短篇到长篇都有涉及,这有助于评估模型对长文本的处理能力。此外,通过对人物名称进行替换,数据集进一步增加了模型推理的复杂性,要求模型不仅识别出知名的虚构人物,还能在名称改变的情况下进行准确的推理。
使用方法
使用WHODUNIT数据集时,研究人员可以采用不同的模型架构和提示方法来评估模型的演绎推理能力。数据集提供了多种推理难度级别的文本,研究人员可以根据需要选择合适的文本进行训练和测试。此外,数据集还支持对模型性能的多次评估,以确保结果的稳定性和准确性。
背景与挑战
背景概述
WHODUNIT数据集是由 BITS Pilani 的 Kshitij Gupta 等人创建的,旨在评估大型语言模型在叙事背景下的演绎推理能力。该数据集由公开领域的侦探小说和短篇故事构成,挑战模型在阅读并理解故事后识别出罪犯的能力。WHODUNIT 数据集的创建灵感来源于 Ilya Sutskever 和 Jensen Huang 的一次访谈,讨论了 '下一个词预测' 是否足以理解故事内容。该数据集涵盖了多种叙事风格和作者,包括阿加莎·克里斯蒂等人的作品,确保了模型的泛化能力和对不同叙事结构的处理能力。
当前挑战
WHODUNIT 数据集相关的挑战主要包括:1)模型在处理未更改的文本时表现可靠,但在某些名字替换的情况下,准确性下降,特别是对于那些广为人知的人物名称;2)构建过程中遇到了如何确保故事中的角色名称不会影响模型推理的问题,因此采用了不同级别的名称替换,如完全交换所有角色名称、用哈利·波特系列人物名称替换等,以评估模型对上下文理解和角色关系的依赖程度;3)此外,模型在处理长篇叙事时的挑战也较为明显,需要构建能够测试模型在长篇故事中的推理能力的综合谜题数据集。
常用场景
经典使用场景
WHODUNIT数据集的经典使用场景在于评估大型语言模型在叙事背景下的推理能力,特别是针对悬疑故事中的犯罪侦破。该数据集通过让模型阅读并理解公开领域的悬疑小说和短篇故事,挑战其识别故事中犯罪嫌疑人的能力。
实际应用
在实际应用中,WHODUNIT数据集可用于训练和评估面向悬疑故事解析的推理系统,如自动侦探助手、故事情节分析工具等,为内容创作、情报分析和教育娱乐等领域提供技术支持。
衍生相关工作
基于WHODUNIT数据集,研究者可以进一步开展相关的工作,如开发更加精细化的推理模型、探索模型在多语言环境下的表现、以及将推理能力应用于其他类型的叙事文本分析。
以上内容由遇见数据集搜集并总结生成


